
美国首次使用CRISPR技术编辑癌症患者细胞,AI帮助对抗饥饿!|技术...

热点追踪 / 深度探讨 / 实地探访 / 商务合作
大家好,一周技术前沿洞察又跟大家见面啦,本周来自高校与实验室的技术突破都十分有趣,有帮助了解大脑活动的、也有帮助癌症治疗的,还有用AI对抗饥饿的。此外,谷歌、英伟达等大公司也有新发现和新突破,赶紧来跟硅谷洞察看看吧!
美国高校
耶鲁大学新研发微观技术实时了解大脑活动
耶鲁大学多个实验室共同协作,终于研发出一种方法,利用微观技术实时了解整个大脑是如何工作的。
研究小组使用两种不同类型的成像技术:双光子显微镜捕获单个神经元的活动,通过介观成像显示整个大脑的活动网络。该团队开发了个统一的平台,用于可视化这些不同的运动成像规模。

(图片来源:Yale University)
耶鲁大学Kavli神经科学研究所成员,神经科学副教授Michael Higley说:“融合对大脑不同活动的理解是神经科学的基本挑战之一。这种新颖的方法使我们弥合了分子生物学,细胞生物学和系统生物学之间的空白。”
耶鲁大学的研究人员将fMRI添加到了该平台一起研究其他项目,将大脑活动与小鼠的学习和认知过程联系起来。研究人员预计,这项新技术最终将帮助科学家追踪特定分子、细胞和大脑网络在人类行为和疾病中的作用。
感兴趣可以阅读:
https://news.yale.edu/2019/11/04/yale-scientists-capture-dynamic-brain-action
美国第一例使用CRISPR技术编辑癌症患者细胞
美国科学家上周三首次宣布,使用基因编辑工具CRISPR修改了癌症患者的细胞。目前看来该技术似乎是安全的,不过尚且无法确定编辑后的细胞是否可以帮助患者延长寿命。研究人员认为使用CRISPR对抗疾病迈出了重要的第一步。
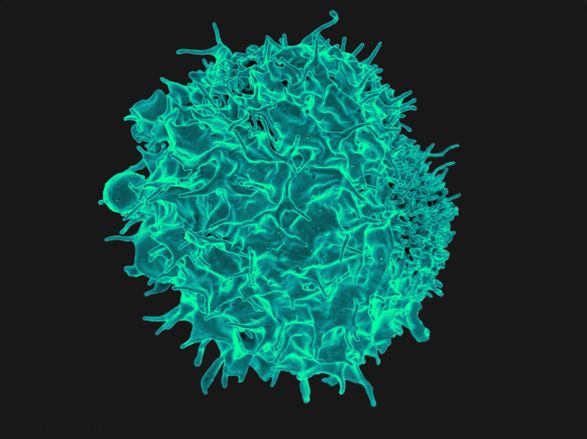
(显微镜下的T细胞。图片来源于:National Institute ofAllergy and Infectious Diseases)
到目前为止,美国共有三名癌症患者接受了CRISPR实验性治疗,其中涉及从血液中提取免疫T细胞,在实验室中对其进行编辑,然后再注入体内。T细胞是人体抵抗感染和其他外来入侵者的天然机制。但是癌细胞可以躲避免疫系统,不被T细胞发现。这项研究首次提出在人类中使用CRISPR,通过去除干扰免疫细胞结合癌细胞并杀死它们的能力的三个基因来使患者的T细胞工作。
通过从细胞中切除有害的DNA链,使用CRISPR来治疗或可能治愈多种遗传性疾病和癌症的方法颇有前景,已经引起了多为知名投资者的资金投入。CRISPR期望达到的结果是消除疾病,而不仅是像绝大多数药物一样减轻症状而已。但是CRISPR技术相对较新,目前尚不清楚它的安全性。
感兴趣可以阅读:
https://onezero.medium.com/in-u-s-first-scientists-safely-edit-cancer-patients-cells-with-crispr-7c54727609bb
西佛吉尼亚大学研制出脑内芯片治疗阿片成瘾
阿片类药物成瘾是美国面临最普遍的医保问题之一。西弗吉尼亚大学洛克菲勒神经科学研究所RNI和西弗吉尼亚大学医学院WVU最近开启了一项新的临床试验,试图使用大脑内嵌技术来抑制患者阿片类药物成瘾及对其他药物的抗药性。
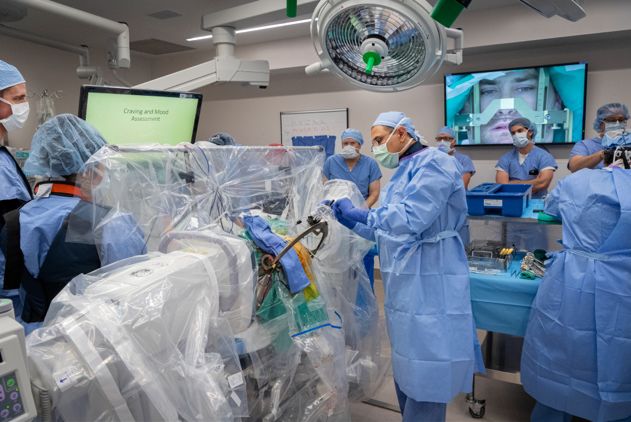
(图片来源于West Virginia University Health System)
RNI和WVU的神经外科医生团队成功地将“深层大脑仿真”DBS设备植入了一名33岁男子的大脑中。DBS设备由许多微小的电极组成,附着在与成瘾和自我控制行为有关的大脑特定部位。理论上讲,DBS能够遏制大脑发送成瘾相关的冲动,并且可以实时监控患者对上瘾药物的渴望,从而了解患者在阿片类药物成瘾情况下的具体情况,为研究人员提供有价值的数据。
这项试验最初包括四名参与者,他们都曾多次戒瘾,但久未成功。这是戒瘾最后的手段,但是如果临床试验产生了积极的结果,那么当其他选择都用尽时,可以作为一种帮助严重病例的选择。
感兴趣可以阅读:
https://techcrunch.com/2019/11/05/the-first-u-s-clinical-trial-of-using-an-in-brain-chip-to-fight-opioid-addiction-is-now-underway/
康奈尔大学与研究者和图书管理员合作,使用AI对抗饥饿
对于发展中国家的小农来说,种植有效的农作物以适应干旱,洪水,热浪等气候变化越来越重要。
但是研究有时指向不同的方向。因此,决策者很难决定在哪里拨出有限的资金,以及如何最好地帮助农民采用合适的农作物。
Ceres2030是一项由农业和生命科学学院(IP-CALS)国际计划,国际粮食政策研究所和国际可持续发展研究所的国际计划牵头的全球性工作,正在利用机器学习,图书管理员的专业知识和前沿的研究分析利用现有知识来帮助解决这些挑战,目标是到2030年消除饥饿。

