
ICDE2021 | 利用大规模知识图谱预训练改进对话推荐系统

接收会议:ICDE2021 (International Conference on Data Engineering)
论文链接:https://arxiv.org/abs/2104.14899
欢迎转载,转载请注明出处
一、模型简介
本文首先从用户、项目和会话的信息中构造出一个十亿规模的会话知识图谱(Conversation Knowledge Graph, CKG),然后引入知识图谱嵌入方法和图卷积网络对会话知识图谱进行预训练,分别对语义信息和结构信息进行编码。为了使会话推荐系统预测模型能够感知用户的当前状态以及对话和项目之间的关系,引入了基于预训练会话知识图谱的用户状态和对话交互表示,并提出了K-DCN模型。在K-DCN模型中,通过深度交叉网络融合用户状态表示、对话交互表示和其他常规特征表示,从而给出候选项的推荐等级。
传统的会话推荐系统(Conversational Recommender Systems, CRSs)主要关注于点击率(Click-Through Rate,CTR),多个相关模型都进行了实验验证并取得了良好的效果。但是这些模型主要依赖于用户对商品的丰富行为记录,而在电商平台真实场景,用户与只能聊天机器人的交互有限,导致这类数据往往非常稀少,最终导致模型产生过拟合问题。
因此本文提出的K-DCN模型主要解决样本较少和数据稀疏的问题,模型将用户、商品和会话信息考虑在内,因为用户的会话中可能会表达用户本人对某种商品的某种偏好。
二、模型细节
这篇文章提出的方法包括两部分:第一,会话知识图谱的构建和预训练,对结构和语义信息进行编码;第二,基于常规特征和预训练好的知识图谱表示特征对知识增强的深交叉网络K-DCN模型进行微调,其中包括用户状态表示和对话交互表示。
