
紧跟恺明的步伐:记录一下复现行为识别slowfast模型的全流程(附详细代码)
极市导读
近年来,基于深度学习的人体动作识别的研究越来越多,slowfast模型提出了快慢两通道网络在动作识别数据集上表现十分优异,本文介绍了Slowfast数据准备,如何训练,以及slowfast使用onnx进行推理,着重介绍了Slowfast使用Tensorrt推理,并且使用yolov5和deepsort进行人物追踪,以及使用C++ 部署。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
1.数据准备
1.1 剪裁视频
IN_DATA_DIR 为原始视频数据存放目录,OUT_DATA_DIR为目标视频数据存放目录。这一步保证所有视频长度相同IN_DATA_DIR="/project/train/src_repo/data/video"
OUT_DATA_DIR="/project/train/src_repo/data/splitvideo"
str="_"
if [[ ! -d "${OUT_DATA_DIR}" ]]; then
echo "${OUT_DATA_DIR} doesn't exist. Creating it.";
mkdir -p ${OUT_DATA_DIR}
fi
for video in $(ls -A1 -U ${IN_DATA_DIR}/*)
do
for i in {0..10}
do
index=$(expr $i \* 10)
out_name="${OUT_DATA_DIR}/${i}${str}${video##*/}"
if [ ! -f "${out_name}" ]; then
ffmpeg -ss ${index} -t 80 -i "${video}" "${out_name}"
fi
done
done
1.2 提取关键帧
IN_DATA_DIR为步骤一得到视频的目录,OUT_DATA_DIR为提取的关键帧的存放目录#切割图片,每秒1帧
IN_DATA_DIR="/project/train/src_repo/data/splitvideo/"
OUT_DATA_DIR="/project/train/src_repo/data/splitimages/"
if [[ ! -d "${OUT_DATA_DIR}" ]]; then
echo "${OUT_DATA_DIR} doesn't exist. Creating it.";
mkdir -p ${OUT_DATA_DIR}
fi
for video in $(ls -A1 -U ${IN_DATA_DIR}/*)
do
video_name=${video##*/}
if [[ $video_name = *".webm" ]]; then
video_name=${video_name::-5}
else
video_name=${video_name::-4}
fi
out_video_dir=${OUT_DATA_DIR}/${video_name}/
mkdir -p "${out_video_dir}"
out_name="${out_video_dir}/${video_name}_%06d.jpg"
ffmpeg -i "${video}" -r 1 -q:v 1 "${out_name}"
done
1.3 分割视频
ffmpeg进行分帧,每秒30帧,IN_DATA_DIR为存放视频目录,OUT_DATA_DIR为存放结果目录IN_DATA_DIR="/project/train/src_repo/video"
OUT_DATA_DIR="/project/train/src_repo/spiltvideo"
if [[ ! -d "${OUT_DATA_DIR}" ]]; then
echo "${OUT_DATA_DIR} doesn't exist. Creating it.";
mkdir -p ${OUT_DATA_DIR}
fi
for video in $(ls -A1 -U ${IN_DATA_DIR}/*)
do
out_name="${OUT_DATA_DIR}/${video##*/}"
if [ ! -f "${out_name}" ]; then
ffmpeg -ss 0 -t 100 -i "${video}" "${out_name}"
fi
done
1.4 文件目录
ava #一级文件夹,用来存放视频信息
—person_box_67091280_iou90 #二级文件夹,用来存放目标检测信息文件夹
——ava_detection_train_boxes_and_labels_include_negative_v2.2.csv #二级文件夹下文件,用来存放目标检测的信息,用于训练
——ava_detection_val_boxes_and_labels.csv #二级文件夹下文件,用来存放目标检测的信息,用于测试
—ava_action_list_v2.2_for_activitynet_2019.pbtxt #一级文件夹下的文件,用来存放标签信息
—ava_val_excluded_timestamps_v2.2.csv #一级文件夹下的文件,用来没有人物的帧,在训练过程中会抛弃这些帧
—ava_train_v2.2.csv #一级文件夹下的文件,用来存放训练数据,关键帧的信息
—ava_val_v2.2.csv #一级文件夹下的文件,用来存放验证数据,关键帧的信息
frame_lists #一级文件夹,存放1.3中生成的图片的路径
—train.csv
—val.csv
frames #一级文件夹,存放1.3中生成的图片
—A
——A_000001.jpg
——A_0000012.jpg
…
——A_000090.jpg
—B
——B_000001.jpg
——B_0000012.jpg
…
——B_000090.jpg
2.环境准备
2.1 环境准备
pip install iopath
pip install fvcore
pip install simplejson
pip install pytorchvideo
2.2 detectron2 安装
!python -m pip install pyyaml==5.1
import sys, os, distutils.core
# Note: This is a faster way to install detectron2 in Colab, but it does not include all functionalities.
# See https://detectron2.readthedocs.io/tutorials/install.html for full installation instructions
!git clone 'https://github.com/facebookresearch/detectron2'
dist = distutils.core.run_setup("./detectron2/setup.py")
!python -m pip install {' '.join([f"'{x}'" for x in dist.install_requires])}
sys.path.insert(0, os.path.abspath('./detectron2'))
3.slowfast 训练
3.1 训练
python tools/run_net.py --cfg configs/AVA/SLOWFAST_32x2_R50_SHORT.yaml
SLOWFAST_32x2_R50_SHORT.yamlTRAIN:
ENABLE: Fasle
DATASET: ava
BATCH_SIZE: 8 #64
EVAL_PERIOD: 5
CHECKPOINT_PERIOD: 1
AUTO_RESUME: True
CHECKPOINT_FILE_PATH: '/content/SLOWFAST_32x2_R101_50_50.pkl' #预训练模型地址
CHECKPOINT_TYPE: pytorch
DATA:
NUM_FRAMES: 32
SAMPLING_RATE: 2
TRAIN_JITTER_SCALES: [256, 320]
TRAIN_CROP_SIZE: 224
TEST_CROP_SIZE: 224
INPUT_CHANNEL_NUM: [3, 3]
PATH_TO_DATA_DIR: '/content/ava'
DETECTION:
ENABLE: True
ALIGNED: True
AVA:
FRAME_DIR: '/content/ava/frames' #数据准备阶段生成的目录
FRAME_LIST_DIR: '/content/ava/frame_lists'
ANNOTATION_DIR: '/content/ava/annotations'
DETECTION_SCORE_THRESH: 0.5
FULL_TEST_ON_VAL: True
TRAIN_PREDICT_BOX_LISTS: [
"ava_train_v2.2.csv",
"person_box_67091280_iou90/ava_detection_train_boxes_and_labels_include_negative_v2.2.csv",
]
TEST_PREDICT_BOX_LISTS: [
"person_box_67091280_iou90/ava_detection_val_boxes_and_labels.csv"]
SLOWFAST:
ALPHA: 4
BETA_INV: 8
FUSION_CONV_CHANNEL_RATIO: 2
FUSION_KERNEL_SZ: 7
RESNET:
ZERO_INIT_FINAL_BN: True
WIDTH_PER_GROUP: 64
NUM_GROUPS: 1
DEPTH: 50
TRANS_FUNC: bottleneck_transform
STRIDE_1X1: False
NUM_BLOCK_TEMP_KERNEL: [[3, 3], [4, 4], [6, 6], [3, 3]]
SPATIAL_DILATIONS: [[1, 1], [1, 1], [1, 1], [2, 2]]
SPATIAL_STRIDES: [[1, 1], [2, 2], [2, 2], [1, 1]]
NONLOCAL:
LOCATION: [[[], []], [[], []], [[], []], [[], []]]
GROUP: [[1, 1], [1, 1], [1, 1], [1, 1]]
INSTANTIATION: dot_product
POOL: [[[1, 2, 2], [1, 2, 2]], [[1, 2, 2], [1, 2, 2]], [[1, 2, 2], [1, 2, 2]], [[1, 2, 2], [1, 2, 2]]]
BN:
USE_PRECISE_STATS: False
NUM_BATCHES_PRECISE: 20
SOLVER:
BASE_LR: 0.1
LR_POLICY: steps_with_relative_lrs
STEPS: [0, 10, 15, 20]
LRS: [1, 0.1, 0.01, 0.001]
MAX_EPOCH: 20
MOMENTUM: 0.9
WEIGHT_DECAY: 1e-7
WARMUP_EPOCHS: 5.0
WARMUP_START_LR: 0.000125
OPTIMIZING_METHOD: sgd
MODEL:
NUM_CLASSES: 1
ARCH: slowfast
MODEL_NAME: SlowFast
LOSS_FUNC: bce
DROPOUT_RATE: 0.5
HEAD_ACT: sigmoid
TEST:
ENABLE: False
DATASET: ava
BATCH_SIZE: 8
DATA_LOADER:
NUM_WORKERS: 0
PIN_MEMORY: True
NUM_GPUS: 1
NUM_SHARDS: 1
RNG_SEED: 0
OUTPUT_DIR: .