包括来自23个国家的77名研究人员在内的8个小组正在采用基于证据的综合方法-严格的文献分析,将针对特定问题的所有研究汇总在一起,以评估其含义。这些依靠透明性和严格性的合成方法使其他研究人员可以重复该过程并得出相同的结论,这些合成方法在医学中得到了广泛的应用,但对农业而言却相对较新。这些综合技术将评估在一个地理位置成功实施的措施在其他地方也将如何运作。
农业具有地理特殊性-在世界各地,甚至有时在50英里之外,情况都不尽相同,通过全面的系统审核将所有解决方案整合在一起,可以确定有效的方法,并考虑它们是否可能在其他地方有效。
感兴趣可以阅读:
https://news.cornell.edu/stories/2019/10/project-partners-researchers-librarians-and-ai-fight-hunger
CMU开发AI传感系统EduSense,帮助高等教育实现快速教学反馈
虽然K-12教育人员的培训和反馈机会比比皆是,但是在高等教育里却并非如此。当前,对老师最有效的提高机制是让专家观察课程并提供个性化反馈。但是,卡内基梅隆大学研究人员开发的新系统提供了一种全面的实时传感系统,该系统便宜且可扩展,可为老师提供持续的反馈机制。
该系统称为EduSense,可分析与有效指令相关的各种视觉和音频功能。它使用两台壁挂式摄像机-一台面向学生,一台面向老师,通过感知学生的姿势和以及老师在叫学生之前暂停的时间来确定他们的参与度。
单个实时的摄像机可以查看教室中的每个人,并自动识别信息,例如学生正在看的地方,举手的频率以及老师是否在教室里移动等等。
随着计算机视觉和机器学习的发展,通过数月的观察才能获得的见解在数天之内就可得到,大大缩短了反馈机制的时间。
该小组将继续开发面向老师的应用程序,通过收集数据来了解如何以最好的方式提供反馈,让教授可以将反馈整合到实践中。从而帮助他们改善教学实践。

