
CVPR2021 GAN详细解读 | AdaConv自适应卷积让你的GAN比AdaIN更看重细节(附论文下载)


本文提出了AdaIN的改进版本,称为自适应卷积 (AdaConv),它可以同时适应统计和结构风格,表现SOTA!性能优于AdaIN等网络,已收录于CVPR 2021!
作者单位:迪士尼研究院, ETH Zurich
1简介
图像的风格迁移是CNN在艺术领域的一种应用,这里的风格迁移是指将其中一幅图像的“风格”迁移到另一幅图像上,同时保留后者的内容。
近期的SOTA风格迁移模型大多数都是基于最新的自适应实例归一化(AdaIN),这是一种将风格特征的统计特性迁移到内容图像的技术,可以实时迁移大量风格。

然而,AdaIN是一个全局的操作;因此,在迁移过程中,风格图像中的局部几何结构常常被忽略。于是作者提出了自适应卷积(AdaConv),这是AdaIN的通用扩展,允许同时传输统计和结构风格。除了风格迁移,本文的方法还可以很容易地扩展到基于风格的图像生成,以及其他已经采用AdaIN的任务。
2相关工作
2.1 Neural Style Transfer based on CNNs
基于CNN的神经网络风格转移最初是由Gatys等人提出的。虽然该方法允许在图像之间转换任意样式,但它的优化过程是比较缓慢的。
Johnson等人通过引入感知损失(perceptual loss)来解决优化慢的问题,允许显著加速优化并实现实时结果。同时,Ulyanov等人提出了一种新的风格迁移方法,通过评估预先训练特定风格的前馈神经网络,进一步加快了推理速度。在后续工作中,他们还用实例标准化层(IN)取代了批处理标准化层(BN),该方法在不影响速度的情况下产生更高质量的结果。
为了进一步改善对风格迁移结果的控制,Gatys等人随后在基于优化和前馈的方法中重新制定了损失函数,引入了显式的颜色、规模和空间控制。
在IN思想的基础上,Dumoulin等人提出了条件实例规范化(CIN),并将CIN层设置在Style上,允许单个模型从32种预定义的Style或它们的插值中执行样式转换。Ghiasi等人则进一步扩展了CIN,允许转换为任意风格;这是通过使用大量的风格语料库来训练一个将风格图像转换为条件反射潜在向量的编码器来实现的。
Cheng等人提出了基于Patch的风格交换方法来实现任意的风格转移。同时,Huang等人提出了一种任意风格迁移的方法,通过有效地使IN适应风格特征的均值和标准差,从而产生了AdaIN。
Li等人对该方法AdaIN进行了扩展,对给定风格的潜在特征进行了增白和着色。Sheng等人进一步扩展了这一想法,并采用了风格装饰器模块和多尺度风格适配。
最近,Jing等人注意到,直接用样式特性的统计数据替换内容特性的统计数据可能是次优选择;相反,动态实例标准化(DIN)方法训练style编码器输出内容特性的新统计数据,同时还调整后续卷积层的大小和采样位置。