3.2 训练过程常见报错
slowfast/datasets/ava_helper.py 中AVA_VALID_FRAMES改为你的视频长度pytorchvideo.layers.distributed报错from pytorchvideo.layers.distributed import ( # noqa
ImportError: cannot import name 'cat_all_gather' from 'pytorchvideo.layers.distributed'
(/site-packages/pytorchvideo/layers/distributed.py)
pytorchvideo.losses 报错File "SlowFast/slowfast/models/losses.py", line 11, in
from pytorchvideo.losses.soft_target_cross_entropy import (
ModuleNotFoundError: No module named 'pytorchvideo.losses'
4.slowfast 预测
python tools/run_net.py --cfg demo/AVA/SLOWFAST_32x2_R101_50_50.yaml
detectron2安装问题,以及之后部署一系列的问题,可以使用yolov5加上slowfast进行推理slowfast的推理过程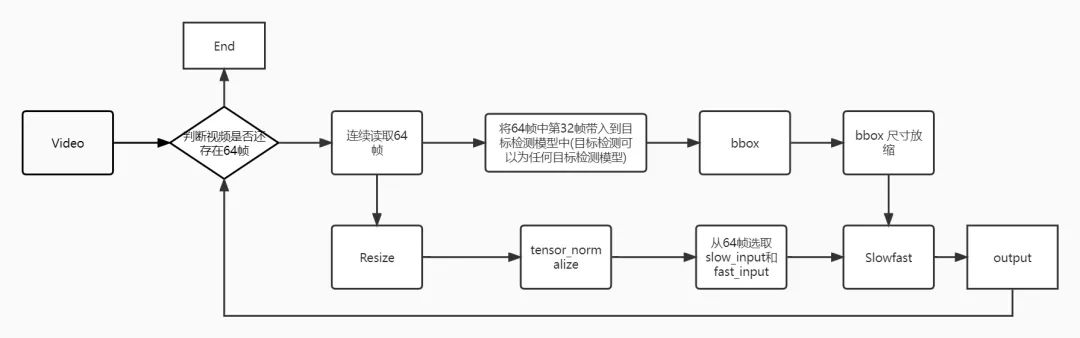
while was_read:
frames=[]
seq_length=64
while was_read and len(frames) < seq_length:
was_read, frame =cap.read()
frames.append(frame)
yolov5 推理代码,将sys.path.insert路径和权重路径weights进行更改import argparse
import os
import platform
import shutil
import time
from pathlib import Path
import sys
import json
sys.path.insert(1, '/content/drive/MyDrive/yolov5/')
import cv2
import torch
import torch.backends.cudnn as cudnn
import numpy as np
import argparse
import time
import cv2
import torch
import torch.backends.cudnn as cudnn
from numpy import random
from models.common import DetectMultiBackend
from utils.augmentations import letterbox
from utils.general import check_img_size, non_max_suppression, scale_coords, set_logging
from utils.torch_utils import select_device
# ####### 参数设置
conf_thres = 0.6
iou_thres = 0.5
#######
imgsz = 640
weights = "/content/yolov5l.pt"
device = '0'
stride = 32
names = ["person"]
import os
def init():
# Initialize
global imgsz, device, stride
set_logging()
device = select_device('0')
half = device.type != 'cpu' # half precision only supported on CUDA
model = DetectMultiBackend(weights, device=device, dnn=False)
stride, pt, jit, engine = model.stride, model.pt, model.jit, model.engine
imgsz = check_img_size(imgsz, s=stride) # check img_size
model.half() # to FP16
model.eval()
return model
def process_image(model, input_image=None, args=None, **kwargs):
img0 = input_image
img = letterbox(img0, new_shape=imgsz, stride=stride, auto=True)[0]
img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
img = np.ascontiguousarray(img)
img = torch.from_numpy(img).to(device)
img = img.half()
img /= 255.0 # 0 - 255 to 0.0 - 1.0
if len(img.shape) == 3:
img = img[None]
pred = model(img, augment=False, val=True)[0]
pred = non_max_suppression(pred, conf_thres, iou_thres, agnostic=False)
result=[]
for i, det in enumerate(pred): # detections per image
gn = torch.tensor(img0.shape)[[1, 0, 1, 0]] # normalization gain whwh
if det is not None and len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], img0.shape).round()
for *xyxy, conf, cls in det:
if cls==0:
result.append([float(xyxy[0]),float(xyxy[1]),float(xyxy[2]),float(xyxy[3])])
if len(result)==0:
return None
return torch.from_numpy(np.array(result))
.bbox 预处理def scale_boxes(size, boxes, height, width):
"""
Scale the short side of the box to size.
Args:
size (int): size to scale the image.
boxes (ndarray): bounding boxes to peform scale. The dimension is
`num boxes` x 4.
height (int): the height of the image.
width (int): the width of the image.
Returns:
boxes (ndarray): scaled bounding boxes.
"""
if (width <= height and width == size) or (
height <= width and height == size
):
return boxes
new_width = size
new_height = size
if width < height:
new_height = int(math.floor((float(height) / width) * size))
boxes *= float(new_height) / height
else:
new_width = int(math.floor((float(width) / height) * size))
boxes *= float(new_width) / width
return boxes
Resize 图像尺寸def scale(size, image):
"""
Scale the short side of the image to size.
Args:
size (int): size to scale the image.
image (array): image to perform short side scale. Dimension is
`height` x `width` x `channel`.
Returns:
(ndarray): the scaled image with dimension of
`height` x `width` x `channel`.
"""
height = image.shape[0]
width = image.shape[1]
# print(height,width)
if (width <= height and width == size) or (
height <= width and height == size
):
return image
new_width = size
new_height = size
if width < height:
new_height = int(math.floor((float(height) / width) * size))
else:
new_width = int(math.floor((float(width) / height) * size))
img = cv2.resize(
image, (new_width, new_height), interpolation=cv2.INTER_LINEAR
)
# print(new_width, new_height)
return img.astype(np.float32)
def tensor_normalize(tensor, mean, std, func=None):
"""
Normalize a given tensor by subtracting the mean and dividing the std.
Args:
tensor (tensor): tensor to normalize.
mean (tensor or list): mean value to subtract.
std (tensor or list): std to divide.
"""
if tensor.dtype == torch.uint8:
tensor = tensor.float()
tensor = tensor / 255.0
if type(mean) == list:
mean = torch.tensor(mean)
if type(std) == list:
std = torch.tensor(std)
if func is not None:
tensor = func(tensor)
tensor = tensor - mean
tensor = tensor / std
return tensor
slow以及fast 输入数据fast的输入,再从fast中选取8帧作为slow的输入,并将 T H W C -> C T H W.因此最后fast_pathway维度为(b,3,32,h,w) slow_pathway的维度为(b,3,8,h,w)def process_cv2_inputs(frames):
"""
Normalize and prepare inputs as a list of tensors. Each tensor
correspond to a unique pathway.
