
紧跟大佬的步伐:关于我亲自动手复现了恺明新作MAE这件事
点击上方“视学算法”,选择加"星标"或“置顶”
重磅干货,第一时间送达
导读
前段时间恺明大神的MAE又火爆了CV圈,只停留在为大佬的工作惊叹可不行,实践才能出真知。本文先讲述了 MAE 的原理与方法,然后针对 paper 中的实验现象谈谈自己的理解,最后分享与解析自己的源码实现。
前言
只要你不是与世隔绝的深度炼丹者,应该都知道前阵子恺明大神的佳作 MAE(Masked Autoencoders Are Scalable Vision Learners),自双11那天挂到 arXiv 后,江湖上就开始大肆吹捧:'yyds'、'best paper 预定' 什么的满天飞.. 造成这一现象最主要原因还是大神本身的光环所致,另外就是大家看到 paper 中展示的 mask 掉图像中这么多部分(75%~95%)后模型仍能重建回不错的效果,难免无脑地拍手叫好(没有冒犯的意思,别打我,CW 当时也没忍住拍手叫好了..)。
但是,作为 coder,只动嘴不觉得很无聊么!?CW 可不要无聊的风格,既然 MAE 看起来这么牛逼,那就干脆动手码一码,实现下看它效果如何嘛。尽管没有代码还没有开源,但方法本身足够简单,paper 也大致描述了下实现的方法。
于是,CW 出于爱玩的心态并结合一贯以来不无聊的风格,在周末的一个下午,去了我最爱的 cafe(上了新豆子,好棒!),边码边喝咖啡,自己实现了 MAE,还挺有意思的。
本文会先讲述 MAE 的原理与方法,然后针对 paper 中的实验现象谈谈自己的理解,最后再分享与解析自己的源码实现。
概述
MAE 的做法可以用一句话概述:以一定比例随机 mask 掉图片中的一些图像块(patch)然后重建这些部分的像素值。
主要特点有两个:
非对称的编、解码器设计 使用较高(如 75%)的掩码率(mask 比例)
第1点所述的“非对称”主要体现在 输入形式 与 网络结构 上:编码器(Encoder)仅对可见(unmasked)的图像块进行编码,而解码器(Decoder)的输入则是所有的图像块;同时,Decoder 可以是比较轻量的(比如 Encoder 通常是多层堆叠的 Transformer,而 Decoder 仅需较少层甚至1层就 ok)。这也表明 Encoder 与 Decoder 之间是解耦的。
第2点是该工作的一个重要发现:不同于 NLP,在 CV 中可能要配合较高的 mask 比例才能作为 “有效” 的自监督代理任务。“有效”指的是任务本身足够困难,这样模型才能学到有效的潜在特征表示。
由于 Encoder 仅处理 unmasked 的 patch(占所有输入的少数),因此,尽管其本身网络结构比较重载,但依然能够高效训练,特别是对于大模型,能够加速3倍以上,同时配合较高的掩码率,还能够涨点。
我们知道,MAE 的方法属于 掩码自编码(Masked Autoencoding) 范畴,那么,为何要用这种玩法呢?
好奇心:Why Masked Autoencoding ?
得益于硬件发展与算力的支持,现在的模型越玩越大,大模型由于参数量众多,因此也很容易过拟合一般规模的数据集。于是,再这么玩下去就需要更大量的数据,而这么大量的标注数据人工成本是很高的,作者也不禁 diss 一波:很多人(你们说是谁呢?会不会是姓 G 的那位呢?)呐,还用他们私有的数据集关起门来偷偷玩,不肯和大家分享:
Aided by the rapid gains in hardware, models today can easily overfit one million images and begin to demand hundreds of millions of—often publicly inaccessible—labeled images.
