
基于CenterFace的模型优化记录
【GiantPandaCV导语】CenterFace移动端模型优化实验记录
一、序
CenterFace是基于CenterNet的一种AnchorFree人脸检测模型。在widerface上性能虽然没有超过SOTA(Retinaface),但是胜于推理速度较快(不需要NMS),模型结构简单,便于移植部署。
二、背景
模型主要是使用在移动端App中,需要满足:
上传图片后返回带有人脸检测框的结果图片。 打开摄像头实时进行检测并拍照,返回检测后的图片。 需要在室内、室外、白天,晚上场景下均可使用,受众群体密集度比较高,需要支持戴口罩检测,Recall和precision均要求比较高(大于90%)。 需要支持大小人脸检测。样例如下,难点在于支持小人脸检测以及小模型优化。

图1-场景例子
三、CenterFace
本节先简单介绍一下CenterFace模型
模型结构
CenterFace模型构造比较简单,基础backbone+FPN+head即完成网络构建。1. backbone模型上采用了mobilenetv2作为backbone,mobilenetv3因为多分支以及SE模块,手机端移植不是很友好,实机测试,iphonex上mbv3相比mbv2要慢1ms左右,如果是低端机,这个差距会更大。2. FPN采用的是传统的top-down结构,没有使用PAN。3. Head采用4个conv+bn结构分别输出locationmap,scalemap,offsetmap和pointsmap。整体结构图如下:
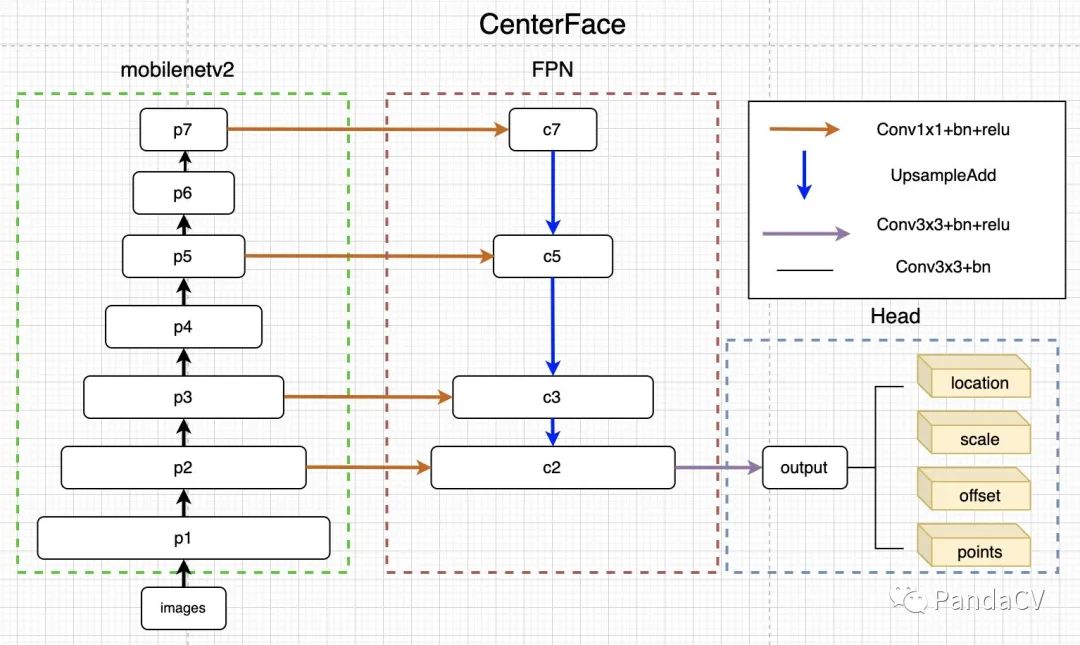
图2-模型结构
损失函数
CenterFace的损失函数和CenterNet一样,由FocalLoss形式Location分类损失和L1回归损失构成
Location分类损失:
L1回归损失:
offset points scale 最终损失:
对于location损失,只有每个bbox的中心点为正样本,其余点均为负样本,公式。对于offset损失,由于featuremap进行下采样的时候,计算中心点会由于取整产生偏移,需要用l1损失计算这个偏差。对于scale损失,这个是对bbox的w和h进行回归,取log便于计算。对于points损失,计算的是人脸5个关键点到中心点之间的距离的损失,做了normalize处理。最后的损失,就是各个损失的加权之和。
标签生成
locationmap, centerface中最重要的target就是bbox中心点gaussianmap生成,代码,效果图如下:
def _gaussian_radiusv1(self, height, width, min_overlap=0.7):
"""from cornernet"""
a1 = 1
b1 = (height + width)
c1 = width * height * (1 - min_overlap) / (1 + min_overlap)
sq1 = torch.sqrt(b1 ** 2 - 4 * a1 * c1)
r1 = (b1 + sq1) / 2
a2 = 4
b2 = 2 * (height + width)
c2 = (1 - min_overlap) * width * height
sq2 = torch.sqrt(b2 ** 2 - 4 * a2 * c2)
r2 = (b2 + sq2) / 2
a3 = 4 * min_overlap
b3 = -2 * min_overlap * (height + width)
c3 = (min_overlap - 1) * width * height
sq3 = torch.sqrt(b3 ** 2 - 4 * a3 * c3)
r3 = (b3 + sq3) / 2
return min(r1, r2, r3)
def _gaussian2D(self, shape, sigma=1):
m, n = [(ss - 1.) / 2. for ss in shape]
# y, x = np.ogrid[-m:m+1,-n:n+1]
y = torch.arange(-m, m+1, dtype=torch.int).view(-1, 1)
x = torch.arange(-n, n+1, dtype=torch.int).view(1, -1)
h = torch.exp(-(x * x + y * y) / (2 * sigma * sigma))