(一)会话知识图谱的构建与预训练
这篇论文中,将知识图谱作为一种编码与会话推荐系统相关的各种信息的方法,并从用户与聊天机器人会话的真实场景中构造会话知识图谱。
会话知识图谱中包含一下三种信息:
(1)关于用户的信息:每个用户都有一个标签列表,例如性别、购物历史等,这有助于抓住用户的兴趣。基于这些数据,以(user, has, user_tag)这样的三元组形式对会话知识图谱中的标签信息进行编码。
(2)商品信息:平台包含丰富的商品信息,如商品的类别和卖家,以及商品的属性如颜色、品牌等。对于类别和卖家信息,分别以(item, belong_to, category)和(seller, has, item)的形式构建了三元组;而对于属性和值,构建了两种类型的三元组(item,has,value)和(property,has,value)。这些信息可以极大地帮助映射和挖掘用户的兴趣。
(3)会话信息:在聊天机器人中,用户与机器人聊天时会创建许多会话,会话中的意图和关键字有助于更准确地理解用户的意图。因此可以根据会话历史构建四种类型的三元组:(user,created,session),(session,relate to,seller),(session,has,intention)和(intention,has,keywords)。
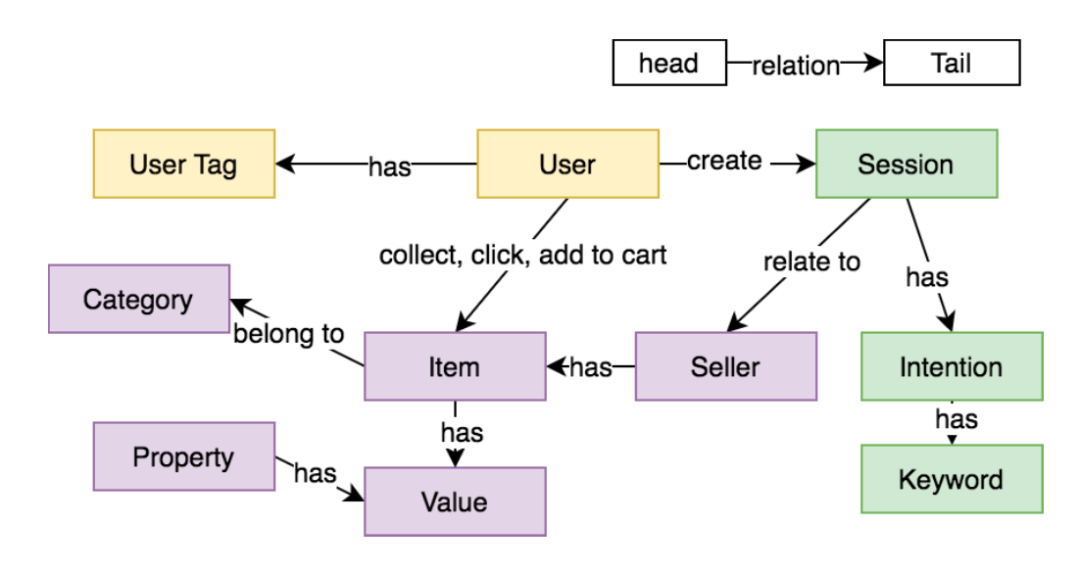
图1 会话知识图谱
会话知识图谱的模式如图1所示。最后构造的会话知识图谱中,包含了6亿个实体和60亿个三元组。