所以说,这么玩下去成本太高了,玩不起呀,于是就想方设法地开辟出了新的玩法:**自监督预训练。**其中,较为常见的一种模式就是 masked autoencoding,这种这玩法在 NLP 尤为火热,大名鼎鼎的 BERT 在预训练中就是这么玩的:以一定比例 mask 掉输入文本中的一些部分,让模型去预测这批被 mask 掉的内容。这样,利用数据本身就可以作为监督(模型要预测的目标来源于数据本身,并非人工构造),无需复杂的人工标注。同时,使用大量的数据让拥有大规模参数量的模型能够学到通用的知识,从而拥有良好的泛化能力。
以上谈到的是预训练阶段,当模型实际要应用于不同的下游任务时,还要使用少量的标注数据进行微调(fine-tune),这样才能够真正应对目标任务。
按照以前的玩法,在面对不同的任务时,我们都需要重新设计模型结构,然后用特定任务的全量标注数据去进行训练。而现在不用了,只要设计了合理的预训练任务,让大规模模型在大量的上游数据中完成了预训练,它就能学到“通用知识”,犹如“通才”;之后,在面对不同的任务时,我们都可以利用这个 pre-trained 大模型,在少量的下游数据中进行二次学习,让其成为“专才”。由于大模型参数量众多,因此能够很快拟合,在面对不同任务时都能够高效学习(相对地,正是由于模型参数太多了,因此很容易过拟合到下游训练集,反而丧失了泛化能力,这也是 fine-tune 玩法的一大毛病)。
灵魂拷问:Why Masked Autoencoding In CV Lags Behind NLP ?
OK,我们知道了 mask 这种玩法在 NLP 很流行,那为什么在 CV 中却比较冷门呢?作者也向大家发起了灵魂拷问:
progress of autoencoding methods in vision lags behind NLP.
We ask: what makes masked autoencoding different between vision and language ?
好吧,看没人回答,作者只能自我深刻分析(这样才能把故事讲完),最终提炼出以下三点:
i). 架构(architecture)差异
CV 和 NLP 的网络架构不一致,前者在过去一直被 CNN 统治,它基于方正的局部窗口来操作,不方便集成像 mask token 以及 position embedding 这类带有指示性的可学习因子。不过,这个 gap 现在看来应该可以解决了,因为 ViT(Vision Transformer) 已经在 CV 界大肆虐杀,风头很猛..
ii). 信息密度(information density)不同
图像和语言的信息密度是不一样的。语言是人类创造的,本身就是高度语义和信息密集的,于是将句子中的少量词语抹去再让模型去预测这些被抹去的词本身就已经是比较困难的任务了;而对于图像则相反,它在空间上是高度冗余的,对于图片中的某个部分,模型很容易由其相邻的图像块推断出来(你想想看插值的道理),不需要大量的高级语义信息。
因此,在 CV 中,如果要使用 mask 这种玩法,就应该要 mask 掉图片中的较多的部分,这样才能使任务本身具有足够的挑战性,从而使模型学到良好的潜在特征表示。
iii). 解码的目标不一致
CV 和 NLP 在解码器的设计上应该有不一样的考虑:NLP 解码输出的是对应被 mask 掉的词语,本身包含了丰富的语义信息;而 CV 要重建的是被 mask 掉的图像块(像素值),是低语义的。
因此,NLP 的解码器可以很简单,比如 BERT,严格来说它并没有解码器,最后用 MLP 也可以搞定。因为来自编码器的特征也是高度语义的,与需要解码的目标之间的 gap 较小;而 CV 的解码器设计则需要“谨慎”考虑了,因为它要将来自编码器的高级语义特征解码至低级语义层级。
基于以上三点的自我分析(作者很入戏,估计还喝了口咖啡),灵感一来,MAE 就被 present 出来了:
Driven by this analysis, we present a simple, effective, and scalable form of a masked autoencoder(MAE) for visual representation learning.
哟!你瞧,simple, effective, and scalable,作者自己都很满意~
什么!?你说他自吹自擂你不服?好,恺明大神立马放一波效果图让你开开眼界:

以上每3列为一组,每组中的左列是 mask 掉原图80%部分的效果图,中列是模型重建的效果,右列是原图。
什么?还要用数字说话?好,自个儿看:
With a vanilla ViT-Huge model, we achieve 87.8% accuracy when finetuned on ImageNet-1K. This outperforms all previous results that use only ImageNet-1K data.
