
计算机视觉新手指南
通过机器的眼睛看
通过计算机或手机等机器观察周围环境的方法称为计算机视觉。模拟人眼的严峻工作可以追溯到50年代,我们已经在这个领域走了很长一段路。计算机视觉已经通过不同的电子商务或相机应用进入到了我们的手机。
当机器拥有像人一样的眼睛,机器将会做更多的事情。人眼有着复杂的结构,而通过眼睛观察来理解环境是一个更加复杂的现象。以类似的方式,使机器能够看到事物并使其具有足够的能力以理解它们所看到的内容并进一步对其进行分类,仍然是一项艰巨的工作。
使用计算机视觉等效于眨眼间就可以进行数百万次计算,其准确性几乎与人眼相同。这不仅涉及将图片转换为像素,然后尝试通过这些像素了解图片中的内容,也将不得不首先了解如何从这些像素中提取信息并了解其代表的内容。
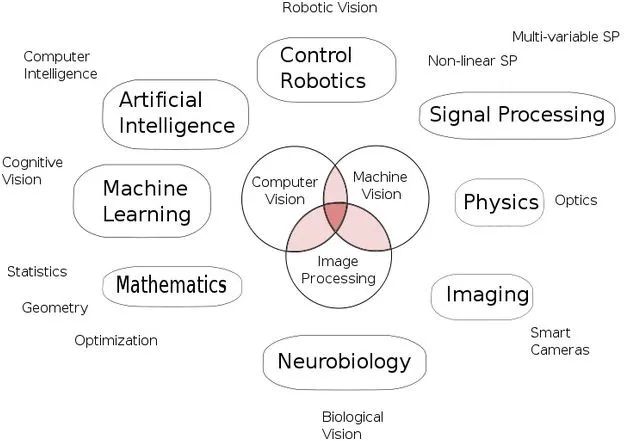
1、理解如何通过机器看
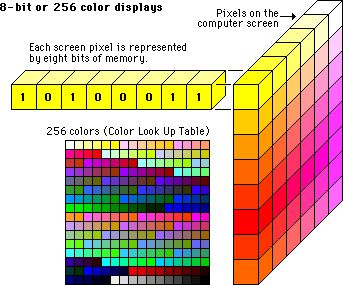
A.用数字表示颜色:在计算机科学中,每种颜色都由指定的十六进制值表示。这就是机器理解图像像素组成颜色的一种编码方式。而作为人类,我们拥有能力根据深浅来区分不同的颜色。
B.图像分割:计算机被用来识别相似的颜色组,然后分割图像,即将前景与背景区分开。颜色渐变技术用于查找不同对象的边缘。
 C.查找角点:分割后,然后查找图像中的某些特定的特征,也可被称为角点。简而言之,算法会搜索以一定角度相交的线,并以一种颜色的阴影覆盖图像的特定部分。特征(也称为角点)像是积木,可帮助查找图像中包含的更详细的信息。
C.查找角点:分割后,然后查找图像中的某些特定的特征,也可被称为角点。简而言之,算法会搜索以一定角度相交的线,并以一种颜色的阴影覆盖图像的特定部分。特征(也称为角点)像是积木,可帮助查找图像中包含的更详细的信息。
 D.查找纹理:正确识别图像的另一个重要方面是区分图像中的纹理。两个对象之间的纹理差异使机器更容易正确地对对象进行分类。
D.查找纹理:正确识别图像的另一个重要方面是区分图像中的纹理。两个对象之间的纹理差异使机器更容易正确地对对象进行分类。

