
使用 eBPF 技术跟踪 Netfilter 数据流
1. 网络层数据流向与 Netfilter 体系
图 1-1 为网络层内核收发核心流程图,在函数流程图中我们可以看到 Netfliter 在其中的位置(图中深色底纹圆角矩形)。图中对应的 hook 点有 5 个,每个hook 点中保存一组按照优先级排序的函数列表:
NF_IP_PREROUTING:接收到的包进入协议栈后立即触发此hook中注册的对应函数列表,在进行任何路由判断 (将包发往哪里)之前;NF_IP_LOCAL_IN:接收到的包经过路由判断,如果目的是本机,将触发此hook中注册的对应函数列表;NF_IP_FORWARD:接收到的包经过路由判断,如果目的是其他机器,将触发此hook中注册的对应函数列表;NF_IP_LOCAL_OUT:本机产生的准备发送的包,在进入协议栈后立即触发此hook中注册的对应函数列表;NF_IP_POST_ROUTING:本机产生的准备发送的包或者转发的包,在经过路由判断之后, 将触发此hook中注册的对应函数列表;

图 1-1 网络层内核收发核心流程图
从图 1-1 的数据流分为三类,分别用不同的颜色标注,因此我们可以得知:
本地处理的数据包,在 Netfliter体系中会依次流经NF_IP_PREROUTING和NF_IP_LOCAL_IN;转发的数据包,在 Netfliter体系中会依次流经NF_IP_FORWARD和NF_IP_POST_ROUTING;本地发送的数据包, 在 Netfliter体系中会依次流经NF_IP_LOCAL_OUT和NF_IP_POST_ROUTING;
2. Netfilter 与 IPtables
2.1 Netfilter 数据结构
Netfilter 架构中对于 hook 点中注册的函数管理,采用二维数组的方式进行组织,纵轴为协议,横轴为 hook 点,每个 Network Namespace 对应一个此种格式的二维数组,详见图 2-1。数组中保存的为 nf_hook_entries 结构,对应保存了该 hook 点中注册的 hook 函数,函数按照优先级的方式进行管理,调用时也是按照优先级进行过滤。
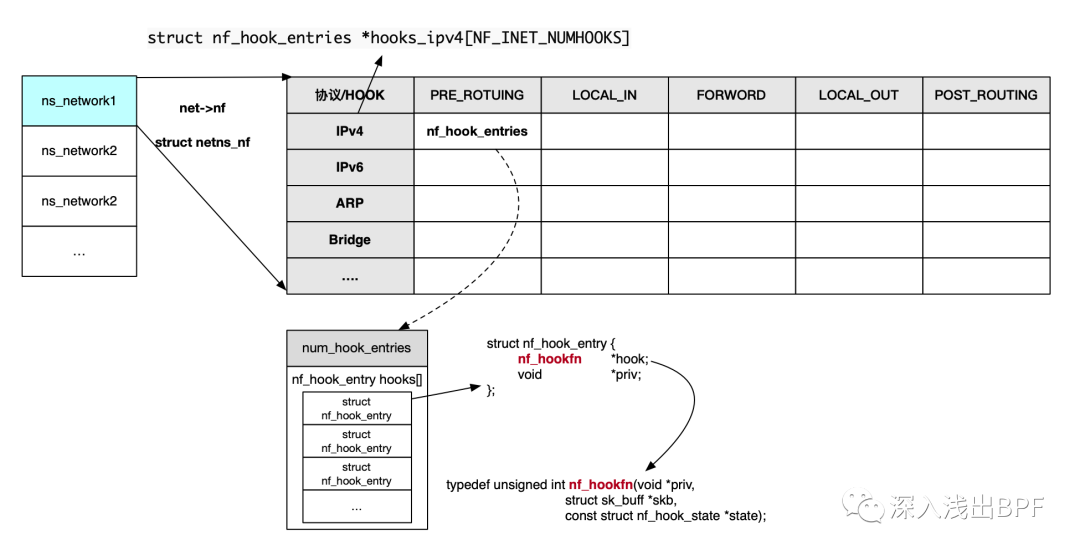
图 2-1 Netfilter hook 点函数数据结构
其中 hooks_ipv4[NF_INET_NUMHOOKS] 位于 net->nf 变量中。hook 函数的原型定义如下:
typedef unsigned int nf_hookfn(void *priv,
struct sk_buff *skb,
const struct nf_hook_state *state);
以 table nat 定义的 hook 函数为例, struct nf_hook_ops nf_nat_ipv4_ops 如下:
static const struct nf_hook_ops nf_nat_ipv4_ops[] = {
{
.hook = iptable_nat_do_chain, // 函数名
.pf = NFPROTO_IPV4, // 协议名
.hooknum = NF_INET_PRE_ROUTING, // hook 点
.priority = NF_IP_PRI_NAT_DST, // 优先级
},
{
.hook = iptable_nat_do_chain,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_POST_ROUTING,
.priority = NF_IP_PRI_NAT_SRC,
},
{
.hook = iptable_nat_do_chain,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_LOCAL_OUT,
.priority = NF_IP_PRI_NAT_DST,
},
{
.hook = iptable_nat_do_chain,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_LOCAL_IN,
.priority = NF_IP_PRI_NAT_SRC,
},
};
nf_nat_ipv4_ops 结构在函数 iptable_nat_table_init 中初始化,最终通过 nf_register_net_hook 函数注册到对应 hook 点的函数列表中。
2.2 iptabes
iptables 是运行在用户空间的应用软件,通过控制 Linux 内核 中 Netfilter 模块,来管理网络数据包的处理和转发。iptables 使用 table 来组织规则,根据用来做什么类型的判断标准,将规则分为不同 table,当前支持的 table 有 raw/mangle/nat/filter/security 等。在 table 内部采用链 (chain)进行组织,其中系统内置的 chain 与 Netfilter 中的 hook 点一一对应,例如 chain PREROUTING 对应于 NF_IP_PRE_ROUTING hook,用户自定义 chain 没有对应的 Netfilter hook 对应,因此必须通过 jump 跳转的方式进行关联。