具体方法
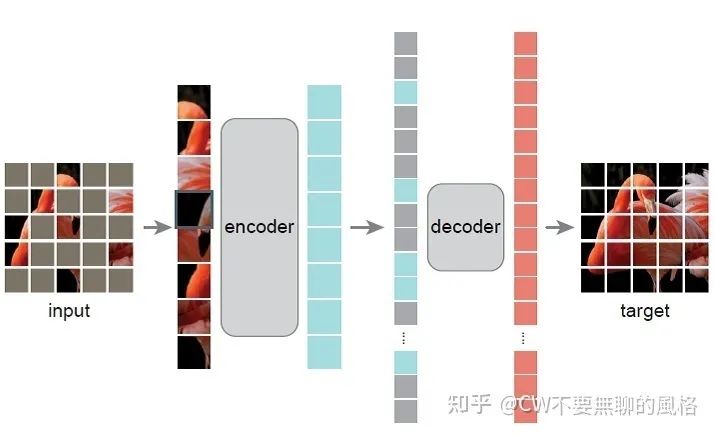
是时候来谈谈 MAE 的具体方法了。虽然前面铺垫了那么多,但是 CW 认为这是有必要的。教员也告诉我们,看问题要有广度、深度、精度:先纵观历史有全局认识,再结合当前情况深入分析,从而抓住问题的重点,最终才能追溯到本质。
结合前面的叙述,我们知道 MAE 方法的特点主要有:高掩码率的随机 mask 策略、非对称的编、解码器设计 以及 重建的目标是像素值。下面,就请各位朋友和 CW 一起来具体看看其中的每个部分。
Mask 策略
首先,沿袭 ViT 的做法,将图像分成一块块(ViT 中是 16x16 大小)不重叠的 patch,然后使用服从均匀分布(uniform distribution) 的采样策略对这些 patches 随机采样一部分,同时 mask 掉余下的另一部分。被 mask 掉的 patches 占所有 patches 的大部分(实验效果发现最好的比例是 75%),它们不会输入到 Encoder。
OK,策略很简单,那么这样做有什么好处呢?
首先,patch 在图像中是服从均匀分布来采样的,这样能够避免潜在的 “中心归纳偏好”(也就是避免 patch 的位置大多都分布在靠近图像中心的区域);其次,采用高掩码比例(mask 掉图中大部分 patches)能够防止模型轻易地根据邻近的可见 patches 推断(原文是 extrapolation,外推,这词有点高级..)出这些掩码块;最后,这种策略还造就了稀疏的编码器输入,因为 Encoder 只处理可见的 patches,于是能够以更低的代价训练较大规模的 Encoder,因为计算量和内存占用都减少了。
别看这 mask 策略好像挺简单的,但却是至关重要的一个部分,因为其决定了预训练代理任务是否具有足够的挑战性,从而影响着 Encoder 学到的潜在特征表示 以及 Decoder 重建效果的质量。
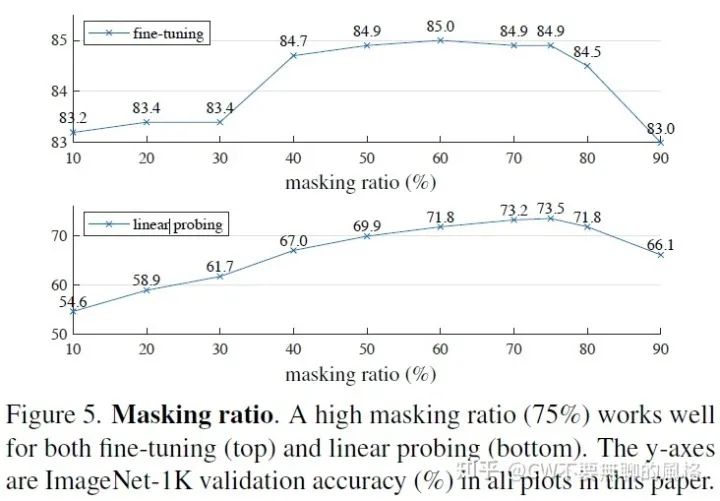
下图是作者在 paper 中展示的基于不同 mask 策略进行训练后模型的表现。我们肉眼可见,以上提到的随机(服从均匀分布)采样策略下模型的表现最好。注意,图中的 'block' 策略由于 mask 掉的是大块的 patch,因此 mask 比例设置了 50%,以达到和其它策略 mask 掉的部分占原图比例较为接近的效果。

还有呀,mask 比例也是很重要的,CW 在前文也提到过,在 CV 中,只有 mask 掉图中较多的部分才能形成具有挑战性的任务。作者实验发现,无论是 fine-tune 还是 linear-probe 下,75% 左右的 mask 比例都是比较好的一个选择。
Encoder
记住最重要的一点,Encoder 仅处理可见(unmasked)的 patches。Encoder 本身可以是 ViT 或 ResNet(其它 backbone 也 ok,就等你去实现了,大神给了你机会),至于如何将图像划分成 patch 嘛,使用 ViT 时的套路是这样的:
先将图像从 (B,C,H,W) reshape 成 (B,N,PxPxC),其中 N 和 P 分别为 patch 数量 和 patch 大小( ),也就是将3通道的图像转换成 N 个 维度大小为 PxPxC 的向量;然后,通过线性映射(linear projection,可以是全连接层)将其嵌入(embed)到指定的维度空间大小,记为 'dim'(从 PxPxC project 到 dim),转换成为 token(B,N,dim);最后再加上位置嵌入(position embedding),从而为各个 patch 添加位置信息。位置嵌入是所有图像共享的、可学习的,shape 与 每张图的 token 相对应,即:(N,dim)。