Args:
frames (list of array): list of input images (correspond to one clip) in range [0, 255].
cfg (CfgNode): configs. Details can be found in
slowfast/config/defaults.py
"""
inputs = torch.from_numpy(np.array(frames)).float() / 255
inputs = tensor_normalize(inputs, [0.45,0.45,0.45], [0.225,0.225,0.225])
# T H W C -> C T H W.
inputs = inputs.permute(3, 0, 1, 2)
# Sample frames for num_frames specified.
index = torch.linspace(0, inputs.shape[1] - 1, 32).long()
print(index)
inputs = torch.index_select(inputs, 1, index)
fast_pathway = inputs
slow_pathway = torch.index_select(
inputs,
1,
torch.linspace(
0, inputs.shape[1] - 1, inputs.shape[1] // 4
).long(),
)
frame_list = [slow_pathway, fast_pathway]
print(np.shape(frame_list[0]))
inputs = [inp.unsqueeze(0) for inp in frame_list]
return inputs
5.slowfast onnx 推理
5.1 导出onnx文件
import os
import sys
from collections import OrderedDict
import torch
import argparse
work_root = os.path.split(os.path.realpath(__file__))[0]
from slowfast.config.defaults import get_cfg
import slowfast.utils.checkpoint as cu
from slowfast.models import build_model
def parser_args():
parser = argparse.ArgumentParser()
parser.add_argument(
"--cfg",
dest="cfg_file",
type=str,
default=os.path.join(
work_root, "/content/drive/MyDrive/SlowFast/demo/AVA/SLOWFAST_32x2_R101_50_50.yaml"),
help="Path to the config file",
)
parser.add_argument(
'--half',
type=bool,
default=False,
help='use half mode',
)
parser.add_argument(
'--checkpoint',
type=str,
default=os.path.join(work_root,
"/content/SLOWFAST_32x2_R101_50_50.pkl"),
help='test model file path',
)
parser.add_argument(
'--save',
type=str,
default=os.path.join(work_root, "/content/SLOWFAST_head.onnx"),
help='save model file path',
)
return parser.parse_args()
def main():
args = parser_args()
print(args)
cfg_file = args.cfg_file
checkpoint_file = args.checkpoint
save_checkpoint_file = args.save
half_flag = args.half
cfg = get_cfg()
cfg.merge_from_file(cfg_file)
cfg.TEST.CHECKPOINT_FILE_PATH = checkpoint_file
print(cfg.DATA)
print("export pytorch model to onnx!\n")
device = "cuda:0"
with torch.no_grad():
model = build_model(cfg)
model = model.to(device)
model.eval()
cu.load_test_checkpoint(cfg, model)
if half_flag:
model.half()
fast_pathway= torch.randn(1, 3, 32, 256, 455)
slow_pathway= torch.randn(1, 3, 8, 256, 455)
bbox=torch.randn(32,5).to(device)
fast_pathway = fast_pathway.to(device)
slow_pathway = slow_pathway.to(device)
inputs = [slow_pathway, fast_pathway]
for p in model.parameters():
p.requires_grad = False
torch.onnx.export(model, (inputs,bbox), save_checkpoint_file, input_names=['slow_pathway','fast_pathway','bbox'],output_names=['output'], opset_version=12)
onnx_check()
def onnx_check():
import onnx
args = parser_args()
print(args)
onnx_model_path = args.save
model = onnx.load(onnx_model_path)
onnx.checker.check_model(model)
if __name__ == '__main__':
main()
5.2 onnx 推理
import torch
import math
import onnxruntime
from torchvision.ops import roi_align
import argparse
import os
import platform
import shutil
import time
from pathlib import Path
import sys
import json
sys.path.insert(1, '/content/drive/MyDrive/yolov5/')
import cv2
import torch
import torch.backends.cudnn as cudnn
import numpy as np
import argparse
import time
import cv2
import torch
import torch.backends.cudnn as cudnn
from numpy import random
from models.common import DetectMultiBackend
from utils.augmentations import letterbox
from utils.general import check_img_size, non_max_suppression, scale_coords, set_logging
from utils.torch_utils import select_device
# ####### 参数设置
conf_thres = 0.6
iou_thres = 0.5
#######
imgsz = 640
weights = "/content/yolov5l.pt"
device = '0'
stride = 32
names = ["person"]
import os
def init():
# Initialize
global imgsz, device, stride
set_logging()
device = select_device('0')
half = device.type != 'cpu' # half precision only supported on CUDA
model = DetectMultiBackend(weights, device=device, dnn=False)
stride, pt, jit, engine = model.stride, model.pt, model.jit, model.engine
imgsz = check_img_size(imgsz, s=stride) # check img_size
model.half() # to FP16
model.eval()
return model
def process_image(model, input_image=None, args=None, **kwargs):
img0 = input_image
img = letterbox(img0, new_shape=imgsz, stride=stride, auto=True)[0]
img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
img = np.ascontiguousarray(img)
img = torch.from_numpy(img).to(device)
img = img.half()
img /= 255.0 # 0 - 255 to 0.0 - 1.0
if len(img.shape) == 3:
img = img[None]
pred = model(img, augment=False, val=True)[0]
pred = non_max_suppression(pred, conf_thres, iou_thres, agnostic=False)
result=[]
for i, det in enumerate(pred): # detections per image
gn = torch.tensor(img0.shape)[[1, 0, 1, 0]] # normalization gain whwh
if det is not None and len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], img0.shape).round()
for *xyxy, conf, cls in det:
if cls==0:
result.append([float(xyxy[0]),float(xyxy[1]),float(xyxy[2]),float(xyxy[3])])
if len(result)==0:
return None
for i in range(32-len(result)):
result.append([float(0),float(0),float(0),float(0)])
return torch.from_numpy(np.array(result))
def scale(size, image):
"""
Scale the short side of the image to size.
Args:
size (int): size to scale the image.
image (array): image to perform short side scale. Dimension is
`height` x `width` x `channel`.
Returns:
(ndarray): the scaled image with dimension of
`height` x `width` x `channel`.
"""
height = image.shape[0]
width = image.shape[1]
# print(height,width)
if (width <= height and width == size) or (
height <= width and height == size
):
return image
new_width = size
new_height = size
if width < height:
new_height = int(math.floor((float(height) / width) * size))
else:
new_width = int(math.floor((float(width) / height) * size))
img = cv2.resize(
image, (new_width, new_height), interpolation=cv2.INTER_LINEAR
)
# print(new_width, new_height)
return img.astype(np.float32)
def tensor_normalize(tensor, mean, std, func=None):
"""
Normalize a given tensor by subtracting the mean and dividing the std.
Args:
tensor (tensor): tensor to normalize.
mean (tensor or list): mean value to subtract.
std (tensor or list): std to divide.
"""
if tensor.dtype == torch.uint8:
tensor = tensor.float()
tensor = tensor / 255.0
if type(mean) == list:
mean = torch.tensor(mean)
if type(std) == list:
std = torch.tensor(std)
if func is not None:
tensor = func(tensor)
tensor = tensor - mean
tensor = tensor / std
return tensor
def scale_boxes(size, boxes, height, width):
"""
Scale the short side of the box to size.
Args:
size (int): size to scale the image.
boxes (ndarray): bounding boxes to peform scale. The dimension is
`num boxes` x 4.
height (int): the height of the image.
width (int): the width of the image.
Returns:
boxes (ndarray): scaled bounding boxes.
"""
if (width <= height and width == size) or (
height <= width and height == size
):
return boxes
new_width = size
new_height = size
if width < height:
new_height = int(math.floor((float(height) / width) * size))
boxes *= float(new_height) / height
else:
new_width = int(math.floor((float(width) / height) * size))
boxes *= float(new_width) / width
return boxes
def process_cv2_inputs(frames):
"""
Normalize and prepare inputs as a list of tensors. Each tensor
correspond to a unique pathway.