感兴趣可以阅读:
https://www.cs.cmu.edu/news/edusense-fitbit-your-teaching-skills
实验室
可再生能源如何存储?科学家研发流动电池
可再生能源的存储一直是个挑战,而将电力储存在液态电解液罐中的流动电池(flow batteries)可能是答案。但到目前为止,电力公司还没有找到一种足够低成本的电池,能够在10至20年的生命周期内可靠地为数千户家庭供电。
如今,美国能源部劳伦斯伯克利国家实验室(Berkeley Lab)的研究人员开发了一种电池膜技术,可能会推动寻找解决方案。

AquaPIM 样品. (图片: Marilyn Sargent/Berkeley Lab)
根据《Joule》杂志报道,Berkeley Lab的研究人员从一种叫做AquaPIMs的聚合物中开发出了一种用途广泛、价格实惠的电池膜。该聚合物使得仅基于锌、铁和水等材料制作长效低成本电池成为可能。这项研究突破,或将加速流动电池技术的早期研发,特别是在寻找适合不同电池化学成分的膜方面,进而推进使用可扩展、低成本、基于水性化学物质制作的流动电池的发展。
感兴趣可以阅读:
https://newscenter.lbl.gov/2019/11/07/grid-battery-for-renewable-energy/
大公司
Google发布视觉任务通用基准,推动深度学习视觉任务标准化
深度学习彻底改变了计算机视觉,在视觉任务上实现了空前的性能。但是,从头开始学习视觉表示通常需要成千上万的训练示例。虽然可以通过使用预训练的表示,比如TensorFlow Hub(TF Hub)和PyTorch Hub等服务广泛使用。但是预训练的存在本身可能是一个障碍。
例如,图像提取特征的任务的模型有很多,并且不同的模型使用不同的评估协议,但很难知道哪种方法可以提供最好的表现。
因此研究团体必须有一个统一的基准,可以据此评估现有和未来的方法。
为了解决这个问题,Google发布了“视觉任务通用基准”(VTAB)。VTAB是一种评估协议,由学习算法必须解决的一组评估视觉任务组成。旨在评估完成通用有效的视觉表示的进度。这些算法可以使用预训练的视觉表示来辅助它们,并且必须仅满足两个要求:
i)不得对下游评估任务中使用的任何数据(标签或输入图像)进行预训练。
Ii)它们不得包含硬编码的,特定于任务的逻辑。也就是说需要将评估任务视为未见过的测试集。
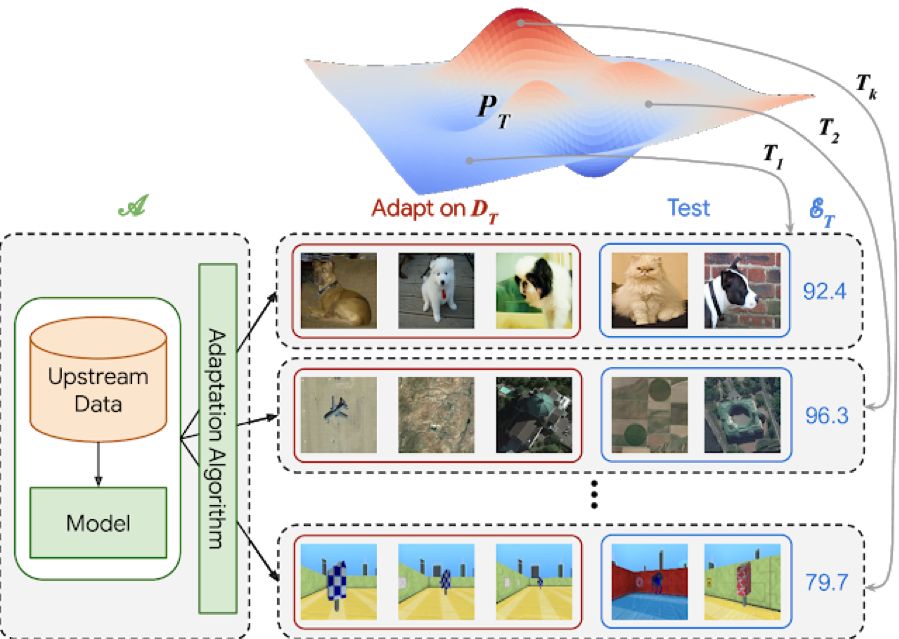
这些约束条件确保了成功应用于VTAB的解决方案将能够推广到将来的任务。
VTAB已经帮助我们更好地理解了哪些视觉表示可以通用于视觉任务,并为将来的研究提供了方向。Google希望这些资源有助于推动通用和实用的视觉表示方法的发展,从而即使在有限的数据情况下也能完成视觉领域的深度学习任务。
感兴趣可以阅读:
https://ai.googleblog.com/2019/11/the-visual-task-adaptation-benchmark.html