由于 unmasked 的 patches 所有 patches 的少数,因此可以训练很大的 Encoder,因为计算和空间要求都减少了。
Decoder
Decoder 嘛..就别想着偷懒了,它不仅需要处理经过 Encoder 编码的 unmasked 的 tokens,还需要处理mask tokens。但请注意,mask token 并非由之前 mask 掉的 patch 经过 embedding 转换而来,而是可学习的、所有 masked patch 都共享的1个向量,对,仅仅就是1个!
那么你会问:这样如何区分各个 maked patch 所对应的 token 呢?
别忘了,我们还有 position embedding 嘛!如同在 Encoder 中的套路一样,这里对于 mask token 也需要加入位置信息。position emebdding 是每个 masked patch 对应1个,shape 是 (N',dim),其中 N' 是 masked patch 的数量。但 mask token 只有1个怎么办是不是?简单粗暴——“复制”多份即可,使得每个 masked patch 都对应1个 mask token,这样就可以和 position embedding 进行相加了。
另外,Decoder 仅仅是在预训练任务为了重建图像而存在,而我们的下游任务形式多样,因此实际应用时很可能没 Decoder 什么事了(和它 say byebye 咯~)。所以,Decoder 的设计和 Encoder 是解耦的,Decoder 可以设计得简单、轻量一些(比 Encoder 更窄、更浅。窄:对应通道数;浅:对应深度),毕竟真正能学习到潜在特征表示的是 Encoder。
这样,尽管 Decoder 要处理的 token 数很多(全量token,而 Encoder 仅处理 unmasked 的部分),但其本身轻量,所以还是能够高效计算。再结合 Encoder 虽然本身结构重载(相对 Decoder 来说),但其处理的 token 较少,这样,整体架构就十分 efficient 了,漂亮~!
任务目标:重建像素值
MAE 预训练任务的目标是重建像素值,并且仅仅是 masked patch 的像素值,也就是仅对 mask 掉的部分计算 loss,而 loss 就是很大众的 MSE。为何仅计算 mask 部分的 loss?实验结果发现这样做模型的性能会更好,而如果对所有 patches 都计算 loss 的话会掉点:
Computing the loss only on masked patches differs from traditional denoising autoencoders that compute the loss on all pixels. This choice is purely result-driven:
computing the loss on all pixels leads to a slight decrease in accuracy (e.g., ~0.5%).
