在ViT、MLP-Mixer等进行4800多次实验,谷歌发现大规模预训练存在瓶颈
视学算法报道
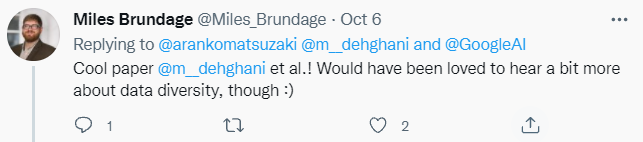
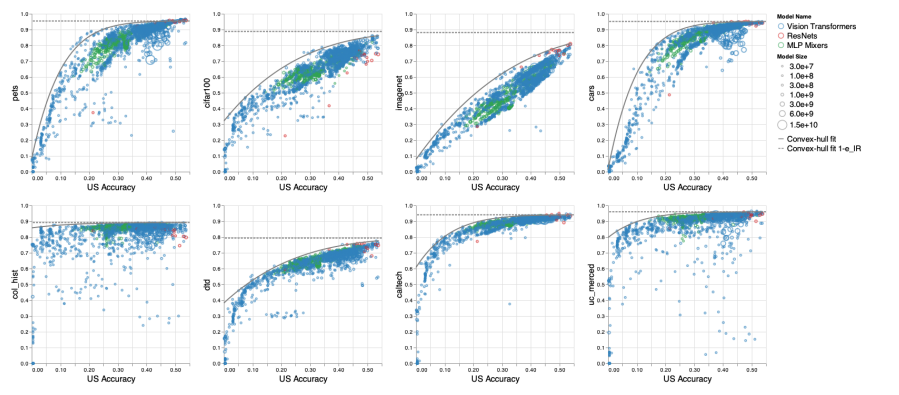
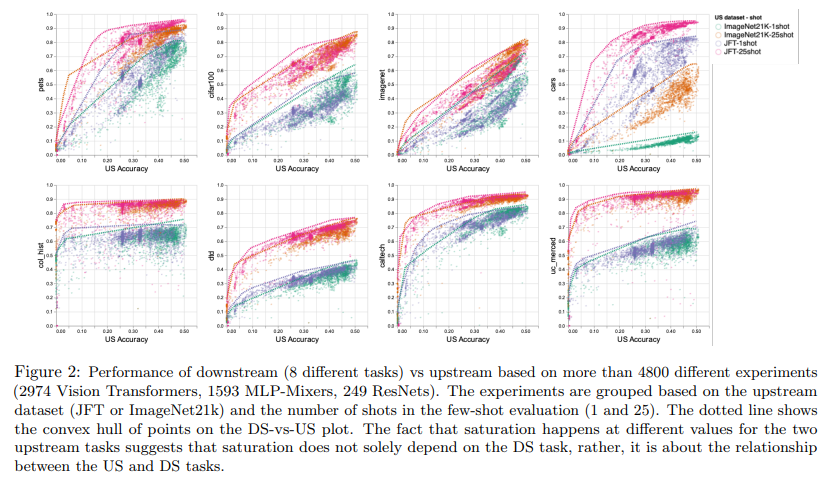
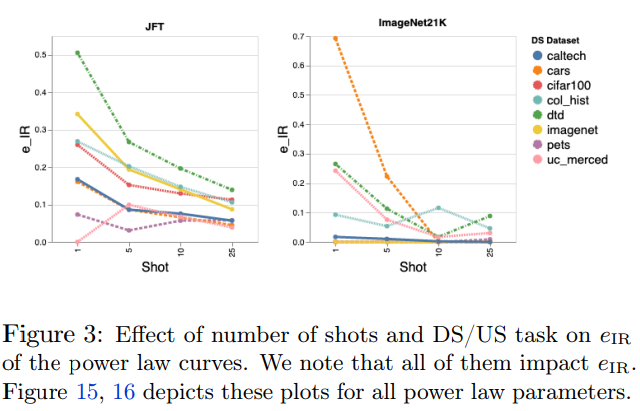
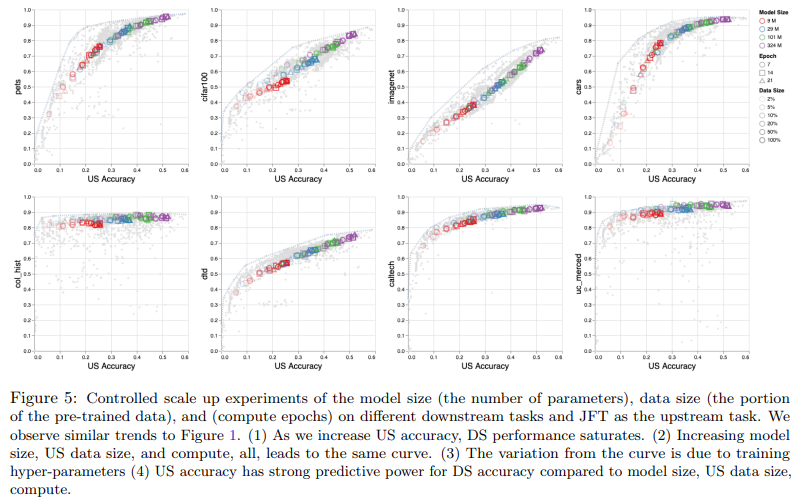
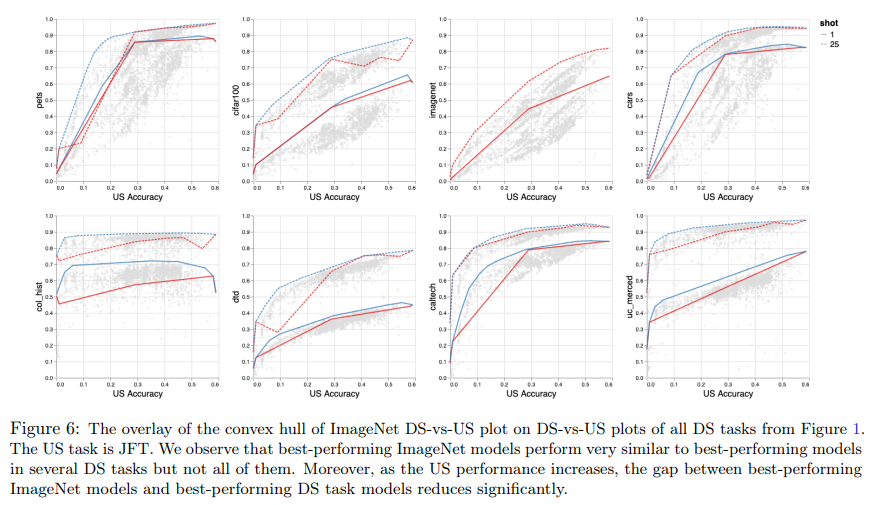
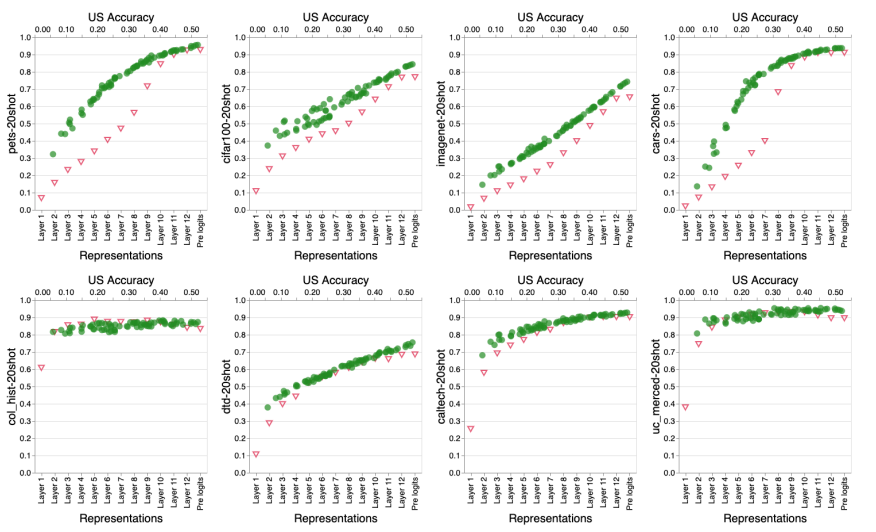
大规模预训练模型在各种任务上取得了不错的性能,但是也存在一些限制。来自谷歌的研究者系统地研究了大规模预训练模型在图像识别任务中扩大数据、增加模型大小和训练时间对各种下游任务的影响,并查明限制、原因,以提供指导。

© THE END
转载请联系原公众号获得授权
投稿或寻求报道:content@jiqizhixin.com

点个在看 paper不断!
评论
 下载APP
下载APP视学算法报道
大规模预训练模型在各种任务上取得了不错的性能,但是也存在一些限制。来自谷歌的研究者系统地研究了大规模预训练模型在图像识别任务中扩大数据、增加模型大小和训练时间对各种下游任务的影响,并查明限制、原因,以提供指导。
© THE END
转载请联系原公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
点个在看 paper不断!