E.做出猜测:执行上述步骤后,机器需要做出大概率正确的猜测,并将图像与数据库中存在的图像进行匹配。
F.最后看大图:最后,一台机器会看到更大,更清晰的画面,并根据所提供的算法说明检查是否正确识别了该画面。在过去的几年中准确性得到了很大的提高,但是当机器要求处理带有混合物体的图像时,机器仍然会犯错误。
美国大学:
卡内基梅隆大学机器人学院
加州大学洛杉矶分校
北卡罗来纳大学教堂山分校
华盛顿大学
加州大学伯克利分校
斯坦福大学
麻省理工学院
康奈尔大学
宾夕法尼亚大学
加州大学尔湾分校
哥伦比亚大学
伊利诺伊大学香槟分校
南加州大学
密西根大学
普林斯顿大学
罗切斯特大学
德克萨斯大学奥斯汀分校
马里兰大学学院公园
布朗大学
中央佛罗里达大学
纽约大学
密西根州立大学
麻省大学,阿默斯特
西北大学
加州大学圣地亚哥分校
加拿大大学:
艾伯塔大学
多伦多大学
不列颠哥伦比亚大学
西蒙弗雷泽大学
欧洲大学:
INRIA法国
牛津大学(http://www.robots.ox.ac.uk/~vgg/)
苏黎世联邦理工学院
德国马克斯·普朗克研究所
爱丁堡大学
萨里大学
弗莱堡大学
瑞典KTH
德累斯顿大学
达姆施塔特工业大学
瑞士EPFL
鲁汶大学
巴塞罗那计算机视觉中心
瑞士IDIAP
伦敦帝国理工学院
海德堡国际机场
曼彻斯特大学
波恩大学
亚琛工业大学
阿姆斯特丹大学
慕尼黑工业大学
捷克技术大学
剑桥大学
格拉茨
IST奥地利
伦敦玛丽皇后大学
苏黎世大学
代尔夫特大学
利兹大学
伯尔尼大学
隆德大学
特伦托大学,意大利
意大利佛罗伦萨大学
斯图加特大学
萨尔大学
巴黎中央学校
巴黎理工学院
奥卢大学
卡尔斯鲁厄理工学院
3.如果是计算机视觉领域的新手,可以在下面找到一个必须了解的详尽主题列表。
A.初学者水平
数学:
线性代数
奇异值分解
入门级模式识别
主成分分析
卡尔曼滤波
傅里叶变换
小波
图像处理:
杜克大学在Coursera上提供的在线课程
冈萨雷斯和伍兹的数字图像处理
B.高级
线性判别分析
概率,贝叶斯规则,最大似然,MAP
混合物和期望最大化算法
入门级统计学习
支持向量机
遗传算法
隐马尔可夫模型
贝叶斯网络
学习OpenCV:使用OpenCV库的计算机视觉
Tombone的计算机视觉博客
我们还应该了解该领域的一些关键词和关键工作,在这里我们可以从中学习到它们中的一些:
SIFT:通用视觉的经典描述符
HOG:众所周知的描述符,特别适合人类检测
Viola-Jones:伟大的人脸检测器
Shape Contexts
Deformable Part Models
必读书籍清单包括:
入门级:
1. 计算机视觉:算法与应用
2. 计算机视觉:现代方法David A. Forsyth,Jean Ponce
3. 计算机视觉中的多视图几何 作者:Richard Hartley,Andrew Zisserman
这里当也少不了我们小白老师的书啦~
4.OpenCV4快速入门(购买链接如下哦~)
高级水平—走向深度学习:
4. Michael Nielsen的“神经网络和深度学习”在线书;这是一个很棒的,温和的介绍:神经网络和深度学习
TED观看谈话:
1.李飞飞:我们如何教计算机理解图片
2. BlaiseAgüera和Arcas:PhotoSynth如何连接世界图像
3. 浅川千惠子:新技术如何帮助盲人探索世界
4. 詹妮弗·希利:如果汽车可以说话,事故是可以避免的
5. 戈兰·莱文(Golan Levin):回望你的艺术
6. Paul Debevec:制作真实照片的数字脸动画
在线课程:
Udacity:计算机视觉概论
斯坦福大学的CS231n:用于视觉识别的卷积神经网络 中央佛罗里达大学-Mubarak Shah教授的视频讲座 将您所有的知识应用于从上述资源中获得的概念和算法,以解决一些任务并自行完成一个项目。
高级水平—走向深度学习:
杰夫·欣顿(Geoff Hinton)在Coursera上的神经网络讲座
斯坦福大学课程:用于自然语言处理的深度学习
斯坦福大学课程:用于视觉识别的卷积神经网络
讲座课程:
计算机视觉中的深度学习(Sanja Fidler教授)
先进的计算机视觉(James Hays教授)
4.全球项目

微软计算机科学家和研究人员正在努力“解决”癌症
东京项目 —提供支持AI的原型,以增强盲人或视力障碍者对社交,物理和文本环境的认识。
教学机预测未来

最左侧的列显示操作开始之前的帧,其下方是算法的预测。右列显示视频的下一帧。
5.与专家的对话

对于任何想开始学习该领域的学生,我建议他们通过研究人员的网页并选择他们认为有趣的问题来选择问题。大多数情况下,人们都在研究最前沿的问题,这些问题可以从那里获得可用的标准数据集。他们可以选择一个问题,一个数据集以及一个他们可能想使用的库,然后动手做。
在攻读硕士或博士学位的学生中,我通常会寻找的是具有责任心,积极性和决心的学生。使您的基本概念清晰明了。尝试阅读研究论文。尝试了解全世界研究人员正在研究的AI前沿问题。
B.与Richa Agrawal的对话 | 宾夕法尼亚大学校友| Whodat的计算机视觉研究工程师

我毕业于MNIT Japur,在那里学习期间我加入了机器人小组。我们做了一些项目,然后参加了IIT Roorkee的国家级比赛。我们赢得了比赛,这鼓舞了我的士气。完成学士学位后,我开始在Yahoo工作。我意识到这不是我想要或想做的事情,因此去了宾夕法尼亚大学攻读硕士学位。那时,我通过学习不同的课程探索了不同的研究领域,并最终决定将计算机视觉作为我的主要研究兴趣。毕业后,我在美国的一家初创公司工作,并希望在印度寻找类似的机会,因为该领域甚至在这里都开始发展。在Whodat(一家基于班加罗尔的计算机视觉初创公司)中,我们使用增强现实和可视化技术进行处理。举例来说,您打算为自己的房屋购买家具;您去商店并在家庭环境中可视化后选择商店。家具交付后,您会意识到它太大或太小,但已经为时已晚。我们正在尝试通过构建一个解决方案来帮助您,该解决方案将使您在家中的家具可视化。这将使您能够做出更好的决定,并轻松地购买物品。
在学习时,很多时候我都无法尽力而为,经常感到沮丧,但我朋友的忠告解救了我。他告诉我-“只有少数人(不到0.1%)能够做到这一点(从国外做硕士,并且在计算机视觉等技术领域也是如此),并且您已经证明了自己是其中之一。而且,您只需要加倍努力。只有您自己可以做到,没有其他人可以做到。最后,只有您的学习才是最重要的。
对于学生入门的一些建议是与其他大学的同龄人交谈,并询问他们从事什么样的项目。然后他们可以与领导者组成团队并开始实验。我还建议参加比赛和黑客马拉松。重要的是要找到自己的兴趣并与他们一起去,而不是在自己不喜欢的地方工作。例如,计算机视觉在印度是一个广阔的领域,在印度拥有广阔的发展空间,在这个领域,您所需要的只是一台照相机,它现在已经开始渗透到更小的城市。因此,计算机视觉的未来绝对是光明的。