那么模型是如何去预测 masked patch 的像素值并计算 loss 的呢?具体来说,就是:
在 Decoder 解码后的所有 token 中取出 mask tokens(在最开始 mask 掉 patch 的时候可以先记录下这些 masked 部分的索引),将这些 mask tokens 送入全连接层,将输出通道映射到1个 patch 的像素数量(PxPxC),也就是输出的 shape 是:(B,N',PxPxC),其中的每个值就代表预测的像素值。最后,以之前 mask 掉的 patch 的像素值作为 target,与预测结果计算 MSE loss。
另外,作者提到使用归一化的像素值作为 target 效果更好,能够提升学到的表征的质量。这里的归一化做法是:计算每个 patch 像素值的均值与标准差,然后用均值与标准差去归一化对应的 patch 像素。
Pipeline
OK,解析完 MAE 的各部分结构,现在 CW 就将它们串起来:
将图像划分成 patches:(B,C,H,W)->(B,N,PxPxC); 对各个 patch 进行 embedding(实质是通过全连接层),生成 token,并加入位置信息(position embeddings):(B,N,PxPxC)->(B,N,dim); 根据预设的掩码比例(paper 中提倡的是 75%),使用服从均匀分布的随机采样策略采样一部分 token 送给 Encoder,另一部分“扔掉”(mask 掉); 将 Encoder 编码后的 token 与 加入位置信息后的 mask token 按照原先在 patch 形态时对应的次序拼在一起,然后喂给 Decoder 玩(如果 Encoder 编码后的 token 的维度与 Decoder 要求的输入维度不一致,则需要先经过 linear projection 将维度映射到符合 Decoder 的要求); Decoder 解码后取出 mask tokens 对应的部分送入到全连接层,对 masked patches 的像素值进行预测,最后将预测结果与 masked patches 进行比较,计算 MSE loss
实验理解
这部分给大家 show 下 paper 中的部分实验结果,并针对其中一些现象谈谈自己的理解。
Mask 比例
前文也多次谈到,mask 比例较高才能形成具有挑战性的预训练任务,模型才更有机会学到更好的潜在特征表示。由上图中的实验结果也可以看到,无论是在 fine-tune 还是 linear probe 的玩法中,mask 比例逐渐升高(但不过份)时,模型性能都会更好。
但是,fine-tune 和 linear probe 的结果还是有所区别的:linear probe 几乎是线性增涨的趋势,而 fine-tune 则是 mask 比例在 30%~40% 之间激增,而后就倾向于饱和了。
So,为啥会酱捏?
CW 觉得,linear probe 之所以没有那么快饱和,和其本身的玩法相关——仅调整模型最后的几层分类头(fix 住其它部分,如 Encoder)。因此,mask 比例越高,在预训练时得到的 Encoder 就越强,但这部分在下游任务中是不能够再被训练的了,所以其性能就随着 mask 比例的增加呈线性增涨的趋势。
相对地,fine-tune 时,还能够继续训练 Encoder 的参数去适配下游任务,因此在 mask 比例超过一定程度后,对于下游任务的性能提升就不那么明显了。
Mask 采样策略

作者通过实验比较,最终选择了服从均匀分布的随机采样(作者称其为 'random')策略,以上是详细的实验结果。
可以观察出,block-wise 策略由于掩盖掉的图像块区域太大了,因此在高于 50% 的 mask 比例下效果就不好(因为你本身就遮得广,现在还要遮得多,太难了吧..)。
而对于 grid 策略,作者说,这种方式在训练时能够对数据拟合得很好,但实际学到的特征表示泛化性其实是比较弱的。
由此可以说明,代理任务设计得太困难(对应 block-wise)或太简单(对应 grid)都不行,要适当(对应 random)才好,此乃中庸之道~
Decoder 的设计
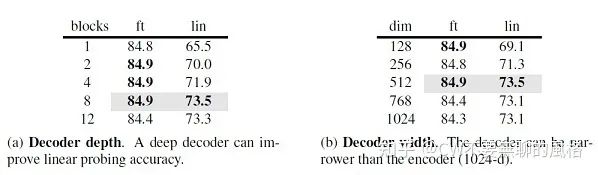
作者还探究了 Decoder 的设计。上图展示了不同的 Decoder 深度(Transformer 层数)和宽度(通道数)对于 fine-tune 和 linear probe 在 ImageNet-1K 下游任务中的表现。
可以发现,Decoder 的深度和宽度对于 linear probe 有较为明显的影响,但对于 fine-tune 的影响却不那么突出。
So,为啥会酱捏(again)?
