
一文读懂无处不在的智能推荐系统

对于智能推荐系统相信大家已经不再陌生了,现在它已经在内容分发平台、电商、广告、音视频等互联网产品中随处可见。
为什么越来越多的产品需要推荐系统?主要有以下两方面的原因:
信息过载
互联网上每天都在产生海量的信息,用户想要迅速和准确地找到他们感兴趣的内容或商品越来越困难。如果用户的目标明确,他可以使用搜索(其实搜索也是有关键字的推荐、推荐是无关键字的搜索),但很多时候我们的用户是没有明确目标的,这时候如果产品能够高效匹配用户感兴趣的内容或商品,就能提高用户体验和粘性,获取更多的商业利益。
长尾效应
绝大多数用户的需求往往是关注主流内容和商品,而忽略相对冷门的大量“长尾”信息, 导致很多优秀的内容或商品没有机会被用户发现和关注。如果大量长尾信息无法获取到流量,信息生产者就会离开平台,影响平台生态的健康发展。(如果想了解更多长尾的相关知识,可以点击下方的链接)
1.认识推荐系统
既然推荐系统如此重要,那推荐系统到底是什么呢?世界是一个数字化的大网,从人类角度来看里面只有两类节点:人和其他。万事万物有相互连接的大趋势,比如人和人倾向于有更多社会连接,于是有了各种社交产品;比如人和商品有越来越多的消费连接,于是有了各种电商产品;人和资讯有越来越多的阅读连接,于是有了信息流产品。推荐系统本质上处理的是信息,它的主要作用是在信息生产方和信息消费方之间搭建起桥梁,从而获取人的注意力。
推荐系统定义:推荐系统是人与信息的连接器,用已有的连接去预测未来用户和物品之间会出现的连接。
下面是个人绘制的推荐系统架构图,一个完整的推荐系统通常由以下部分组成:用户端前台展示、后台日志系统、推荐算法引擎。
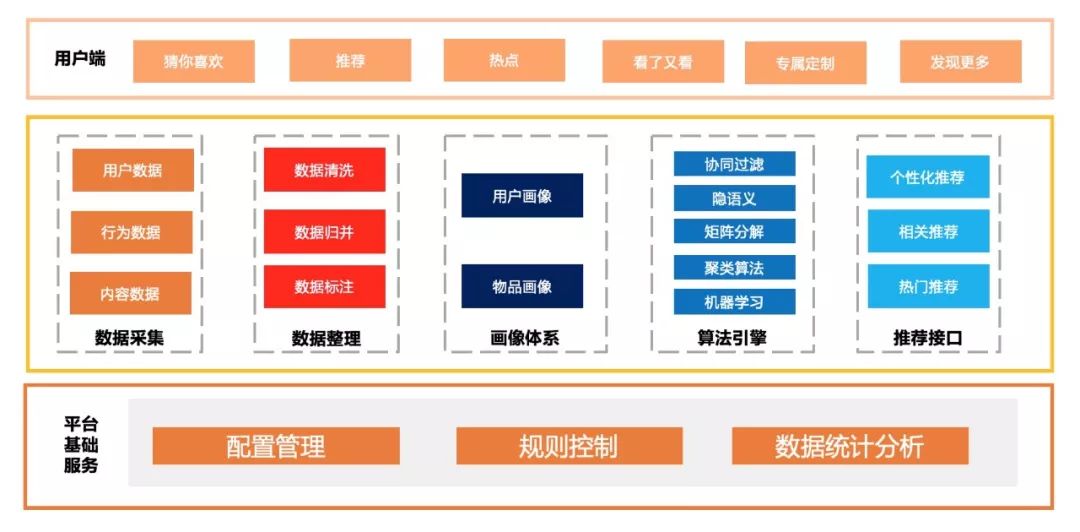
前台展示:就是你在app或网页上看到的推荐、猜你喜欢、你的个性化歌单、经常一起购买的商品等部分展示的内容。
后台日志系统:用户数据、用户行为数据、内容数据等日志数据采集、存储、清洗和分析,从而建立画像体系,包括用户画像和物品画像。
推荐算法引擎:各种算法模型、模型训练配置、推荐效果评估体系。
那要搭建一个推荐系统,需要哪些投入呢?首先要搭建团队,其中算法工程师是必不可少的,当前也是薪酬较高的;其次还要购置存储和计算资源,如果不是云产品你可能还要自己购置硬件设备;然后还有长时间的数据积累和算法优化。推荐系统是一个需要长期持续投入的东西,从投入/产出比和时间成本上来说,产品经理不要随便拍大腿就要做一个智能推荐系统。那如何判断一个产品需不需要推荐系统呢?