h[h < 1e-5 * h.max()] = 0
return h
def _draw_umich_gaussian(self, heatmap, center, radius, k=1):
diameter = 2 * radius + 1
# get the gaussian heatmap
gaussian = self._gaussian2D((diameter, diameter), sigma=diameter / 6)
x, y = int(center[0]), int(center[1])
height, width = heatmap.shape[0:2]
left, right = min(x, radius), min(width - x, radius + 1)
top, bottom = min(y, radius), min(height - y, radius + 1)
masked_heatmap = heatmap[y - top:y + bottom, x - left:x + right]
masked_gaussian = gaussian[radius - top:radius +
bottom, radius - left:radius + right]
if min(masked_gaussian.shape) > 0 and min(masked_heatmap.shape) > 0: # TODO debug
torch.max(masked_heatmap, masked_gaussian * k, out=masked_heatmap)
return heatmap
图3-heatmap
offsetmap, 每个bbox中心点上x方向和y方向的偏移结果,输出是一个(BX2XHXW)的map。
scalemap, 每个bbox中心点上w和h的log结果,输出是一个(BX2XHXW)的map。
pointsmap, 每个bbox的中心点到5个关键点x和y方向的距离,输出是一个(BX10XHXW)的map。
模型推理
CenterFace没有使用NMS作为后处理,而是采用的maxpooling作为代替,代码如下:
loc = loc.unsqueeze(0) # heatmap
hm_max = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)(loc)
loc[loc != hm_max] = 0
四、优化路线
数据:由于场景任务中存在部分带有口罩的情况,所以采集了2000张百度的带有口罩的数据,混合widerface的train和val的数据来进行训练,测试数据使用业务提供的数据,保持一致。
优化:流程图如下:
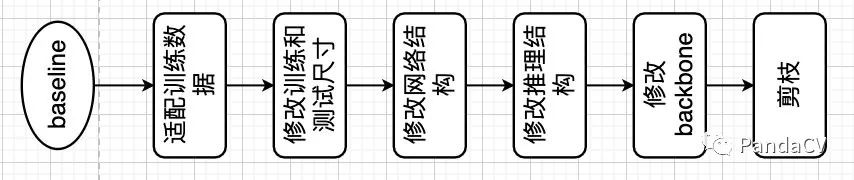
图4-模型优化流程
baseline模型为mobilenetv2+fpn模型,测试数据上ap为95%,初始图片训练大小为800x800,测试大小为416x416,FLOPs为1G。
通常来讲,train的size大于测试的时候,效果表现不好。所以调整图片的trainsize,分别为800,640,512,416,最终在416x416测试的情况下,训练size为416的时候效果最好。模型固定为416训练,416测试。
centerface的FPN的最后一层直接进行输出,这里把多层layer进行了concat,ap提升了一个点,但是FLOPs增加,收益不大。
由于centerface没有anchorbbox,bbox回归和中心点损失没有实质的关联,所以bbox的表现不是很好,添加了一个scale_dis分支,输出(BX4XHXW)的一个featuremap,分别表示的是中心点到上下左右的距离,计算IOU损失,效果提升不明显,还带来了4个通道的featuremap的冗余计算,直接弃用了(有兴趣的同学可以参考FCOS的说明)。
由于FPN最后的输出,经过一个卷积后,要输出多个head,会带来多个卷积计算,所以考虑优化为一个卷积输出,输出的层为(BX(1+2+2+10)xHXW),计算的时候分别对应channel计算损失,减少了10M的FLOPs,推理速度有所提升,同时提升了将近1个点的ap。
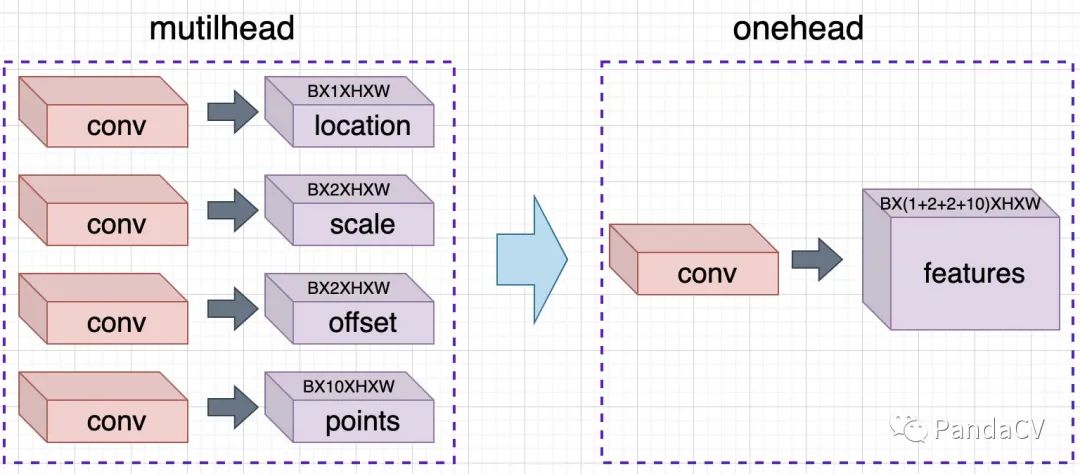
图5-修改head结构
由于业务只要求输出框,对于关键点没有需求,所以构建结构图的时候,把关键点的channel砍掉,可以减少20M的FLOPs,精度保持不变。