想一想,Decoder 更深和更宽时,会发生什么?
(自问自答):当 Decoder 更深/宽时,它本身会拥有更强的重建能力,这样就使得在预训练时 Encoder 能更专注于提取抽象语义层级的特征,专心做事了,产生的质量也就更好了。也就是说,Encoder 在提取良好特征方面更专业了。
OK,了解了以上这点没错,但这种效应是同样作用于 linear probe 和 fine-tune 的,那么为何会造成不同的影响程度呢?
进一步探究,其实还是与它们各自的玩法相关:
linear probe 是完全继承预训练 Encoder 的玩法(因其仅调最后几层分类头),而 fine-tune 在下游任务中仍能够继续调整 Encoder 的参数。于是,预训练时得到的 Encoder 牛不牛逼,对 linear probe 产生的影响会更大一些。
以上的话太白了,有点 low,再装装逼:
究其本质,其实是预训练任务(图像重建)与下游任务(图像识别)之间存在着 gap!
fine-tune 时由于能够调整 Encoder 去适配图像识别任务,因此预训练对其影响程度就相对没那么大了。
Mask token 为何被 Encoder “抛弃”?

我们知道,在 MAE 中,Encoder 仅玩 unmasked 的 tokens。那么,如果它也玩 mask tokens 会怎样呢?
你们别说:肯定会掉点嘛,不然作者干嘛不玩?
给点面子..
是的,如上图中的实验结果显示,会掉点(汗~)。原因也很直白:因为在下游任务中并不存在这些 mask tokens,上、下游任务之间存在 gap(这点在当年 BERT 出道时已经暴露了出来)。如果 Encoder 也对 mask tokens 进行编码,会进一步将这种 gap 的影响“扩散”至下游任务中造成影响。
各种重建目标的比较
MAE 的重建目标是 mask patches 的像素值。同时,作者在 paper 中还提到,如果预测的是归一化(具体做法 CW 在上文中有描述)的像素值,那么效果会更好。另外,作者还和 BEiT 那种预测 token 的方式 以及 PCA 的方式(对 patch 空间实施 PCA 并预测最大的因子)进行了比较:
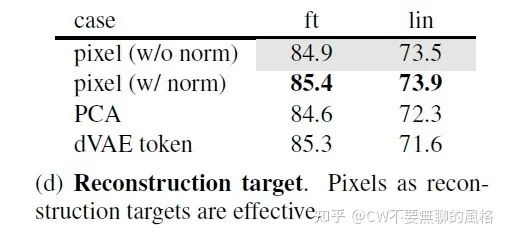
可以发现,预测归一化像素值的方式最强,BEiT 那种 token 的方式也差不多,那么,这种现象说明了什么呢?
回顾下前文 CW 提到的,这里归一化像素值的做法是分别针对每个 patch 使用它们独立统计出来的均值与方差去归一化的,这就会将各个 patch 归一化到不同的表示空间,从而分成不同的“簇”,于是各个 patch 之间的差异性就更强,形成了高频信息,相当于将各个 patch 构造成了边缘与纹理,从整体图像看来,对比度更高。从而使得模型更有针对性地学习各个 patch 的特征模式。同时,数值上由于做了归一化,因此又不会使得模型在这方面有所偏倚。
至于 token 的方式是照搬 NLP 的玩法,是高度离散化和语义化的,一个字的差异也可能导致词语之间的含义发生重大变化,本身就是高频东西。
因此,究其本质:高频信息才是王道!
