
智能座舱入门必备:一文读懂车载语音系统
智能座舱有两大人工智能交互系统,一个基于视觉(计算机视觉)、一个基于语音。前者的应用体现在IMS系统,我之前的文章有过介绍;后者的应用在舱内的语音功能。这篇文章就系统地介绍智能座舱的语音系统(VOS)。
01 概述
02 总体架构
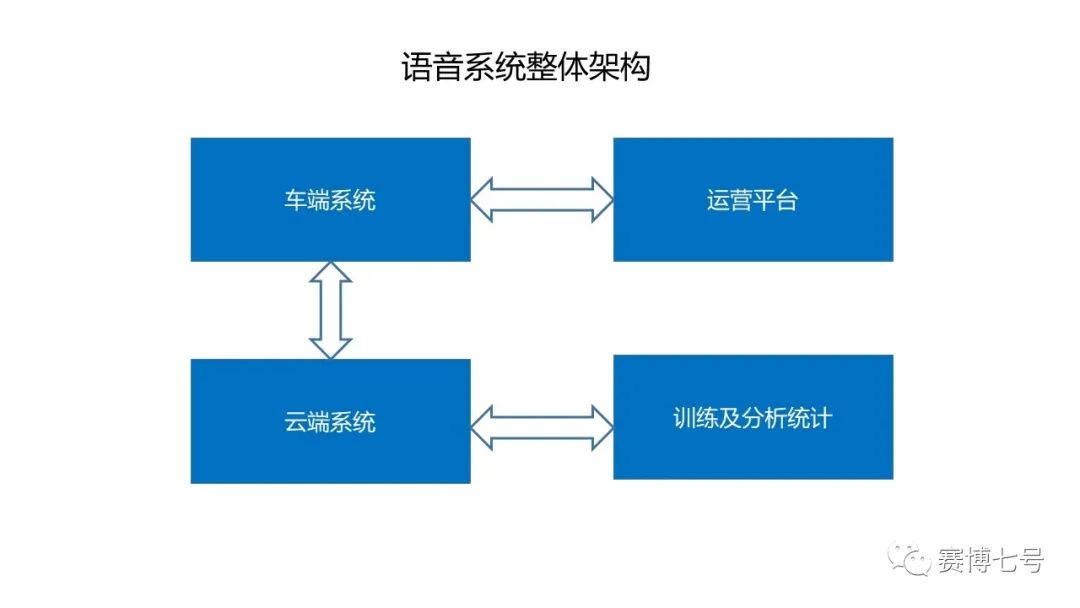
在总体的架构上,语音系统可分为四个模块。即车端系统、云端系统、语音运营管理平台以及训练和分析统计模块。
整体的语音系统和要求,包括车端到云端链接、数据到功能的构建、Online的运营平台、线下线上的数据采集和标注。
03 VOS车端模块
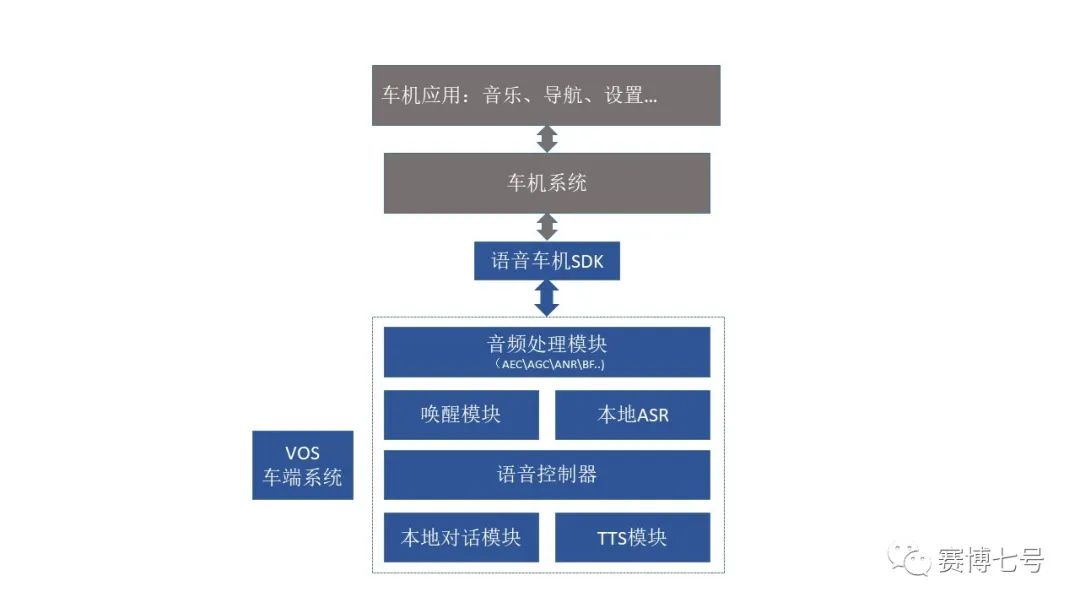
车机端主要是对话系统(DS),也是用户感受最直观的,产品的重点侧向交互设计。
-
音频处理模块:AEC /AGC/ANR/ BF...