众所周知,结构信息和语义信息在知识图谱中都是极有价值的,因此会话知识图谱预训练包含结构嵌入模块和语义嵌入模块两个模块。
(1)结构嵌入模块:图形神经网络(GNN)及其衍生模型已被证明可用于编码结构信息,本文利用GCN模型来学习会话知识图谱中实体的表示向量,并可以表示为
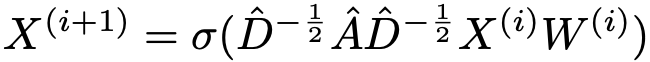
其中
(2)语义嵌入模块:知识图谱嵌入(knowledge Graph Embedding,KGE)方法能够对语义信息进行隐式编码,在本文中采用TransE模型。对于三元组
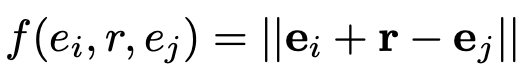
其中这些加粗字母都是其对应实体和关系嵌入向量表示。
(3)预训练:模型通过联合训练结构嵌入模块和语义嵌入模块来学习实体和关系嵌入。在协同训练过程中,将多层GCN模型的输出作为TransE的实体嵌入矩阵,即
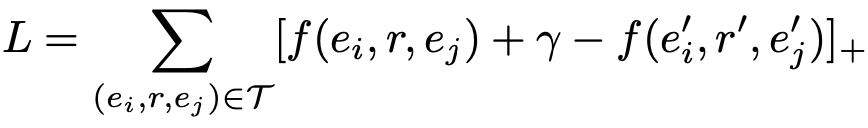
其中
(二)K-DCN模型微调
在点击率预测模型中,通常使用常见的稀疏和密集特征,而在会话推荐系统中用户对聊天机器人的即时提问对于理解用户的意图也很重要。因此本文考虑构建基于预训练会话知识图谱的用户状态和对话交互表示作为附加特征。
用户的状态可以被他们以前的行为捕获。对于一个用户,假设他在电商平台上有k个操作行为并表示为
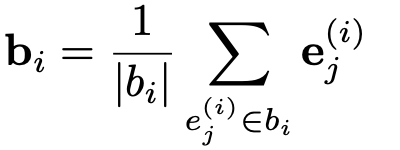
在垂直方向上将这些行为向量行为矩阵连接为
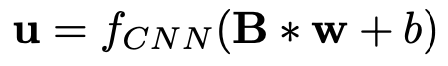
其中∗是卷积算子,