除了实例规范化,Kotovenko等人也探索了对抗学习,以更好地将风格与内容分离。
而本文工作的目的是进一步扩展AdaIN,根据风格图像预测整个卷积核和偏差,传递统计数据和风格的局部结构。
2.2 Modulation layers in generative models
生成模型中的Modulation layers也促成了风格迁移提升的一个突破口。诸如StyleGAN使用了原始版本的AdaIN,但是输入风格统计数据是由MLP从高斯噪声向量中预测的。为了减轻AdaIN造成的一些可见的伪影,StyleGAN-v2用一个权重Modulation layer代替它,它只对标准差进行归一化和调制,而不改变平均值。
由于AdaIN及其变体只转换全局统计信息,它们对style输入中的局部空间语义不敏感。为了解决这一限制,有学者提出了新的方法,即从输入空间布局图像中预测空间变化的归一化参数。
SPADE用从输入语义掩码回归的逐像素变换替换AdaIN的全局仿射变换。SEAN进一步扩展了SPADE,考虑了一个附加的带有输入布局掩码的样式向量。SPADE和SEAN都保留了用于语义图像生成的条件空间布局;它们可以有效地控制每个kernel在特定的图像位置是如何被强调或抑制的。
相反,本文的AdaConv方法在测试时生成全新的kernel。另外,SPADE和SEAN也不直接适用于风格迁移,而是在样风格迁移中必须保留内容图像的空间布局。
2.3 Kernel prediction
Kernel prediction也在以前的工作中进行了探讨。
请注意,上述特征归一化和调制的所有方法都遵循类似的过程:它们定义了单独应用于每个特征通道的标量仿射变换。
主要区别在于:
转换参数是手工制作的,还是在训练中学习的,还是在测试时预测的; 每个通道的转换是全局的还是空间变化的。
那些回归全局转换的方法也可以理解为在测试时预测1×1 2D kernel。
对于风格迁移,Chen等人在内容图像特征上学习了卷积的风格特定的滤波器组。该方法局限于过滤训练时学到的组;它不能为在测试时给出的不可见style生成新的kernel。
Jing等声称使用通用DIN块能够从输入中回归动态卷积;然而,实验结果仅限于1×1转换。Kernel prediction的相关工作也不仅仅只是style transfer。
最新的蒙特卡罗渲染去噪方法使用神经网络预测动态kernel,用于重建最终去噪的帧。
神经网络也被提出用于预测手持相机以突发模式拍摄的自然图像的去噪核。Niklaus等人的预测视频帧插值核;他们后来将这项工作扩展到预测可分离卷积参数。
Xue等利用CNN从随机高斯变量中预测动态kernel用于合成可信的下一帧。