Args:
frames (list of array): list of input images (correspond to one clip) in range [0, 255].
cfg (CfgNode): configs. Details can be found in
slowfast/config/defaults.py
"""
inputs = torch.from_numpy(np.array(frames)).float() / 255
inputs = tensor_normalize(inputs, [0.45,0.45,0.45], [0.225,0.225,0.225])
# T H W C -> C T H W.
inputs = inputs.permute(3, 0, 1, 2)
# Sample frames for num_frames specified.
index = torch.linspace(0, inputs.shape[1] - 1, 32).long()
print(index)
inputs = torch.index_select(inputs, 1, index)
fast_pathway = inputs
slow_pathway = torch.index_select(
inputs,
1,
torch.linspace(
0, inputs.shape[1] - 1, inputs.shape[1] // 4
).long(),
)
frame_list = [slow_pathway, fast_pathway]
print(np.shape(frame_list[0]))
inputs = [inp.unsqueeze(0) for inp in frame_list]
return inputs
#加载模型
yolov5=init()
slowfast = onnxruntime.InferenceSession('/content/SLOWFAST_32x2_R101_50_50.onnx')
#加载数据开始推理
cap = cv2.VideoCapture("/content/atm_125.mp4")
was_read=True
while was_read:
frames=[]
seq_length=64
while was_read and len(frames) < seq_length:
was_read, frame =cap.read()
frames.append(frame)
bboxes = process_image(yolov5,frames[64//2])
if bboxes is not None:
frames = [cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) for frame in frames]
frames = [scale(256, frame) for frame in frames]
inputs = process_cv2_inputs(frames)
if bboxes is not None:
bboxes = scale_boxes(256,bboxes,1080,1920)
index_pad = torch.full(
size=(bboxes.shape[0], 1),
fill_value=float(0),
device=bboxes.device,
)
# Pad frame index for each box.
bboxes = torch.cat([index_pad, bboxes], axis=1)
for i in range(len(inputs)):
inputs[i] = inputs[i].numpy()
if bboxes is not None:
outputs = slowfast.run(None, {'slow_pathway': inputs[0],'fast_pathway':inputs[1],'bbox':bboxes})
for i in range(80):
if outputs[0][0][i]>0.3:
print(i)
print(np.shape(prd))
else:
print("没有检测到任何人物")
6 slowfast python Tensorrt 推理
6.1 导出Tensorrt
onnx导出为Tensorrt,导出失败,查找原因是因为roi_align在Tensorrt中还未实现(roi_align 将在下个版本的Tensorrt中实现)。onnx图,会发现roi_align只在head部分用到。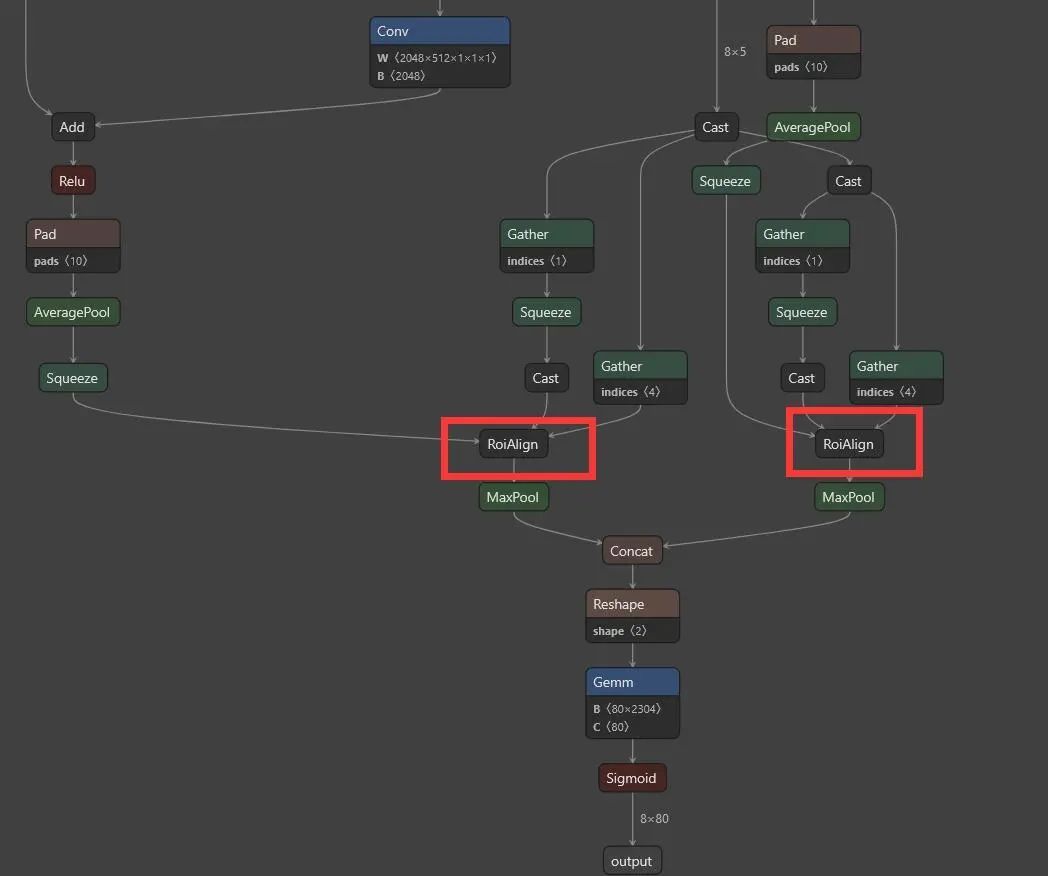
roi_ailgn模块单独划分出来,不经过Tensorrt加速,将slowfast分成为两个网络,其中主体网络用于提取特征,head网络部分负责进行动作分类.。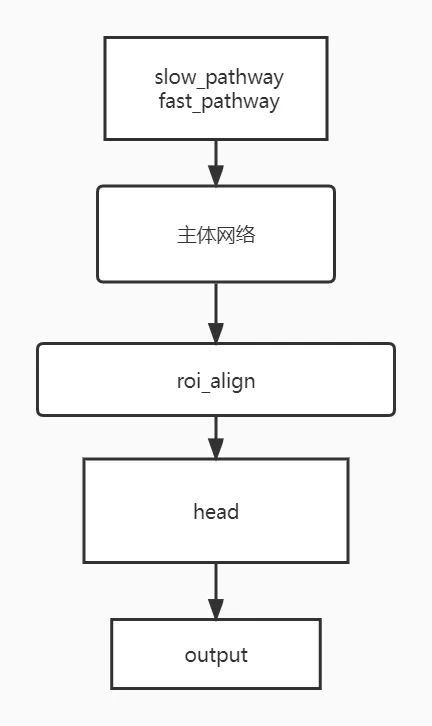
6.2 Tensorrt推理代码
import ctypes
import os
import numpy as np
import cv2
import random
import tensorrt as trt
import pycuda.autoinit
import pycuda.driver as cuda
import threading
import time
class TrtInference():
_batch_size = 1
def __init__(self, model_path=None, cuda_ctx=None):
self._model_path = model_path
if self._model_path is None:
print("please set trt model path!")
exit()
self.cuda_ctx = cuda_ctx
if self.cuda_ctx is None:
self.cuda_ctx = cuda.Device(0).make_context()
if self.cuda_ctx:
self.cuda_ctx.push()
self.trt_logger = trt.Logger(trt.Logger.INFO)
self._load_plugins()
self.engine = self._load_engine()
try:
self.context = self.engine.create_execution_context()
self.stream = cuda.Stream()
for index, binding in enumerate(self.engine):
if self.engine.binding_is_input(binding):
batch_shape = list(self.engine.get_binding_shape(binding)).copy()
batch_shape[0] = self._batch_size
self.context.set_binding_shape(index, batch_shape)
self.host_inputs, self.host_outputs, self.cuda_inputs, self.cuda_outputs, self.bindings = self._allocate_buffers()
except Exception as e:
raise RuntimeError('fail to allocate CUDA resources') from e
finally:
if self.cuda_ctx:
self.cuda_ctx.pop()
def _load_plugins(self):
pass
def _load_engine(self):
with open(self._model_path, 'rb') as f, trt.Runtime(self.trt_logger) as runtime:
return runtime.deserialize_cuda_engine(f.read())
def _allocate_buffers(self):
host_inputs, host_outputs, cuda_inputs, cuda_outputs, bindings = \
[], [], [], [], []
for index, binding in enumerate(self.engine):
size = trt.volume(self.context.get_binding_shape(index)) * \
self.engine.max_batch_size
host_mem = cuda.pagelocked_empty(size, np.float32)
cuda_mem = cuda.mem_alloc(host_mem.nbytes)
bindings.append(int(cuda_mem))
if self.engine.binding_is_input(binding):
host_inputs.append(host_mem)
cuda_inputs.append(cuda_mem)
else:
host_outputs.append(host_mem)
cuda_outputs.append(cuda_mem)
return host_inputs, host_outputs, cuda_inputs, cuda_outputs, bindings
def destroy(self):
"""Free CUDA memories and context."""