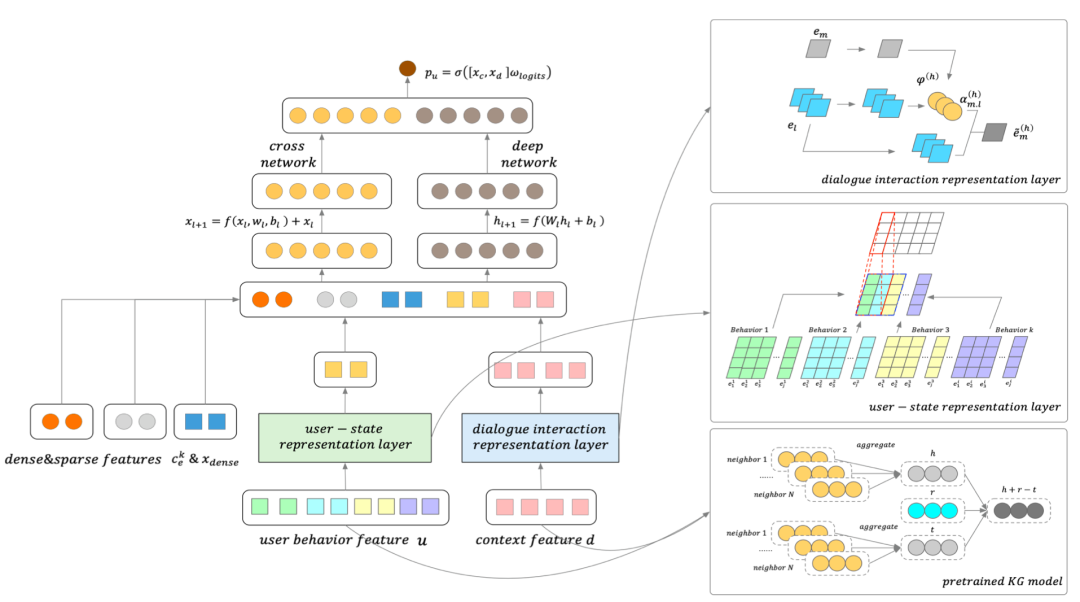
图2 知识增强型深度交叉网络(K-DCN)的体系结构
2. 对话交互表示
为了建立对话交互,首先从用户中提取一组关键字
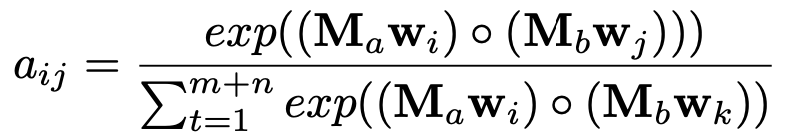
其中
接下来,我们根据上述的
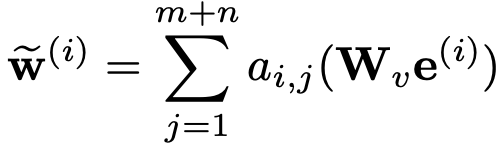
最后,我们将所有更新的单词嵌入连接起来作为对话交互表示向量
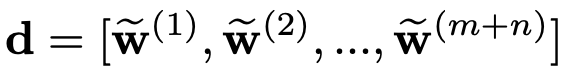
3. K-DCN模型
K-DCN模型的输入是候选商品e的不同特征表示向量。除了上述用户状态(user-state)和对话(dialogue)交互表示向量
首先将所有特征向量连接起来,如下所示:
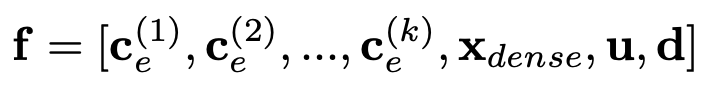
其中
利用上述的商品特征表示
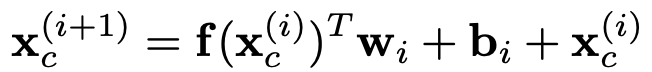
式中
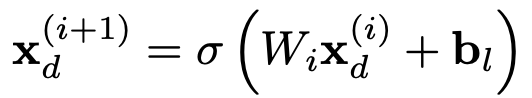
然后将上述两个网络的两个输出连接起来,并将连接的向量送入标准logits层,可以记为:
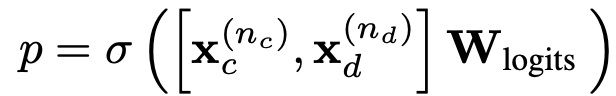
为了训练K-DCN模型,需要将以下对数似然损失函数最小化:
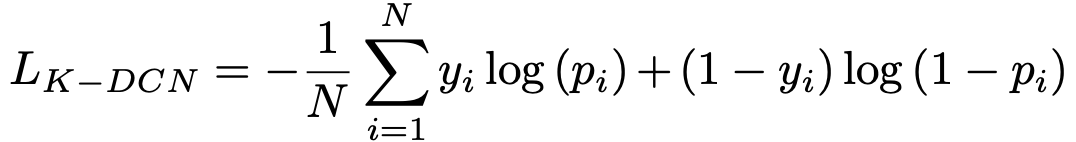
三、数据和实验
1. 数据集
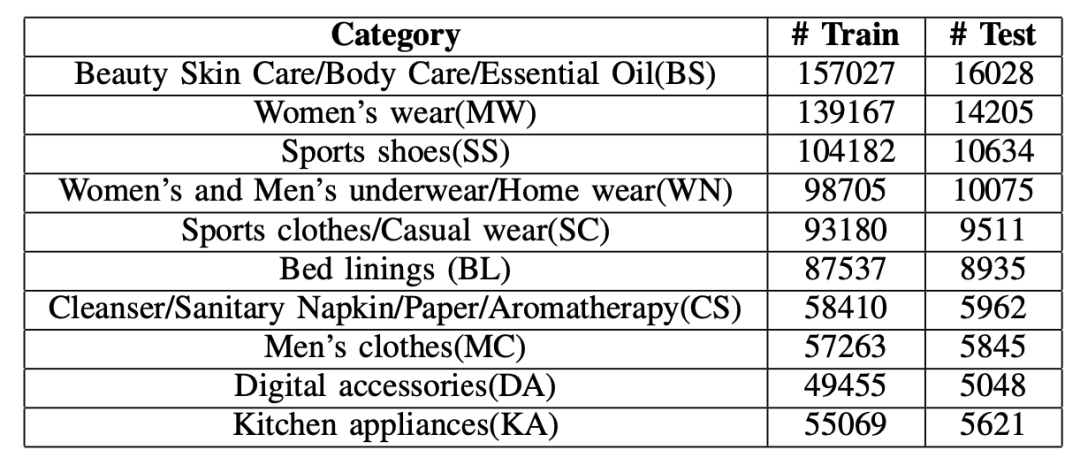