第一,看看产品的目的。如果一款产品的目的是建立越多连接越好,那么它最终需要一个推荐系统。有哪些产品的目的不是建立连接呢?一种典型的产品就是工具类,如果是单纯提高人类某些工作的效率而存在的产品,比如AXURE、ERP,则不需要。虽然如今很多产品都从工具切入想做成社区,但至少在工具属性很强时不需要推荐系统。
第二,看看产品现有的连接。如果你的产品中物品很少,少到用人工就可以应付过来,那么用户产生的连接肯定不多,因为连接数量的瓶颈在于物品的数量,这时候不适合搭建推荐系统。应该要有长尾效应才可能让推荐系统发挥效果。
2.推荐算法
要说推荐系统里最经典的算法,那非协同过滤莫属。协同过滤又称基于领域的算法,核心在于协同,互帮互助。其又可以分为两类:基于用户的协同过滤算法(UserCF)、基于物品的协同过滤算法(ItemCF)。
基于用户的协同过滤算法(UserCF)
你有没有和一个人有相见恨晚的感觉,你们有很多共同的爱好,听相同风格的音乐、喜欢读同类型的书......当你自己播放器里的音乐听到腻了的时候,是不是很想问一下这个人有没有什么好听的音乐推荐,这就是经典的基于用户的协同过滤。以前你想找这样一个人可能很难,但是现在互联网的智能推荐系统可以很容易地帮你找到这个人,而且不用你去问,他会主动告诉你我最近听了什么音乐,特别好,你要不要试试鸭?
当一个用户需要个性化推荐时,可以先通过用户的相似度计算找到和他有相似兴趣的其他用户,然后把那些用户喜欢而他没有听说过的物品推荐给他,这种方法称为基于用户的协同过滤算法。
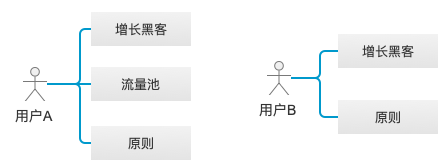
如用户A曾经看过《增长黑客》、《流量池》和《原则》,用户B曾经看过《增长黑客》和《原则》,当我们给B推荐时,推荐系统计算出A和B的相似度比较高,而A曾经读过的《流量池》用户B没有读过,因此就将《流量池》推荐给B用户,这就是经典的基于用户的协同过滤
由上面的描述可知,基于用户的协同过滤算法主要包括两个步骤:
(1)找到和目标用户兴趣相似的用户集合;
(2)找到这个集合中的用户喜欢的,且目标用户没有听说过的物品推荐给目标用户。
基于物品的协同过滤算法(ItemCF)
介绍基于物品的协同过滤之前,先来看下基于用户的协同过滤可能带来的问题。
-
用户数据量比较大时,需要计算的用户之间的相似度会比较多,计算量大。
-
构建用户向量时是使用用户对已消费过的物品的评分/行为来构建的,用户的兴趣是会随时间改变的,导致计算相似用户的频率较高。
-
数据比较稀疏,用户和用户之间有共同的消费行为实际上是比较少的,而且一般都是一些热门物品,对发现用户兴趣帮助也不大。
基于物品的协同过滤算法给用户推荐那些和他们之前喜欢的物品相似的物品。
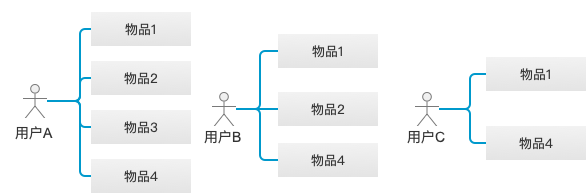
用户A、B和C分别喜欢的物品如图所示,则计算物品2与物品1的相似度的公式为:
物品2与物品1的相似度=同时喜欢物品1和物品2的用户数/喜欢物品1的用户数=2/3;
物品3与物品1的相似度=0;
物品4与物品1的相似度=1。
如果对一个喜欢了物品1的用户D进行推荐,则推荐的优先级为4>2>3。
基于物品的协同过滤算法主要包括如下两个步骤:
(1)计算物品之间的相似度;
(2)根据物品的相似度和用户的历史行为给用户生成推荐列表。