数据增强
大家都知道,玩 CV 嘛肯定离不开数据增强,于是作者探究了这老套路对于 MAE 方法的影响:

由上图中的实验结果可知,这老套路果然还是有好处的。但是可以看到,不做随机缩放(fixed size)和随机缩放(rand size)的效果其实差不多,而采用色彩扰动(color jit)却反而比简单的 crop 还菜,有意思~
稍微想一下,这应该是 MAE 本身 masking 的做法已经是一种数据增强手段了,因此不需要“过份”的额外数据增强就能取得较好的效果(比如 color jit,本身就 mask 掉图像的一些部分了,还来扰乱原本的像素值,模型当然觉得不好搞啊..)。
干倒 linear probe
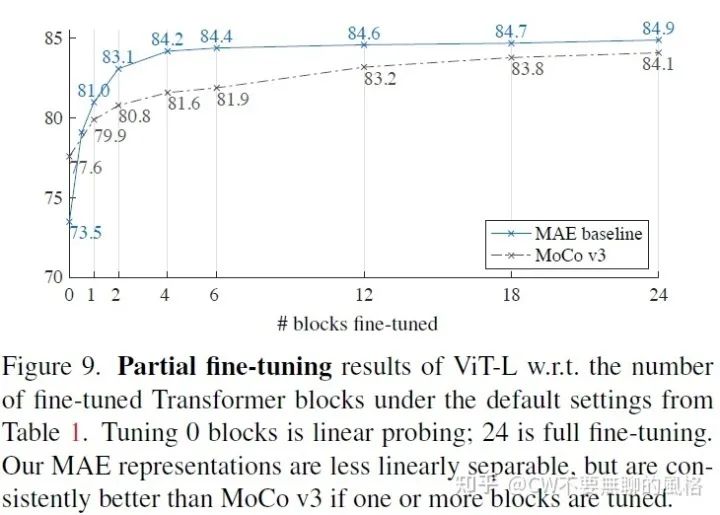
linear probe 一直是很流行的玩法,但通过上面的实验结果我们可以发现,它与 fine-tune 之间总是存在着“不协同”的结果,比如前面说到的 Decoder 的深度和宽度对 linear probe 的影响挺大但对于 fine-tune 来说却并不那么事关紧要。
于是,作者不禁怀疑起 linear probe 这种玩法的道理。“权衡”了 linear probe 和 fine-tune 之间的做法,作者设计出一种 'partial fine-tuning' 的玩法:仅调整 Encoder 的最后几层但 fix 住其它部分。如上图所示,调整 0 个 block 相当于是 linear probe,而调整所有24个 blocks 就是 fine-tuning 的玩法。
可以看到,对于 MAE,仅调整1个 block 就可以将 acc 从73.5%(linear probe)涨到81%,并且对于 MOCO v3 也一样可以涨点。
另外,MAE 在 partial fine-tuning 的方式下优于 MOCO v3,这也说明 MAE 学到的特征非线性更强,于是当可以调整非线性头部时效果就更好。
在这里,作者认为 linear probe 有必要去“面壁思过”一下,因为它这种玩法没有去捕捉一些强大但非线性的特征,而这却恰恰是深度学习所更应该重视和拥有的。
于是,这些现象都向我们表明:linear probe 并非是唯一的、正确地评估模型学到的表征质量的方式。并且,作者后续还进行了 detection 与 segmentation 相关的实验,从而在 linear probe 的玩法中学到的特征也并非是和迁移学习性能强相关的。
(其实就是想偷偷告诉你们:别被 linear probe 带偏了哦~)
开局:源码实现
终于到好玩的部分了,以上那些都是吹水,coder 还得动手写代码才好玩!