Esquivel等人的预测自适应kernel用于减少在有限的计算资源下准确分类图像所需的层数。
在本文中作者探讨了一个类似的想法,即利用测试时的Kernel prediction来改进生成模型中的风格迁移和基于风格的调制。
3Feature Modulation with AdaConv
这里先描述AdaConv和Kernel prediction,展示AdaConv如何泛化以及扩展特征调制中的1×1仿射变换。
首先在风格迁移的背景下画一个与AdaIN平行的例子,然后展示AdaConv如何更好地调节局部特征结构,更好地迁移空间风格,同时该方法也适用于风格迁移之外的高质量生成模型。
3.1 Overview
考虑通常的style表示法,其中和分别表示风格为尺度和偏差项(例如,对于风格迁移,和是风格图像特征的平均值和标准差)。
给定一个值为的输入特征通道和所需的style,AdaIN将style定义的仿射变换应用于标准化的输入特征,
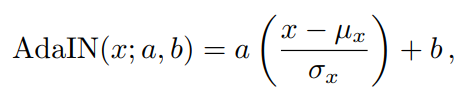
其中,和为特征通道上的均值和标准差。
因此,AdaIN只改变每个通道基于条件设置样式参数的全局统计。注意,无论每个样本周围的特征值的空间分布(结构)如何,整个通道都是相等调制的。
因此,作者扩展AdaIN的第1步是引入一个条件2D style filter ,取代scale term和产生扩展的风格参数。该filter允许根据样本周围邻域的局部结构以空间变化的方式调制特征通道:
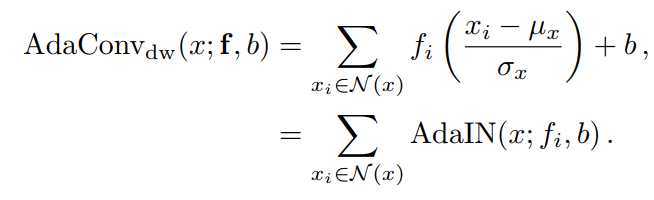
注意,这个depthwise AdaConv变种包含AdaIN,这是1个特殊情况1×1 filter f和
完整AdaConv调制的第2步是通过扩展输入style参数,也包括一个separable-pointwise卷积,该卷积用于C特征通道的输入,来扩展这个深度变体。这使得AdaConv可以基于一种风格进行调制,这种风格不仅可以捕获全局统计数据和空间结构,还可以捕获不同输入通道中特征之间的关联。
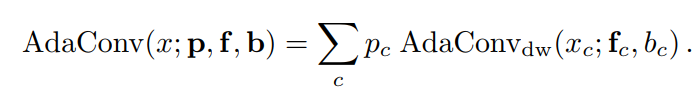
AdaConv的输入风格有效地包含了一个深度可分离的3D卷积核,具有深度和逐点卷积分量,以及每个通道的偏差。
用于调制输入的深度和逐点卷积核的实际数量是一种设计选择,可以任意大,这可以通过使用深度可分离卷积层中的组的数量来控制。
接下来,作者还提出了AdaConv的kernel prediction框架,并展示了它如何作为AdaIN的一般替代来实现更全面的基于风格的条件转换,也在其他高质量的生成模型。
3.2 Style Transfer with AdaConv
下图给出了风格迁移架构的概述。