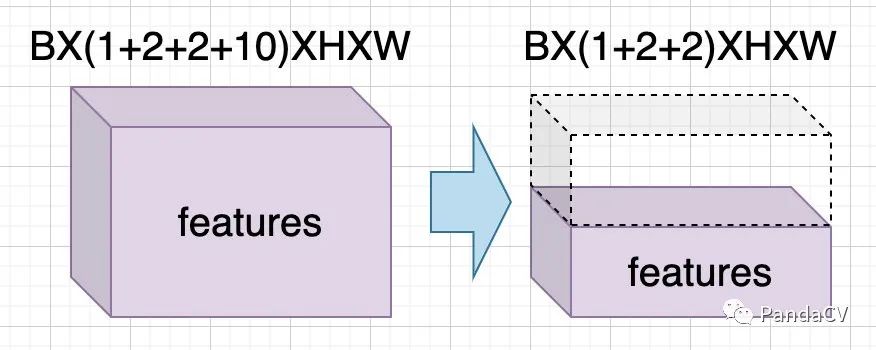
图6-推理减少channel
使用mobilenetv2x0.25+fpn作为backbone,使用上面的操作,FLOPs降低为0.2G,ap基本保持不变。
修改训练size为400,推理size也为400,修改FPN的channel从24降低到16,FLOPs降低到了0.131G,精度保持95.2%相比baseline有轻微的提升。
最后对模型进行剪枝,采用SlimmingBN方法,对mobilenetv2中的
InvertResdiual模块中的升维层进行剪枝。流程如下:训练的时候,对bn的gamma进行l1正则,设置为1e-4代码如下:
def updataBN(self):
"""add a l1 panety for bn channel"""
for m in self.model.modules():
if isinstance(m, nn.BatchNorm2d):
m.weight.grad.data.add_(self.s * torch.sign(m.weight.data))剪枝的时候,根据bn总数设置阈值,对weights从小到大进行排序,按比例定位阈值,根据阈值对bn的weights置0,重新计算测试集ap,测试发现卡0.3的时候,精度保持不变,0.4的时候精度下降1个点的ap,需要进行finetune。
保存模型,根据剪枝出来的Config重构模型结构,复制保留下来的权重到对应修改的层上,再次进行推理,ap保持不变即可,需要finetune的话,load权重后进行finetune,这里finetune个人建议是pretrain,finetune的话,可能会由于剪枝导致过检和漏检的情况在训练结束后还存在。
for [m0, m1] in zip(model.fpn.backbone.modules(), newmodel.fpn.backbone.modules()):
# only prune the invertedresidual conv and bn
if isinstance(m0, InvertedResidual):
if len(m0.conv) > 5:
for i in range(len(m0.conv)):
if i == 1:
if isinstance(m0.conv[i], nn.BatchNorm2d):
idx1 = np.squeeze(np.argwhere(np.asarray(mask.cpu().numpy())))
# first batchnormalize (hidden)
m1.conv[i].weight.data = m0.conv[i].weight.data[idx1].clone()
m1.conv[i].bias.data = m0.conv[i].bias.data[idx1].clone()
m1.conv[i].running_mean = m0.conv[i].running_mean[idx1].clone()
m1.conv[i].running_var = m0.conv[i].running_var[idx1].clone()
# first conv (hidden, inp, 1, 1)
if isinstance(m0.conv[i-1], nn.Conv2d):
w = m0.conv[i-1].weight.data[idx1, :, :, :].clone()
m1.conv[i-1].weight.data = w.clone()
# second conv (hidden, 1, 1, 1)
if isinstance(m0.conv[i+2], nn.Conv2d):
w = m0.conv[i+2].weight.data[idx1, :, :, :].clone()
m1.conv[i+2].weight.data = w.clone()
# second bn (hidden)
if isinstance(m0.conv[i+3], nn.BatchNorm2d):
m1.conv[i+3].weight.data = m0.conv[i+3].weight.data[idx1].clone()
m1.conv[i+3].bias.data = m0.conv[i+3].bias.data[idx1].clone()