del self.cuda_outputs
del self.cuda_inputs
del self.stream
if self.cuda_ctx:
self.cuda_ctx.pop()
del self.cuda_ctx
def inference(self, inputs):
np.copyto(self.host_inputs[0], inputs[0].ravel())
np.copyto(self.host_inputs[1], inputs[1].ravel())
if self.cuda_ctx:
self.cuda_ctx.push()
cuda.memcpy_htod_async(
self.cuda_inputs[0], self.host_inputs[0], self.stream)
cuda.memcpy_htod_async(
self.cuda_inputs[1], self.host_inputs[1], self.stream)
self.context.execute_async(
batch_size=1,
bindings=self.bindings,
stream_handle=self.stream.handle)
cuda.memcpy_dtoh_async(
self.host_outputs[0], self.cuda_outputs[0], self.stream)
cuda.memcpy_dtoh_async(
self.host_outputs[1], self.cuda_outputs[1], self.stream)
self.stream.synchronize()
if self.cuda_ctx:
self.cuda_ctx.pop()
output = [self.host_outputs[0],self.host_outputs[1]]
return output
class TrtInference_head():
_batch_size = 1
def __init__(self, model_path=None, cuda_ctx=None):
self._model_path = model_path
if self._model_path is None:
print("please set trt model path!")
exit()
self.cuda_ctx = cuda_ctx
if self.cuda_ctx is None:
self.cuda_ctx = cuda.Device(0).make_context()
if self.cuda_ctx:
self.cuda_ctx.push()
self.trt_logger = trt.Logger(trt.Logger.INFO)
self._load_plugins()
self.engine = self._load_engine()
try:
self.context = self.engine.create_execution_context()
self.stream = cuda.Stream()
for index, binding in enumerate(self.engine):
if self.engine.binding_is_input(binding):
batch_shape = list(self.engine.get_binding_shape(binding)).copy()
batch_shape[0] = self._batch_size
self.context.set_binding_shape(index, batch_shape)
self.host_inputs, self.host_outputs, self.cuda_inputs, self.cuda_outputs, self.bindings = self._allocate_buffers()
except Exception as e:
raise RuntimeError('fail to allocate CUDA resources') from e
finally:
if self.cuda_ctx:
self.cuda_ctx.pop()
def _load_plugins(self):
pass
def _load_engine(self):
with open(self._model_path, 'rb') as f, trt.Runtime(self.trt_logger) as runtime:
return runtime.deserialize_cuda_engine(f.read())
def _allocate_buffers(self):
host_inputs, host_outputs, cuda_inputs, cuda_outputs, bindings = \
[], [], [], [], []
for index, binding in enumerate(self.engine):
size = trt.volume(self.context.get_binding_shape(index)) * \
self.engine.max_batch_size
host_mem = cuda.pagelocked_empty(size, np.float32)
cuda_mem = cuda.mem_alloc(host_mem.nbytes)
bindings.append(int(cuda_mem))
if self.engine.binding_is_input(binding):
host_inputs.append(host_mem)
cuda_inputs.append(cuda_mem)
else:
host_outputs.append(host_mem)
cuda_outputs.append(cuda_mem)
return host_inputs, host_outputs, cuda_inputs, cuda_outputs, bindings
def destroy(self):
"""Free CUDA memories and context."""
del self.cuda_outputs
del self.cuda_inputs
del self.stream
if self.cuda_ctx:
self.cuda_ctx.pop()
del self.cuda_ctx
def inference(self, inputs):
np.copyto(self.host_inputs[0], inputs[0].ravel())
np.copyto(self.host_inputs[1], inputs[1].ravel())
if self.cuda_ctx:
self.cuda_ctx.push()
cuda.memcpy_htod_async(
self.cuda_inputs[0], self.host_inputs[0], self.stream)
cuda.memcpy_htod_async(
self.cuda_inputs[1], self.host_inputs[1], self.stream)
self.context.execute_async(
batch_size=1,
bindings=self.bindings,
stream_handle=self.stream.handle)
cuda.memcpy_dtoh_async(
self.host_outputs[0], self.cuda_outputs[0], self.stream)
self.stream.synchronize()
if self.cuda_ctx:
self.cuda_ctx.pop()
output = self.host_outputs[0]
return output
import torch
import math
from torchvision.ops import roi_align
import argparse
import os
import platform
import shutil
import time
from pathlib import Path
import sys
import json
sys.path.insert(1, '/content/drive/MyDrive/yolov5/')
import cv2
import torch
import torch.backends.cudnn as cudnn
import numpy as np
import argparse
import time
import cv2
import torch
import torch.backends.cudnn as cudnn
from numpy import random
from models.common import DetectMultiBackend
from utils.augmentations import letterbox
from utils.general import check_img_size, non_max_suppression, scale_coords, set_logging
from utils.torch_utils import select_device
# ####### 参数设置
conf_thres = 0.89
iou_thres = 0.5
#######
imgsz = 640
weights = "/content/yolov5l.pt"
device = '0'
stride = 32
names = ["person"]
import os
def init():
# Initialize
global imgsz, device, stride
set_logging()
device = select_device('0')
half = device.type != 'cpu' # half precision only supported on CUDA
model = DetectMultiBackend(weights, device=device, dnn=False)
stride, pt, jit, engine = model.stride, model.pt, model.jit, model.engine
imgsz = check_img_size(imgsz, s=stride) # check img_size
model.half() # to FP16
model.eval()
return model
def process_image(model, input_image=None, args=None, **kwargs):
img0 = input_image
img = letterbox(img0, new_shape=imgsz, stride=stride, auto=True)[0]
img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
img = np.ascontiguousarray(img)
img = torch.from_numpy(img).to(device)
img = img.half()
img /= 255.0 # 0 - 255 to 0.0 - 1.0
if len(img.shape) == 3:
img = img[None]
pred = model(img, augment=False, val=True)[0]
pred = non_max_suppression(pred, conf_thres, iou_thres, agnostic=False)
result=[]
for i, det in enumerate(pred): # detections per image
gn = torch.tensor(img0.shape)[[1, 0, 1, 0]] # normalization gain whwh
if det is not None and len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], img0.shape).round()
for *xyxy, conf, cls in det:
if cls==0:
result.append([float(xyxy[0]),float(xyxy[1]),float(xyxy[2]),float(xyxy[3])])
if len(result)==0:
return None
for i in range(32-len(result)):
result.append([float(0),float(0),float(0),float(0)])
return torch.from_numpy(np.array(result))
def scale(size, image):
"""
Scale the short side of the image to size.
Args:
size (int): size to scale the image.
image (array): image to perform short side scale. Dimension is
`height` x `width` x `channel`.
Returns:
(ndarray): the scaled image with dimension of
`height` x `width` x `channel`.
"""
height = image.shape[0]
width = image.shape[1]
# print(height,width)
if (width <= height and width == size) or (
height <= width and height == size
):
return image
new_width = size
new_height = size
if width < height:
new_height = int(math.floor((float(height) / width) * size))
else:
new_width = int(math.floor((float(width) / height) * size))
img = cv2.resize(
image, (new_width, new_height), interpolation=cv2.INTER_LINEAR
)
# print(new_width, new_height)
return img.astype(np.float32)
def tensor_normalize(tensor, mean, std, func=None):
"""
Normalize a given tensor by subtracting the mean and dividing the std.