以上只是协同过滤算法的基本原理,现实中的算法模型要远比这个复杂,而且很少采用单一模型,基本是组合模型。我也是刚刚才开始做推荐系统,至于更为复杂的矩阵分解、基于机器学习的推荐算法等后续我自己搞明白再单独成文分享给大家。
3.推荐系统的冷启动
根据推荐系统的定义可知,推荐系统需要已有的连接去预测未来用户和物品之间会出现的连接。对于BAT(百度腾讯阿里)、TMD(头条美团滴滴)这样的巨头他们已经积累了大量的用户数据,在某个产品上智能推荐的时候不存在冷启动的问题,但是对于很多没有大量用户数据的产品来说,如何在这种情况下设计推荐系统并且让用户对推荐结果满意,从而愿意使用推荐系统,就是冷启动的问题。
冷启动问题主要分两大类:
用户冷启动
用户冷启动主要解决如何给新用户或者不活跃用户做个性化推荐的问题。当新用户到来时,我们没有他的行为数据,所以也无法根据他的历史行为预测其兴趣,从而无法借此给他做个性化推荐。
物品冷启动
物品冷启动主要解决如何将新的物品或展示次数较少的物品推荐给可能对它感兴趣的用户这一问题。
一般来说,可以参考如下方式来解决冷启动的问题:
1、利用用户注册时提供的年龄、性别等数据做粗粒度的个性化推荐;
2、利用用户的社交网络账号登录(需要用户授权),导入用户在社交网站上的好友信息,然后给用户推荐其好友喜欢的物品;
3、要求新注册用户在首次登录时选择一些兴趣标签,根据收集到的用户兴趣信息,给用户推荐同类的物品;
4、给新用户或不活跃用户推荐热门排行榜,然后等到用户数据收集到一定的时候,再切换为个性化推荐。
4.如何评估推荐系统的效果
推荐系统推荐质量的高低可以通过如下指标进行评估,作为推荐系统的反馈结果他们也是算法模型迭代优化的依据。这些指标有些可以定量计算,有些只能定性描述。
一、预测准确度
准确度表现在用户对推荐内容的点击率,点击后的各种主动行为(购买、分享等),停留时长等。
二、覆盖率
覆盖率是描述一个推荐系统对物品长尾的发掘能力。最简单的定义是,推荐系统推荐出来的物品占总物品的比例。
三、多样性
良好的推荐系统不仅仅能够准确预测用户的喜好,而且能够扩展用户的视野,帮助用户发现那些他们可能会感兴趣,但不那么容易发现的东西。比如你在某个电商网站买了一双鞋子,然后你每次登录这个网站他都给你推荐鞋子,这种情况你就会对推荐系统很失望,这就是典型的不具备多样性。假如知道了用户的喜好,推荐系统大部分给他推荐感兴趣的,小部分去试探新的兴趣是更优的策略。
四、新颖性
新颖的推荐是指给用户推荐那些他们以前没有听说过的物品。
五、惊喜度
如果推荐结果和用户的历史兴趣不相似,但却让用户觉得满意,那么就可以说推荐结果的惊喜度很高。与新颖性的区别是推荐的新颖性仅仅取决于用户是否听说过这个推荐结果。
六、信任度
如果你有两个朋友,一个人你很信任,一个人经常满嘴跑火车,那么如果你信任的朋友推荐你去某个地方旅游,你很有可能听从他的推荐,但如果是那位满嘴跑火车的朋友推荐你去同样的地方旅游,你很有可能不去。这两个人可以看做两个推荐系统,尽管他们的推荐结果相同,但用户却可能产生不同的反应,这就是因为用户对他们有不同的信任度。
七、实时性
推荐系统的实时性,包括两方面:一是实时更新推荐列表满足用户新的行为变化;二是将新加入系统的物品推荐给用户。
八、健壮性
任何能带来利益的算法系统都会被攻击,最典型的案例就是搜索引擎的作弊与反作弊斗争。健壮性衡量了推荐系统抗击作弊的能力。
参考资料:
项亮,《智能推荐实战》;
邢无刀,《推荐系统三十六计》。