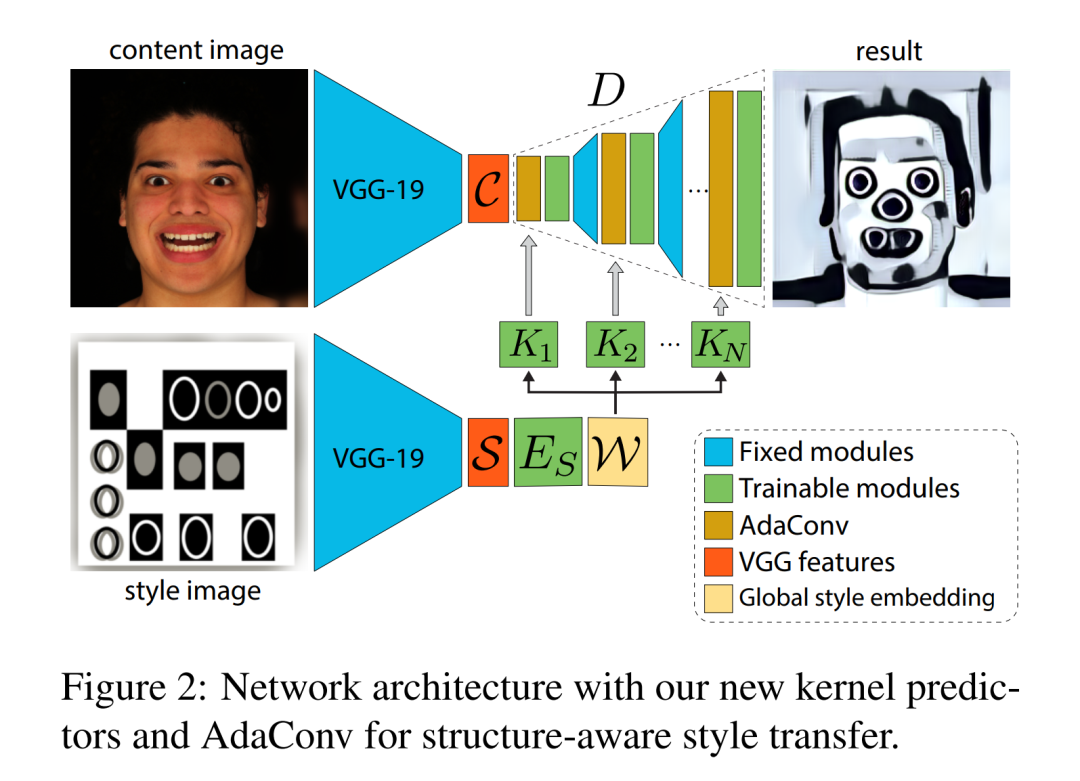
输入风格和内容图像编码使用pre-trained VGG-19编码器获取潜在的风格特征S和内容C。
对于kernel prediction来说,风格特征编码进一步通过风格编码器ES获得全局风格描述符W;对于W kernel prediction网络输出具有每通道偏差的深度可分卷积核。这些预测被输入到解码器D的所有层中来输出风格迁移的结果。
本文的风格迁移架构使用了4个kernel prediction,它们用于解码图像的4种不同分辨率,每个kernel具有不同的维度。
每个解码层都有一个自适应卷积块(下图),其中预测的深度卷积和逐点卷积先于标准卷积。这些标准卷积层负责学习与风格无关的kernel,这些kernel对于重建自然图像很有用,并且在测试时保持固定。在VGG-19潜在特征空间内,联合训练编码器ES、kernel prediction K和解码器D。
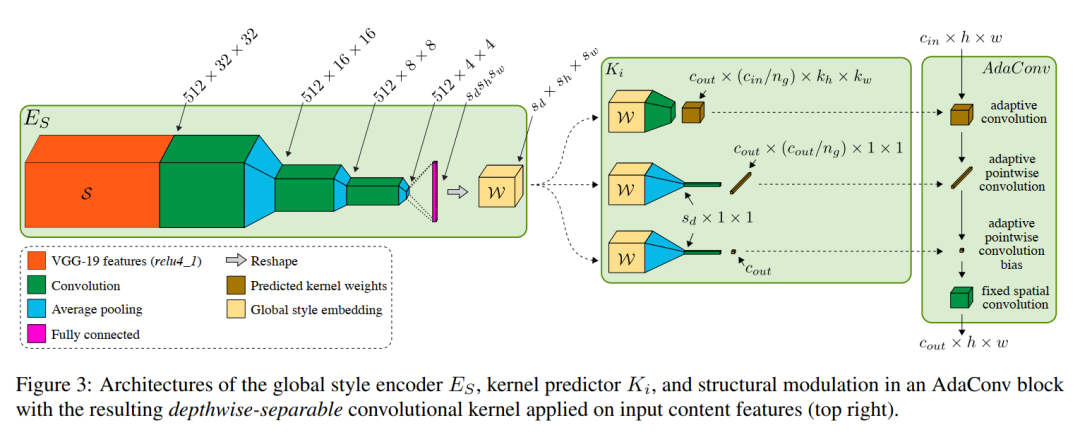
1 风格编码
现在转向从风格特征S预测卷积核的目标,用于图像解码器的每个尺度上的内容特征C。
在这里,一个中间步骤是计算一个综合描述不同尺度的风格图像的风格表示W,同时以风格传递损失为指导。这种设计选择也是通过与最先进的生成建模的类比而产生的,其中术语“style”表示图像的全局和局部属性。
预训练的VGG-19网络将尺寸为(3,256,256)的原始输入修改为尺寸为(512,32,32)的VGG-19 层样式张量S。这里,感受野并没有覆盖整个风格图像。因此,需要通过训练一个额外的编码器组件ES,将S减少到全局嵌入W中,如图3所示。
这里的风格编码器ES包括3个初始块,每个块具有3×3卷积、一个平均池化操作和一个Leaky ReLU激活。
然后,ES的输出被Reshape并输入到最后一个完全连接的层,该层提供全局风格描述符,该层反过来又被Reshape为大小为W的输出张量。这种嵌入的尺寸是超参数定义为要预测的kernel大小的一个因素。
由于使用了这个完全连接层,网络只能处理固定尺寸(3,256,256)的输入风格的图像。然而,内容图像的尺寸不受限制,因为它流经网络的一个全卷积的组件。
2 预测深度可分离卷积
图2中的每个kernel predictor K都是一个简单的卷积网络,它的输入是风格描述符W,而输出是一个深度可分离的kernel。
选择预测深度可分离的kernel的动机是希望保持kernel predictor的简单和计算效率,同时也使随后的卷积更快。
标准卷积层取一个维数为1的输入特征张量,并将其与一个大小为的kernel张量进行卷积,其中和是输入和输出通道的数量。每通道偏置也被添加到输出。因此,该层所需的权重数为:。