Args:
tensor (tensor): tensor to normalize.
mean (tensor or list): mean value to subtract.
std (tensor or list): std to divide.
"""
if tensor.dtype == torch.uint8:
tensor = tensor.float()
tensor = tensor / 255.0
if type(mean) == list:
mean = torch.tensor(mean)
if type(std) == list:
std = torch.tensor(std)
if func is not None:
tensor = func(tensor)
tensor = tensor - mean
tensor = tensor / std
return tensor
def scale_boxes(size, boxes, height, width):
"""
Scale the short side of the box to size.
Args:
size (int): size to scale the image.
boxes (ndarray): bounding boxes to peform scale. The dimension is
`num boxes` x 4.
height (int): the height of the image.
width (int): the width of the image.
Returns:
boxes (ndarray): scaled bounding boxes.
"""
if (width <= height and width == size) or (
height <= width and height == size
):
return boxes
new_width = size
new_height = size
if width < height:
new_height = int(math.floor((float(height) / width) * size))
boxes *= float(new_height) / height
else:
new_width = int(math.floor((float(width) / height) * size))
boxes *= float(new_width) / width
return boxes
def process_cv2_inputs(frames):
"""
Normalize and prepare inputs as a list of tensors. Each tensor
correspond to a unique pathway.
Args:
frames (list of array): list of input images (correspond to one clip) in range [0, 255].
cfg (CfgNode): configs. Details can be found in
slowfast/config/defaults.py
"""
inputs = torch.from_numpy(np.array(frames)).float() / 255
inputs = tensor_normalize(inputs, [0.45,0.45,0.45], [0.225,0.225,0.225])
# T H W C -> C T H W.
inputs = inputs.permute(3, 0, 1, 2)
# Sample frames for num_frames specified.
index = torch.linspace(0, inputs.shape[1] - 1, 32).long()
print(index)
inputs = torch.index_select(inputs, 1, index)
fast_pathway = inputs
slow_pathway = torch.index_select(
inputs,
1,
torch.linspace(
0, inputs.shape[1] - 1, inputs.shape[1] // 4
).long(),
)
frame_list = [slow_pathway, fast_pathway]
print(np.shape(frame_list[0]))
inputs = [inp.unsqueeze(0) for inp in frame_list]
return inputs
#加载模型
yolov5=init()
slowfast = TrtInference('/content/SLOWFAST_32x2_R101_50_50.engine',None)
head = TrtInference_head('/content/SLOWFAST_head.engine',None)
#加载数据开始推理
cap = cv2.VideoCapture("/content/atm_125.mp4")
was_read=True
while was_read:
frames=[]
seq_length=64
while was_read and len(frames) < seq_length:
was_read, frame =cap.read()
frames.append(frame)
bboxes = process_image(yolov5,frames[64//2])
if bboxes is not None:
frames = [cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) for frame in frames]
frames = [scale(256, frame) for frame in frames]
inputs = process_cv2_inputs(frames)
print(bboxes)
if bboxes is not None:
bboxes = scale_boxes(256,bboxes,1080,1920)
index_pad = torch.full(
size=(bboxes.shape[0], 1),
fill_value=float(0),
device=bboxes.device,
)
# Pad frame index for each box.
bboxes = torch.cat([index_pad, bboxes], axis=1)
for i in range(len(inputs)):
inputs[i] = inputs[i].numpy()
if bboxes is not None:
outputs=slowfast.inference(inputs)
outputs[0]=outputs[0].reshape(1,2048,16,29)
outputs[1]=outputs[1].reshape(1,256,16,29)
outputs[0]=torch.from_numpy(outputs[0])
outputs[1]=torch.from_numpy(outputs[1])
outputs[0]=roi_align(outputs[0],bboxes.to(dtype=outputs[0].dtype),7,1.0/16,0,True)
outputs[1]=roi_align(outputs[1],bboxes.to(dtype=outputs[1].dtype),7,1.0/16,0,True)
outputs[0] = outputs[0].numpy()
outputs[1] = outputs[1].numpy()
prd=head.inference(outputs)
prd=prd.reshape(32,80)
for i in range(80):
if prd[0][i]>0.3:
print(i)
else:
print("没有检测到任何人物")
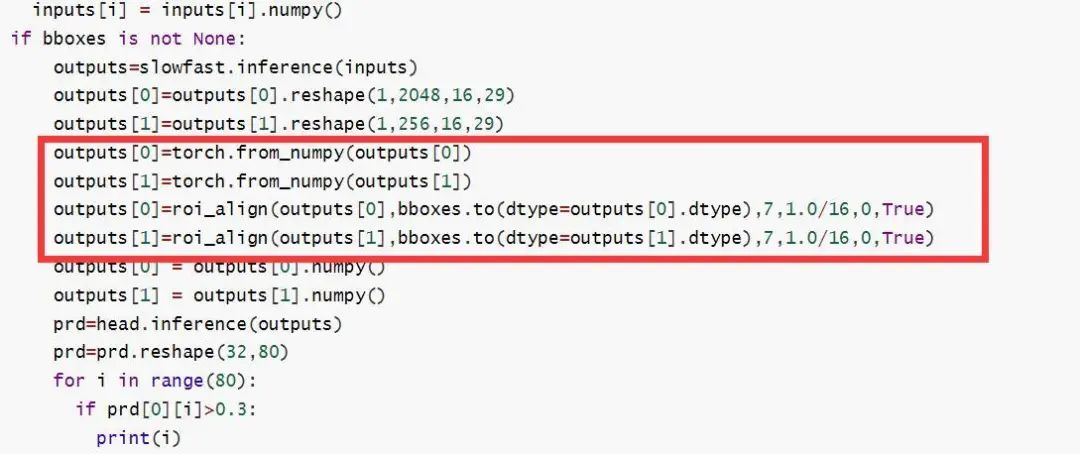
slow_pathway 与fast_pathway 经过slowfast主体模型,通过reshape成roi_align 需要的维度,将reshape后的结果,bbox以及相应的参数带入到roi_align中得到head模型需要的输入。7.slowfast C++ tensorrt 部署
7.1 yolov5 C++ 目标检测
yolov5 本文就不介绍了,我直接使用平台自带的yolov5 tensorrt 代码https://github.com/ExtremeMart/ev_sdk_demo4.0_pedestrian_intrusion_yolov5
7.2 deepsort C++ 目标追踪
deepsort代码https://github.com/RichardoMrMu/deepsort-tensorrt
deepsort#include "deepsort.h"
/**
DeepSortBox 为yolov5识别的结果
DeepSortBox 结构
{
x1,
y1,
x2,
y2,
score,
label,
trackID
}
img 为原始的图片
最终结果存放在DeepSortBox中
*/
DS->sort(img, DeepSortBox);
7.3 slowfast C++ 目标动作识别
Tensorrt8.4opencv4.1.1cudnn8.0cuda11.1body.onnxhead.onnxTensorrt推理代码onnx可视化查看body.onnx输入以及输出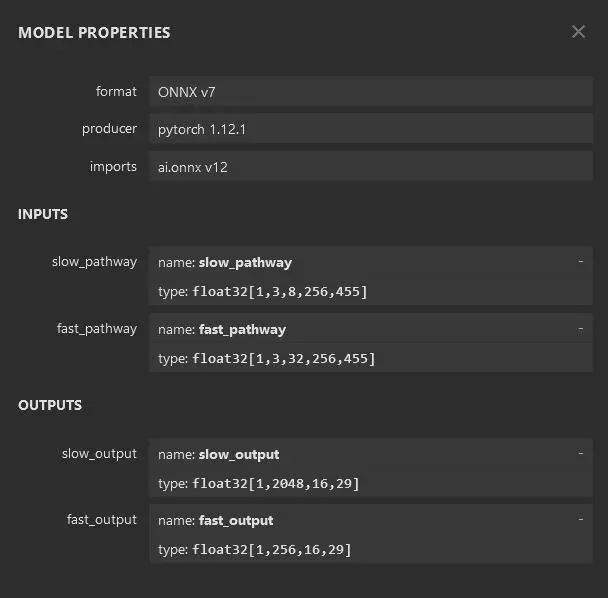
head.onnx的输入以及输出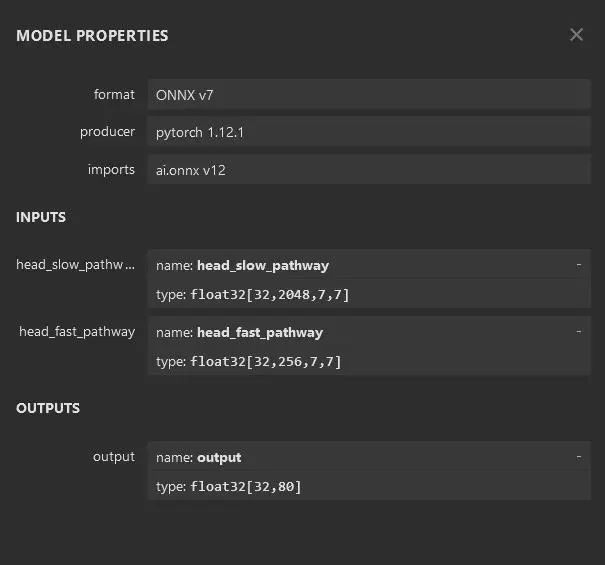
body.onnx以及head.onnx 通过Tensorrt加载,并且开辟Tensorrt推理运行空间,代码如下void loadheadOnnx(const std::string strModelName)
{
Logger gLogger;
//根据tensorrt pipeline 构建网络
IBuilder* builder = createInferBuilder(gLogger);
builder->setMaxBatchSize(1);
const auto explicitBatch = 1U << static_cast<uint32_t>(NetworkDefinitionCreationFlag::kEXPLICIT_BATCH);
INetworkDefinition* network = builder->createNetworkV2(explicitBatch);
nvonnxparser::IParser* parser = nvonnxparser::createParser(*network, gLogger);
parser->parseFromFile(strModelName.c_str(), static_cast<int>(ILogger::Severity::kWARNING));
IBuilderConfig* config = builder->createBuilderConfig();