iptables 的整体组织如下表,纵轴代表的是 table 名,横轴是 chain 的名字,与 Netfilter hook 点一一对应。纵轴的方向代表了在某个 chain 上调用的顺序,优先级自上而下。
| Tables↓ /Chains→ | PREROUTING | INPUT | FORWARD | OUTPUT | POSTROUTING |
|---|---|---|---|---|---|
| (routing decision) | ✓ | ||||
| raw | ✓ | ✓ | |||
| (connection tracking enabled) | ✓ | ✓ | |||
| mangle | ✓ | ✓ | ✓ | ✓ | ✓ |
| nat (DNAT) | ✓ | ✓ | |||
| (routing decision) | ✓ | ✓ | |||
| filter | ✓ | ✓ | ✓ | ||
| security | ✓ | ✓ | ✓ | ||
| nat (SNAT) | ✓ | ✓ |
2.3 内核代码实现
此处以 ip_rcv 函数为例,简单讨论在代码层面的实现:
int ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt,
struct net_device *orig_dev)
{
struct net *net = dev_net(dev);
skb = ip_rcv_core(skb, net); // 对于 ip 数据进行校验
if (skb == NULL)
return NET_RX_DROP;
return NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING,
net, NULL, skb, dev, NULL,
ip_rcv_finish);
}
NF_HOOK 宏在启用 Netfilter 的条件编译下,会首先调用 nf_hook 函数,在该函数中会根据传入的协议和 hook 点,获取到对应的 hook 函数列表头(例如 IPv4 协议中的 net->nf.hooks_ipv4[hook] ),然后在 nf_hook_slow 中循环调用列表中的 hook 函数(hook 函数按照优先级组织),并基于 hook 函数返回的结果决定继续调用列表中后续的 hook 函数,还是直接返回。
Netfilter 中 hook 函数的格式基本如下,直接调用 ipt_do_table 函数,最后的参数传入对应的 table 字段。
static unsigned int iptable_nat_do_chain(void *priv,
struct sk_buff *skb,
const struct nf_hook_state *state)
{
return ipt_do_table(skb, state, state->net->ipv4.nat_table);
}
所以,如果我们想要获取到 Netfilter hook 点中对应函数的过滤的结果,则需要跟踪 ipt_do_table 函数的入参和返回结果即可。
unsigned int ipt_do_table(struct sk_buff *skb, // skb
const struct nf_hook_state *state, // 相关状态
struct xt_table *table) // table 表
3. 使用 eBPF 技术跟踪
经过上述分析,我们了解到对于 Netfilter 的底层函数为 ipt_do_table,那么我们只需要使用 kprobe 和 kretprobe 获取到入参和返回结果,即可以获取到对应的过滤结果,这对于我们分析采用 iptables 管理流量的场景下定位问题非常方便。
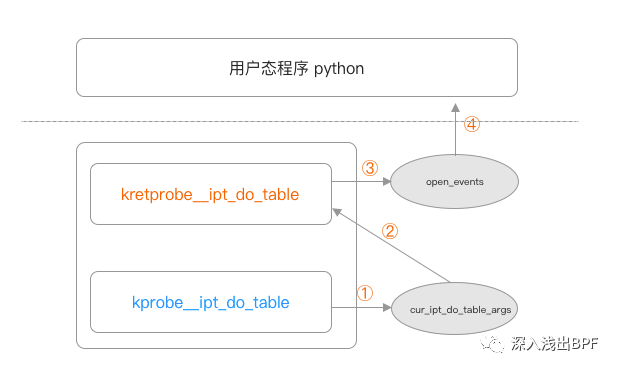
图 3-1 程序架构
运行效果图:
./iptables_trace_ex.py
pid skb table hook verdict
3956565 ffff8a7571a5eae0 b'filter' OUTPUT ACCEPT
完整代码如下:
#!/usr/bin/python
from bcc import BPF
prog = """
#include <bcc/proto.h>
#include <uapi/linux/ip.h>
#include <uapi/linux/icmp.h>
#include <uapi/linux/tcp.h>
#include <net/inet_sock.h>
#include <linux/netfilter/x_tables.h>
#define MAC_HEADER_SIZE 14;
#define member_address(source_struct, source_member) \