深度可分离卷积通过将输入通道聚集到个独立的组中,并通过应用独立的spatial和pointwise kernel(分别学习结构和交叉固定空间卷积适应通道相关)来减少这个数量。所需重量减少为。对于带有的卷积层,输入的每个通道都与自己的卷积核进行卷积。
接下来是对1×1卷积核的逐点卷积,以扩展输出中的通道数,并在最终输出中添加每通道的偏置。
这里,需要注意的是,解码器中的4个AdaConv层的随着空间分辨率的增加而减少,分别为512、256、128和64。
因此,最低空间分辨率的kernel predictor通常具有最高的参数数。为了将网络容量均匀分布在连续的分辨率层上,作者在较低的分辨率上设置了较大的,并在连续的层上逐渐降低,从而得到更好的结果。对于深度卷积核和depthwise卷积核,的设置是相同的。
因此,每个kernel predictor K在该解码器内为深度卷积AdaConv层输出必要的权值。这些权重包括:
spatial kernel的size ; pointwise kernel的size bias项。
每个kernel predictor K的输入是大小为的全局风格描述符W,它通过卷积和池化层得到,这些层输出目标维度的spatial kernel,如图3所示。
这些层可能由标准卷积或转置卷积组成,其参数在设计时确定,并取决于要预测的kernel的大小。
为了预测pointwise 1×1 kernels,作者将W集合到一个大小,然后执行一维卷积来预测pointwise的核。
作者对每个通道的偏差使用一个单独的预测器,类似于pointwise kernels的预测器。一旦kernel和偏差被预测,它们被用来调制如图3右半部分所示的输入。
4实验
4.1 风格迁移
与AdaIN的对比如下,可以看出有明显的改善:


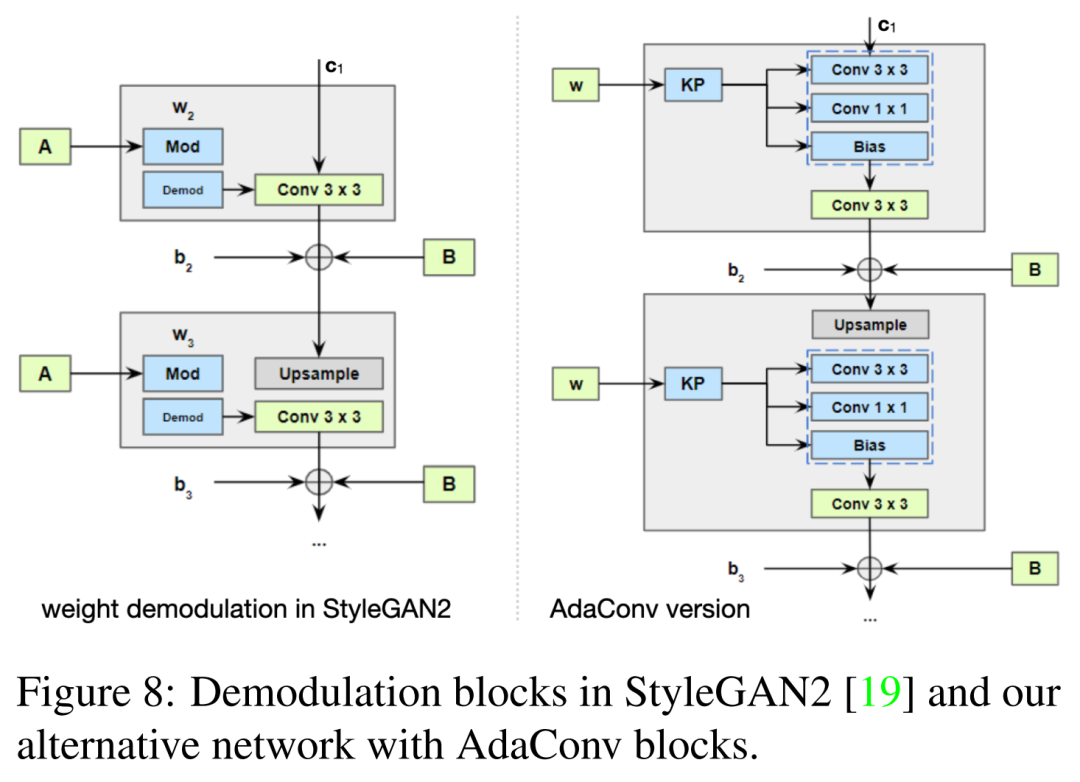
4.2 生成模型的扩展
基于StarGAN-v2的改进如下:
实验结果如下:

5参考
[1].Adaptive Convolutions for Structure-Aware Style Transfer
6推荐阅读

全新激活函数 | 详细解读:HP-x激活函数(附论文下载)

遮挡人脸问题 | 详细解读Attention-Based方法解决遮挡人脸识别问题(附论文下载)

效率新秀 | 详细解读:如何让EfficientNet更加高效、速度更快
本文论文原文获取方式,扫描下方二维码
回复【AdaConv】即可获取论文
长按扫描下方二维码添加小助手。
可以一起讨论遇到的问题
声明:转载请说明出处
扫描下方二维码关注【集智书童】公众号,获取更多实践项目源码和论文解读,非常期待你我的相遇,让我们以梦为马,砥砺前行!