-
唤醒模块/本地ASR
-
语音控制器语
-
本地对话系统
-
TTS模块
3.1语音助手
3.2本地对话系统(本地DS)
3.3本地NLU
3.4本地TTS
04 VOS云端系统
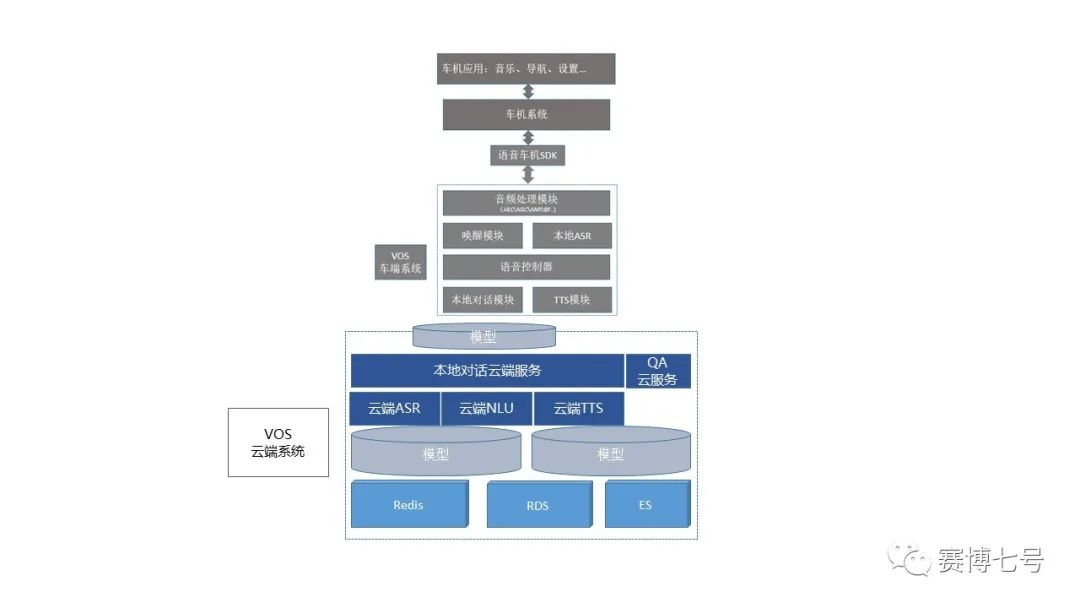
4.1对话系统
-
在线ASR识别 对话服务模块可以接受用户发起的语音对话的音频输入,并给出识别结果。
-
对话 对话服务模块可以接受用户发起的语音对话的文本输入,并给出相应的对话结果,包括TTS文本、要车机进行的操作、车机用来屏显的内容等。
-
其他功能 如向用户进行主动推送等。
4.2模型
4.3云端TTS
云端TTS有别于本地端TTS,基于强大的计算能力,云端使用更大的数据库,技术上使用基于拼接的方案,相比于本地端基于参数合成的TTS,音质更自然;
TTS的声音可以进行定制,需要经过文本设计、发音人确认、录音场地和录音、数据筛选、标注、训练等过程。
05 运营平台
运营平台通过云端和线上对话系统联通,负责以可视化的形式干预对话系统线上的数据和功能。其中主要包含两大类功能:数据运营、功能运营。
5.1数据运营
数据部分的运营主要针对两部分比较常用的可运营数据
1. 针对系统接入的CP/SP的可运营的内容,比如喜马拉雅的推荐数据、黄页数据等等,可以在系统中以手动的方式调整数据的内容、排序等;
2. 针对企业自有的数据,比如主机厂独有的充电桩数据、服务门店数据,可以有机的结合到对话系统中来。
5.2功能运营
功能运营主要是在特定的时间点,比如某些节日、或者有特殊意义的日子、或者临时发生一些事件的时候,通过快速干预某些特定的说法的反馈,通过编辑特定说法的TTS回复,来实现系统对特殊情况的特殊处理。
06 训练及分析
6.1用户数据统计分析
用户数据统计分析系统,通过对所有实车用户使用车载语音的情况进行统计分析,能够得出不同维度、不同粒度的分析报表。定期进行报表的解读和分析,可用得出的结论来指导系统功能的改进。
6.2训练系统
针对音频、文本、图像的采集+标注系统,企业通过定期常规的对线上数据的回收、标注和不定期的对特殊要求数据的采集、标注,生产出各个AI模型需要的数据,提供模型训练支持;每次模型训练完毕会有迭代上线,从而实现训练数据系统和线上模型的一个闭环迭代,不断的提升整体的语音产品的能力。
以上便是对智能座舱车载语音系统的完整介绍
如果你想更快入行智能汽车行业,欢迎关注我们推出的《智能座舱产品特训营》课程,帮你铺平产品之路。最新一期8月20号准时开课。
1)在今天的就业形式下,泛泛而谈/隔行授课的课程很难具备实际价值。前两年招聘的敞口大,或许有点帮助,今天不行了。所以,我们是一种采用重交付,22节直播课,拿公司真实项目,带着大家练,以练带学,让大家上班就能上手干活;
2)还是基于现在的就业形势,不太可能内推很多人了(学员每个人都会内推)。但10个人左右的小班的话,培训扎实一些,内推过去成功率会高很多。
3)费用和成本。人数多了对于学员意义不大,人数少了我们边际成本很高。只能提高费用(我的认知里付费是人生最低成本最捷径的升级方式),我们能覆盖时间成本,学员能提高效率和学习质量。
4.我们彼此最宝贵的是时间⌛️
基于以上几点吧,所以有了以下的课程体系设计(内含课程大纲和详细的课表)大家感兴趣的可以找我私聊:xuelaoban667