config->setMaxWorkspaceSize(1ULL << 30);
m_CudaheadEngine = builder->buildEngineWithConfig(*network, *config);
std::string strTrtName = strModelName;
size_t sep_pos = strTrtName.find_last_of(".");
strTrtName = strTrtName.substr(0, sep_pos) + ".trt";
IHostMemory *gieModelStream = m_CudaheadEngine->serialize();
std::string serialize_str;
std::ofstream serialize_output_stream;
serialize_str.resize(gieModelStream->size());
memcpy((void*)serialize_str.data(),gieModelStream->data(),gieModelStream->size());
serialize_output_stream.open(strTrtName.c_str());
serialize_output_stream<<serialize_str;
serialize_output_stream.close();
m_CudaheadContext = m_CudaheadEngine->createExecutionContext();
parser->destroy();
network->destroy();
config->destroy();
builder->destroy();
}
body.onnx 输入为slow_pathway和fast_pathway的维度为(B,C,T,H,W),其中slow_pathway的T为8,输出为(B,2048,16,29),fast_pathway的维度为32,输出为(B,256,16,29)``,head的输入(32,2048,7,7)与(32,256,7,7),输出为(32,80),具体代码实现如下:slow_pathway_InputIndex = m_CudaslowfastEngine->getBindingIndex(slow_pathway_NAME);
fast_pathway_InputIndex = m_CudaslowfastEngine->getBindingIndex(fast_pathway_NAME);
slow_pathway_OutputIndex = m_CudaslowfastEngine->getBindingIndex(slow_pathway_OUTPUT);
fast_pathway_OutputIndex = m_CudaslowfastEngine->getBindingIndex(fast_pathway_OUTPUT);
dims_i = m_CudaslowfastEngine->getBindingDimensions(slow_pathway_InputIndex);
SDKLOG(INFO)<<slow_pathway_InputIndex<<" "<<fast_pathway_InputIndex<<" "<<slow_pathway_OutputIndex<<" "<<fast_pathway_OutputIndex;
SDKLOG(INFO) << "slow_pathway dims " << dims_i.d[0] << " " << dims_i.d[1] << " " << dims_i.d[2] << " " << dims_i.d[3]<< " " << dims_i.d[4];
size = dims_i.d[0] * dims_i.d[1] * dims_i.d[2] * dims_i.d[3]* dims_i.d[4];
cudaMalloc(&slowfast_ArrayDevMemory[slow_pathway_InputIndex], size * sizeof(float));
slowfast_ArrayHostMemory[slow_pathway_InputIndex] = malloc(size * sizeof(float));
slowfast_ArraySize[slow_pathway_InputIndex]=size* sizeof(float);
dims_i = m_CudaslowfastEngine->getBindingDimensions(fast_pathway_InputIndex);
SDKLOG(INFO) << "fast_pathway dims " << dims_i.d[0] << " " << dims_i.d[1] << " " << dims_i.d[2] << " " << dims_i.d[3]<< " " << dims_i.d[4];
size = dims_i.d[0] * dims_i.d[1] * dims_i.d[2] * dims_i.d[3]* dims_i.d[4];
cudaMalloc(&slowfast_ArrayDevMemory[fast_pathway_InputIndex], size * sizeof(float));
slowfast_ArrayHostMemory[fast_pathway_InputIndex] = malloc(size * sizeof(float));
slowfast_ArraySize[fast_pathway_InputIndex]=size* sizeof(float);
dims_i = m_CudaslowfastEngine->getBindingDimensions(slow_pathway_OutputIndex);
SDKLOG(INFO) << "slow_out dims " << dims_i.d[0] << " " << dims_i.d[1] << " " << dims_i.d[2] << " " << dims_i.d[3];
size = dims_i.d[0] * dims_i.d[1] * dims_i.d[2] * dims_i.d[3];
cudaMalloc(&slowfast_ArrayDevMemory[slow_pathway_OutputIndex], size * sizeof(float));
slowfast_ArrayHostMemory[slow_pathway_OutputIndex] = malloc(size * sizeof(float));
slowfast_ArraySize[slow_pathway_OutputIndex]=size* sizeof(float);
dims_i = m_CudaslowfastEngine->getBindingDimensions(fast_pathway_OutputIndex);
SDKLOG(INFO) << "fast_out dims " << dims_i.d[0] << " " << dims_i.d[1] << " " << dims_i.d[2] << " " << dims_i.d[3];
size = dims_i.d[0] * dims_i.d[1] * dims_i.d[2] * dims_i.d[3];
cudaMalloc(&slowfast_ArrayDevMemory[fast_pathway_OutputIndex], size * sizeof(float));
slowfast_ArrayHostMemory[fast_pathway_OutputIndex] = malloc(size * sizeof(float));
slowfast_ArraySize[fast_pathway_OutputIndex]=size* sizeof(float);
size=32*2048*7*7;
cudaMalloc(&ROIAlign_ArrayDevMemory[0], size * sizeof(float));
ROIAlign_ArrayHostMemory[0] = malloc(size * sizeof(float));
ROIAlign_ArraySize[0]=size* sizeof(float);
size=32*256*7*7;
cudaMalloc(&ROIAlign_ArrayDevMemory[1], size * sizeof(float));
ROIAlign_ArrayHostMemory[1] = malloc(size * sizeof(float));
ROIAlign_ArraySize[1]=size* sizeof(float);
size=32*80;
cudaMalloc(&ROIAlign_ArrayDevMemory[2], size * sizeof(float));
ROIAlign_ArrayHostMemory[2] = malloc(size * sizeof(float));
ROIAlign_ArraySize[2]=size* sizeof(float);
size=32*5;
boxes_data= malloc(size * sizeof(float));
dims_i = m_CudaheadEngine->getBindingDimensions(0);
onnx文件没有使用动态尺寸,导致input 图片大小已经确定了,size=256*455(这个结果是1080*1920等比例放缩),slowfast模型要求为RGB,需要将图片从BGR转换为RGB,之后进行resize到256*455,具体代码实现如下cv::Mat framesimg = img.clone();
cv::cvtColor(framesimg, framesimg, cv::COLOR_BGR2RGB);
int height = framesimg.rows;
int width = framesimg.cols;
// 对图像进行预处理
//cv2.COLOR_BGR2RGB
int size=256;
int new_width = width;
int new_height = height;
if ((width <= height && width == size) || (height <= width and height == size)){
}
else{
new_width = size;
new_height = size;
if(width<height){
new_height = int((float(height) / width) * size);
}else{
new_width = int((float(width) / height) * size);
}
cv::resize(framesimg, framesimg, cv::Size{new_width,new_height},cv::INTER_LINEAR);
}
CTHW的顺序进行排列,其中C为通道,T为图像顺序,H 为图像的长度,W为图像的宽度,由于slowfast有两个输入,一个输入为fast_pathway 为32帧的图像,维度为(b,c,T,h,w),其中T为32 ,因此需要每两帧添加图像数据到fast_pathway中,另外一个输入为slow_pathway为8帧的图像,维度为(b,c,T,h,w),其中T为8,因此需要每四帧添加图像数据到slow_pathway 中,具体代码如下float *data=(float *)slowfast_ArrayHostMemory[fast_pathway_InputIndex];