m1.conv[i+3].running_mean = m0.conv[i+3].running_mean[idx1].clone()
m1.conv[i+3].running_var = m0.conv[i+3].running_var[idx1].clone()
# third conv (oup, hidden, 1, 1)
if isinstance(m0.conv[i+5], nn.Conv2d):
w = m0.conv[i+5].weight.data[:, idx1, :, :].clone()
m1.conv[i+5].weight.data = w.clone()
# third bn (oup)
if isinstance(m0.conv[i+6], nn.BatchNorm2d):
m1.conv[i+6].weight.data = m0.conv[i+6].weight.data.clone()
m1.conv[i+6].bias.data = m0.conv[i+6].bias.data.clone()
m1.conv[i+6].running_mean = m0.conv[i+6].running_mean.clone()
m1.conv[i+6].running_var = m0.conv[i+6].running_var.clone()
layer_id_in_cfg += 1
if layer_id_in_cfg < len(cfg_mask):
mask = cfg_mask[layer_id_in_cfg]最后输出的模型为0.116G的FLOPs,相比baseline降低了10倍FLOPs,参数量400k左右,测试集上ap95.2%相比baseline高了0.2%个点。iphonex上测试10ms左右,低端机可以满足10FPS以上的输出,精度,速度均满足要求。
五、简单的思考
为什么gaussian map是一个3X3的map,而不是全局的map或者说是一个点? 可能是因为cornernet是计算角点的,因为存在偏差所以需要一个小点的map来做约束,centernet直接继承了这个idea,论文中也是直接引用没有过多的思考。 从损失构建上来看,如果增大gaussianmap,对应的增加负样本,会影响中心点的约束。相当于中心点是points anchor,其他的都是非anchor。 从gaussianmap生成来看,对应的3x3可以cover出现offset过大的情况,可以约束范围,毕竟没有bboxanchor。 如果把bbox全部填满? bbox填满,那么就是每个点都是正样本,框中不存在负样本,这样中心点的价值就不存在了,论文的延伸也就是FCOS。 loss之间的联系? 由于anchorbase的方法是存在海量的positive和negative anchors,回归的好坏,一是会受到anchor的影响,二是会受到classification的影响,所以生成的bbox比较稳定。centernet的各个loss实际上是独立的,只是建立在中心点的基础上,所以导致框会不稳定,尤其是在实时中抖动比较大,OneNet就这个问题给出了解决方案。
预测结果
400x400 移动端上进行测试的结果如下

图7-移动端检测结果
结束语
本人才疏学浅,以上都是自己在做项目中的一些方法和实验,以及一些粗浅的思考,并不一定完全正确,只是个人的理解,欢迎大家指正,留言评论。
参考文献
CenterFace(https://arxiv.org/pdf/1911.03599.pdf) CenteNet(https://arxiv.org/abs/1904.07850) CornerNet(https://arxiv.org/abs/1808.01244) SlimmingBN(https://openaccess.thecvf.com/content_ICCV_2017/papers/Liu_Learning_Efficient_Convolutional_ICCV_2017_paper.pdf) FCOS(https://arxiv.org/abs/1904.01355) OneNet(https://arxiv.org/abs/2012.05780)
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:
为了方便读者获取资料以及我们公众号的作者发布一些Github工程的更新,我们成立了一个QQ群,二维码如下,感兴趣可以加入。