AI用你的一张人像照片,生成一段专业舞蹈
英伟达研究团队近期发布了一项AI研究,只需要一张人的全身照片,就可以生成一系列的舞蹈动作。
该研究论文发布在arXiv服务器上。研究团队表示,一旦他们的律师“解决了一些法律问题”。他们就会立即发布代码。
除了使用人像图片,让其“跳舞”,该人工智能还可以让雕塑看起来像是在跳舞。它也可以应用于人类面部,使人看起来像是在说话。除此之外,它还可以拍摄城市的静态图像,并输出一段汽车似乎在街道上行驶的视频。
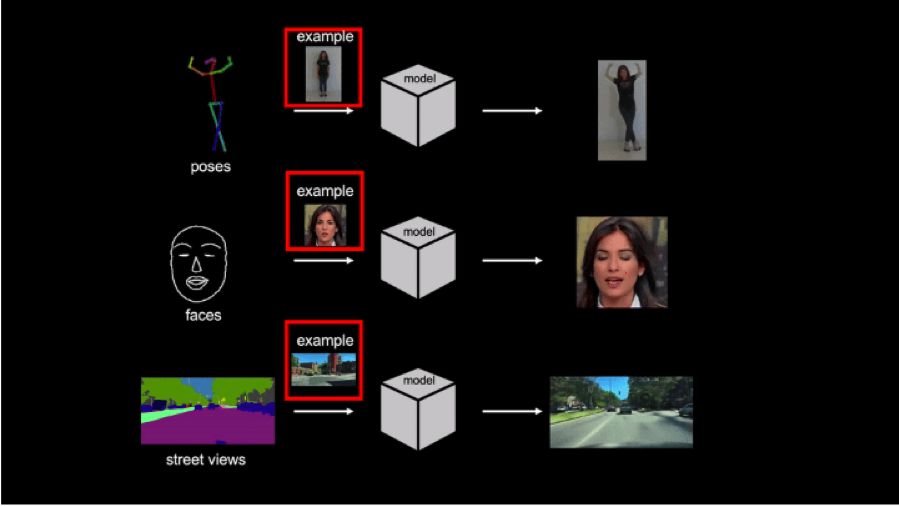
这并不是第一个设计用来制作视频的人工智能系统,但是该研究与以往的研究成果相比,有两项不同。首先,它不需要大量的关于目标人/物体的图像或视频;第二,其他人工智能系统通常只能输出包含在其训练集中的目标的视频,但该系统可以处理来自任何人/物体的图像。
虽然目前它输出的图像片段还不算完美,但这让人了解到我们离可以轻松制造出完美无瑕的虚假视频的人工智能有多近,以及我们多么迫切地需要技术来检测虚假视频。
感兴趣可以阅读:
https://thenextweb.com/artificial-intelligence/2019/11/05/nvidias-new-ai-can-make-anyone-move-like-jagger-with-just-a-single-photo/
海外高校
神经网络算法从脑电波中实时重构人的“思想”
来自俄罗斯的研究人员研发出一种人工智能,通过读取和解码人脑电波,就能实时绘制出一个人所看到的东西。并且,这项技术是无创性的,所有的脑波信息都是通过一个覆盖电极的脑电图(EEG)头戴装置收集的。
该研究由莫斯科物理和技术研究所和俄罗斯俄罗斯脑机接口公司 Neurobotics的团队主导,他们已经在bioRxiv服务器上发布这项研究。
首先,研究人员在参与者的头皮上放置一个电极帽,他们就可以记录使用者的脑电波。
然后,让每个参与者观看20分钟的10秒长的视频片段;同时,参与者会被分组,各组观看不同的视频片段。研究人员发现,通过看参与者的脑电图数据,他们就能分辨出参与者看的是哪一个视频。
紧接着,研究人员使用两种神经网络,一个将脑电图数据转换成可比噪声,另一个将视觉“噪声”生成图像,两个算法结合使用,该AI系统就能从参与者的实时EEG数据中绘制出令人惊讶的精确图像,展示出参与者研究所看到的景象。

https://mipt.ru/english/news/neural_network_reconstructs_human_thoughts_from_brain_waves_in_real_time
怎么样,今天的哪条技术前沿洞察你印象最为深刻呢?欢迎大家留言讨论!
更多硅谷热文欢迎点击查看:
软银投资WeWork狂亏47亿美元,报告有史以来最大季度亏损!|一周硅谷热闻
仅用一杯水,10分钟完成干洗?盘点最开脑洞的洗衣科技创新 !
阿西莫夫机器人三定律或已过时?伯克利教授定义AI发展“新三原则”!

推荐阅读