K-DCN模型是在本文作者构建的私有数据集上从头开始进行预训练和微调的。这些数据集来自阿里电商客服机器人的对话,包含了从十个类别中取样了九十万条记录数据,如表1所示。而预训练会话知识图谱模型是基于十亿规模的知识图谱进行训练的,其中包含五亿个实体和六十亿个三元组。
2. 实验结果
本文中将K-DCN模型与5个基线模型进行了比较,包括深度交叉网络(Deep & Cross Network,DCN)、广度深度网络(Wide & Deep Network,WDN)、深度神经网络(Deep Neural Network,DNN)、梯度增强决策树(Gradient Boosted Decision Trees,GBDT)和逻辑回归(Logistic Regression,LR),结果如表2所示。从表格数据中可以看出,本文中提出的K-DCN模型在所有的数据集中都优于所有的基线模型。
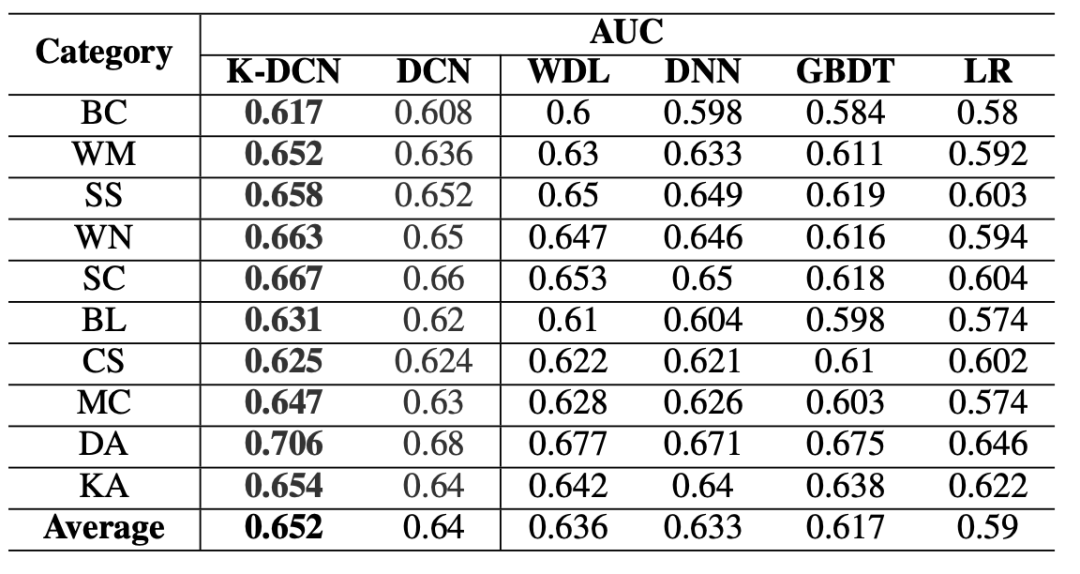
表2 K-DCN模型和5个基线模型在10个不同数据集上的实验结果
具体来说,K-DCN模型在数字配件(digital accessories)类别中的得分更高,分值为2.6%,主要原因是数字配件类的训练数据量非常有限,验证了基于会话知识图谱预训练的模型可以缓解数据匮乏的问题。对于所有的数据集,K-DCN模型平均提高了1.2%,验证了本文提出的基于会话知识图谱嵌入方法能够为点击率预测模型提供有意义的结构和语义信息。从图3中可以看出,当使用预训练知识图谱嵌入方法来初始化点击率预测模型时,它也会加速收敛。
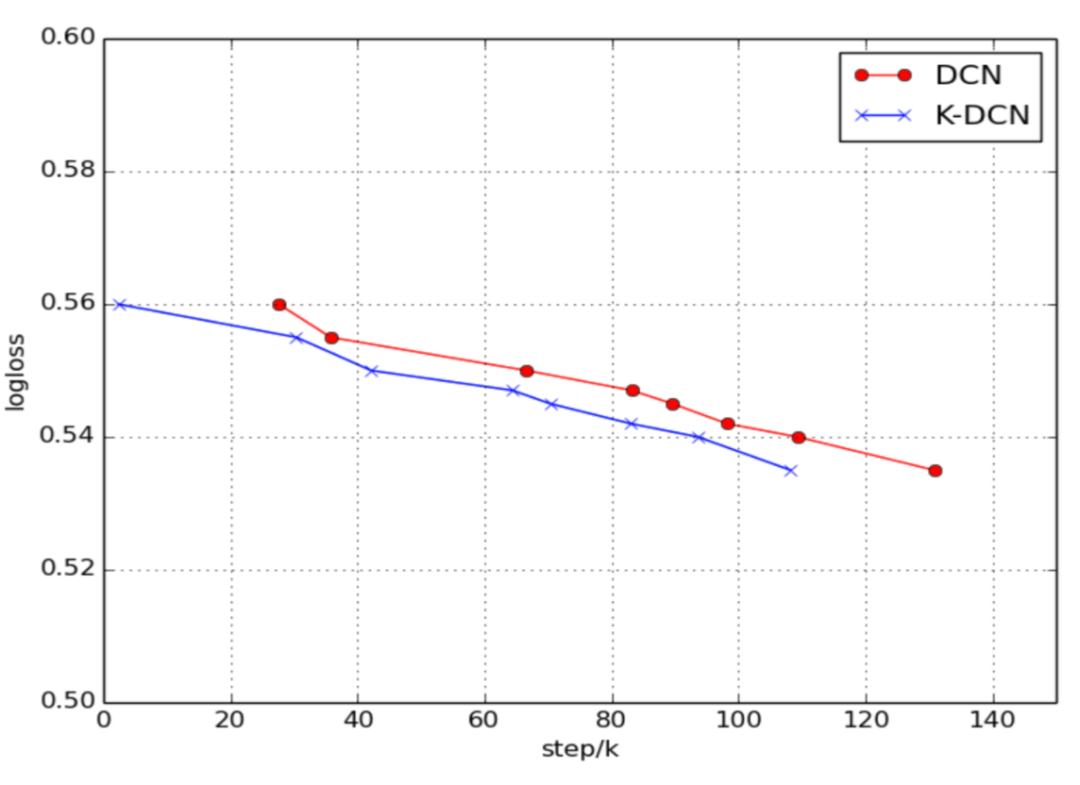
图3 K-DCN模型与DCN模型的收敛速度比较

浙江大学知识引擎实验室