({ \
void* __ret; \
__ret = (void*) (((char*)source_struct) + offsetof(typeof(*source_struct), source_member)); \
__ret; \
})
#define member_read(destination, source_struct, source_member) \
do{ \
bpf_probe_read( \
destination, \
sizeof(source_struct->source_member), \
member_address(source_struct, source_member) \
); \
} while(0)
struct ipt_do_table_args
{
struct sk_buff *skb;
const struct nf_hook_state *state;
struct xt_table *table;
u64 start_ns;
};
BPF_HASH(cur_ipt_do_table_args, u32, struct ipt_do_table_args);
int kprobe__ipt_do_table(struct pt_regs *ctx, struct sk_buff *skb, const struct nf_hook_state *state, struct xt_table *table)
{
u32 pid = bpf_get_current_pid_tgid();
struct ipt_do_table_args args = {
.skb = skb,
.state = state,
.table = table,
};
args.start_ns = bpf_ktime_get_ns();
cur_ipt_do_table_args.update(&pid, &args);
return 0;
};
struct event_data_t {
void *skb;
u32 pid;
u32 hook;
u32 verdict;
u8 pf;
u8 reserv[3];
char table[XT_TABLE_MAXNAMELEN];
};
BPF_PERF_OUTPUT(open_events);
int kretprobe__ipt_do_table(struct pt_regs *ctx)
{
struct ipt_do_table_args *args;
u32 pid = bpf_get_current_pid_tgid();
struct event_data_t evt = {};
args = cur_ipt_do_table_args.lookup(&pid);
if (args == 0)
return 0;
cur_ipt_do_table_args.delete(&pid);
evt.pid = pid;
evt.skb = args->skb;
member_read(&evt.hook, args->state, hook);
member_read(&evt.pf, args->state, pf);
member_read(&evt.table, args->table, name);
evt.verdict = PT_REGS_RC(ctx);
open_events.perf_submit(ctx, &evt, sizeof(evt));
return 0;
}
"""
# uapi/linux/netfilter.h
NF_VERDICT_NAME = [
'DROP',
'ACCEPT',
'STOLEN',
'QUEUE',
'REPEAT',
'STOP',
]
# uapi/linux/netfilter.h
# net/ipv4/netfilter/ip_tables.c
HOOKNAMES = [
"PREROUTING",
"INPUT",
"FORWARD",
"OUTPUT",
"POSTROUTING",
]
def _get(l, index, default):
'''
Get element at index in l or return the default
'''
if index < len(l):
return l[index]
return default
def print_event(cpu, data, size):
event = b["open_events"].event(data)
hook = _get(HOOKNAMES, event.hook, "~UNK~")
verdict = _get(NF_VERDICT_NAME, event.verdict, "~UNK~")
print("%-10d %-16x %-12s %-12s %-10s"%(event.pid, event.skb, event.table, hook, verdict))
b = BPF(text=prog)