new_width = framesimg.cols;
new_height = framesimg.rows;
for (size_t c = 0; c < 3; c++)
{
for (size_t h = 0; h < new_height; h++)
{
for (size_t w = 0; w < new_width; w++)
{
float v=((float)framesimg.at<cv::Vec3b>(h, w)[c]) / 255.0f;
v -= 0.45;
v /= 0.225;
data[c*32*256*455+fast_index* new_width * new_height + h * new_width + w] =v;
}
}
}
fast_index++;
if(frames==0||frames==8||frames==16||frames==26||frames==34||frames==44||frames==52||frames==63){
data=(float *)slowfast_ArrayHostMemory[slow_pathway_InputIndex];
for (size_t c = 0; c < 3; c++)
{
for (size_t h = 0; h < new_height; h++)
{
for (size_t w = 0; w < new_width; w++)
{
float v=((float)framesimg.at<cv::Vec3b>(h, w)[c]) / 255.0f;
v -= 0.45;
v /= 0.225;
data[c*8*256*455+slow_index* new_width * new_height + h * new_width + w] =v;
}
}
}
slow_index++;
}
roi_align实现void ROIAlignForwardCpu(const float* bottom_data, const float spatial_scale, const int num_rois,
const int height, const int width, const int channels,
const int aligned_height, const int aligned_width, const float * bottom_rois,
float* top_data)
{
const int output_size = num_rois * aligned_height * aligned_width * channels;
int idx = 0;
for (idx = 0; idx < output_size; ++idx)
{
int pw = idx % aligned_width;
int ph = (idx / aligned_width) % aligned_height;
int c = (idx / aligned_width / aligned_height) % channels;
int n = idx / aligned_width / aligned_height / channels;
float roi_batch_ind = 0;
float roi_start_w = bottom_rois[n * 5 + 1] * spatial_scale;
float roi_start_h = bottom_rois[n * 5 + 2] * spatial_scale;
float roi_end_w = bottom_rois[n * 5 + 3] * spatial_scale;
float roi_end_h = bottom_rois[n * 5 + 4] * spatial_scale;
float roi_width = fmaxf(roi_end_w - roi_start_w + 1., 0.);
float roi_height = fmaxf(roi_end_h - roi_start_h + 1., 0.);
float bin_size_h = roi_height / (aligned_height - 1.);
float bin_size_w = roi_width / (aligned_width - 1.);
float h = (float)(ph) * bin_size_h + roi_start_h;
float w = (float)(pw) * bin_size_w + roi_start_w;
int hstart = fminf(floor(h), height - 2);
int wstart = fminf(floor(w), width - 2);
int img_start = roi_batch_ind * channels * height * width;
if (h < 0 || h >= height || w < 0 || w >= width)
{
top_data[idx] = 0.;
}
else
{
float h_ratio = h - (float)(hstart);
float w_ratio = w - (float)(wstart);
int upleft = img_start + (c * height + hstart) * width + wstart;
int upright = upleft + 1;
int downleft = upleft + width;
int downright = downleft + 1;
top_data[idx] = bottom_data[upleft] * (1. - h_ratio) * (1. - w_ratio)
+ bottom_data[upright] * (1. - h_ratio) * w_ratio
+ bottom_data[downleft] * h_ratio * (1. - w_ratio)
+ bottom_data[downright] * h_ratio * w_ratio;
}
}
}
Step3中准备好的数据使用body进行推理,将推理结果使用Step4中的roi_align函数进行提取bbox对应的特征,最后将提取的特征使用head模型进行推理,得到output。具体代码实现如下cudaMemcpyAsync(slowfast_ArrayDevMemory[slow_pathway_InputIndex], slowfast_ArrayHostMemory[slow_pathway_InputIndex], slowfast_ArraySize[slow_pathway_InputIndex], cudaMemcpyHostToDevice, m_CudaStream);
cudaMemcpyAsync(slowfast_ArrayDevMemory[fast_pathway_InputIndex], slowfast_ArrayHostMemory[fast_pathway_InputIndex], slowfast_ArraySize[fast_pathway_InputIndex], cudaMemcpyHostToDevice, m_CudaStream);
m_CudaslowfastContext->enqueueV2(slowfast_ArrayDevMemory , m_CudaStream, nullptr);
cudaMemcpyAsync(slowfast_ArrayHostMemory[slow_pathway_OutputIndex], slowfast_ArrayDevMemory[slow_pathway_OutputIndex], slowfast_ArraySize[slow_pathway_OutputIndex], cudaMemcpyDeviceToHost, m_CudaStream);
cudaMemcpyAsync(slowfast_ArrayHostMemory[fast_pathway_OutputIndex], slowfast_ArrayDevMemory[fast_pathway_OutputIndex], slowfast_ArraySize[fast_pathway_OutputIndex], cudaMemcpyDeviceToHost, m_CudaStream);
cudaStreamSynchronize(m_CudaStream);
data=(float*)slowfast_ArrayHostMemory[fast_pathway_OutputIndex];
ROIAlignForwardCpu((float*)slowfast_ArrayHostMemory[slow_pathway_OutputIndex], 0.0625, 32,16,29, 2048,7, 7, (float*)boxes_data, (float*)ROIAlign_ArrayHostMemory[0]);
ROIAlignForwardCpu((float*)slowfast_ArrayHostMemory[fast_pathway_OutputIndex], 0.0625, 32,16,29, 256,7, 7, (float*)boxes_data, (float*)ROIAlign_ArrayHostMemory[1]);
data=(float*)ROIAlign_ArrayHostMemory[0];
cudaMemcpyAsync(ROIAlign_ArrayDevMemory[0], ROIAlign_ArrayHostMemory[0], ROIAlign_ArraySize[0], cudaMemcpyHostToDevice, m_CudaStream);
cudaMemcpyAsync(ROIAlign_ArrayDevMemory[1], ROIAlign_ArrayHostMemory[1], ROIAlign_ArraySize[1], cudaMemcpyHostToDevice, m_CudaStream);
m_CudaheadContext->enqueueV2(ROIAlign_ArrayDevMemory, m_CudaStream, nullptr);
cudaMemcpyAsync(ROIAlign_ArrayHostMemory[2], ROIAlign_ArrayDevMemory[2], ROIAlign_ArraySize[2], cudaMemcpyDeviceToHost, m_CudaStream);
cudaStreamSynchronize(m_CudaStream);
参考链接
1. https://blog.csdn.net/y459541195/article/details/126278476
2. https://blog.csdn.net/WhiffeYF/article/details/115581800
3. https://github.com/facebookresearch/SlowFast
评论