b["open_events"].open_perf_buffer(print_event)
print("pid skb_addr table hook verdict")
while True:
try:
b.perf_buffer_poll()
except KeyboardInterrupt:
exit()
可以在样例程序的基础上通过 skb 读取对应的 IP 和端口信息(包括源和目的),这可以实现对于 Netfilter 中的 hook 点跟踪。完整的可使用代码参见 skbtracer.py[1],使用帮助如下:
./skbtracer.py -h
usage: skbtracer.py [-h] [-H IPADDR] [--proto PROTO] [--icmpid ICMPID] [-c CATCH_COUNT] [-P PORT] [-p PID] [-N NETNS] [--dropstack] [--callstack] [--iptable] [--route]
[--keep] [-T] [-t]
Trace any packet through TCP/IP stack
optional arguments:
-h, --help show this help message and exit
-H IPADDR, --ipaddr IPADDR
ip address
--proto PROTO tcp|udp|icmp|any
--icmpid ICMPID trace icmp id
-c CATCH_COUNT, --catch-count CATCH_COUNT
catch and print count
-P PORT, --port PORT udp or tcp port
-p PID, --pid PID trace this PID only
-N NETNS, --netns NETNS
trace this Network Namespace only
--dropstack output kernel stack trace when drop packet
--callstack output kernel stack trace
--iptable output iptable path
--route output route path
--keep keep trace packet all lifetime
-T, --time show HH:MM:SS timestamp
-t, --timestamp show timestamp in seconds at us resolution
examples:
skbtracer.py # trace all packets
skbtracer.py --proto=icmp -H 1.2.3.4 --icmpid 22 # trace icmp packet with addr=1.2.3.4 and icmpid=22
skbtracer.py --proto=tcp -H 1.2.3.4 -P 22 # trace tcp packet with addr=1.2.3.4:22
skbtracer.py --proto=udp -H 1.2.3.4 -P 22 # trace udp packet wich addr=1.2.3.4:22
skbtracer.py -t -T -p 1 --debug -P 80 -H 127.0.0.1 --proto=tcp --kernel-stack --icmpid=100 -N 10000
查看 iptables 数据流程,需要添加 --iptable 标记。
4. 相关资料
【BPF 入门系列-8】文件打开记录跟踪之 perf_event 篇[2] [译] 深入理解 iptables 和 netfilter 架构[3] 英文[4] Linux 协议栈--Netfilter 源码分析[5]
参考资料
skbtracer.py: https://github.com/DavadDi/skbtracer/blob/main/skbtracer.py
[2]【BPF入门系列-8】文件打开记录跟踪之 perf_event 篇: https://www.ebpf.top/post/ebpf_trace_file_open_perf_output/
[3][译] 深入理解 iptables 和 netfilter 架构: https://arthurchiao.art/blog/deep-dive-into-iptables-and-netfilter-arch-zh/
[4]英文: https://www.digitalocean.com/community/tutorials/a-deep-dive-into-iptables-and-netfilter-architecture
[5]Linux协议栈--Netfilter源码分析: http://cxd2014.github.io/2017/08/23/netfilter/