官方没有开源,但是 MAE 本身的方法足够简单,因此 CW 就自己脑洞了下,试着按照 paper 描述的(当然,还结合了自己的风格)去实现。
(ps: 以下代码基于Pytorch 框架,仅供娱乐使用)
先来看看 MAE 模型的初始化:
class MAE(nn.Module):
def __init__(
self, encoder, decoder_dim,
mask_ratio=0.75, decoder_depth=1,
num_decoder_heads=8, decoder_dim_per_head=64
):
super().__init__()
assert 0. < mask_ratio < 1., f'mask ratio must be kept between 0 and 1, got: {mask_ratio}'
# Encoder(这里 CW 用 ViT 实现)
self.encoder = encoder
self.patch_h, self.patch_w = encoder.patch_h, encoder.patch_w
# 由于原生的 ViT 有 cls_token,因此其 position embedding 的倒数第2个维度是:
# 实际划分的 patch 数量加上 1个 cls_token
num_patches_plus_cls_token, encoder_dim = encoder.pos_embed.shape[-2:]
# Input channels of encoder patch embedding: patch size**2 x 3
# 这个用作预测头部的输出通道,从而能够对 patch 中的所有像素值进行预测
num_pixels_per_patch = encoder.patch_embed.weight.size(1)
# Encoder-Decoder:Encoder 输出的维度可能和 Decoder 要求的输入维度不一致,因此需要转换
self.enc_to_dec = nn.Linear(encoder_dim, decoder_dim) if encoder_dim != decoder_dim else nn.Identity()
# Mask token
# 社会提倡这个比例最好是 75%
self.mask_ratio = mask_ratio
# mask token 的实质:1个可学习的共享向量
self.mask_embed = nn.Parameter(torch.randn(decoder_dim))
# Decoder:实质就是多层堆叠的 Transformer
self.decoder = Transformer(
decoder_dim,
decoder_dim * 4,
depth=decoder_depth,
num_heads=num_decoder_heads,
dim_per_head=decoder_dim_per_head,
)
# 在 Decoder 中用作对 mask tokens 的 position embedding
# Filter out cls_token 注意第1个维度去掉 cls_token
self.decoder_pos_embed = nn.Embedding(num_patches_plus_cls_token - 1, decoder_dim)
# Prediction head 输出的维度数等于1个 patch 的像素值数量
self.head = nn.Linear(decoder_dim, num_pixels_per_patch)
接下来,CW 会分各部分进行解析,下面一起来看看咯(看完你们自己动手写写,会更好玩)~
ps: 以上 Encoder 部分的 ViT 和 Decoder 部分的 Transformer 的实现没有什么特别的,和开源的主流实现一致,比较无聊,因此 CW 在下文中不会对这部分进行解析(其实想偷个懒,哈哈哈~!)。
Patch Partition
如前文所述,我们首先需要将图像划分成 patch,划分方式实质就是维度的变换:
num_patches = (h // self.patch_h) * (w // self.patch_w)
# (b, c=3, h, w)->(b, n_patches, patch_size**2 * c)
patches = x.view(
b, c,
h // self.patch_h, self.patch_h,
w // self.patch_w, self.patch_w
).permute(0, 2, 4, 3, 5, 1).reshape(b, num_patches, -1)
Masking
接下来,就是根据预设的 mask 比例采用服从均匀分布的策略随机采样一批 patches 喂给 Encoder,剩下的就 mask 掉:
# 根据 mask 比例计算需要 mask 掉的 patch 数量
# num_patches = (h // self.patch_h) * (w // self.patch_w)
num_masked = int(self.mask_ratio * num_patches)
# Shuffle:生成对应 patch 的随机索引
# torch.rand() 服从均匀分布(normal distribution)
# torch.rand() 只是生成随机数,argsort() 是为了获得成索引
# (b, n_patches)
shuffle_indices = torch.rand(b, num_patches, device=device).argsort()
# mask 和 unmasked patches 对应的索引
mask_ind, unmask_ind = shuffle_indices[:, :num_masked], shuffle_indices[:, num_masked:]
# 对应 batch 维度的索引:(b,1)
batch_ind = torch.arange(b, device=device).unsqueeze(-1)
# 利用先前生成的索引对 patches 进行采样,分为 mask 和 unmasked 两组
mask_patches, unmask_patches = patches[batch_ind, mask_ind], patches[batch_ind, unmask_ind]
Encode
OK,这时候我们就可以在 Encoder 中对 unmasked 的 patches 进行编码了。
当然,我们得先对 unmasked patches 进行 emebdding 转换成 tokens,并且加上 position embeddings,从而为它们添加位置信息,然后才能是真正的编码过程。至于编码过程,实质上就是扔给 Transformer 玩(query 和 key 玩一玩,玩出个 attention 后再和 value 一起玩~):
# 将 patches 通过 emebdding 转换成 tokens
unmask_tokens = self.encoder.patch_embed(unmask_patches)
# 为 tokens 加入 position embeddings
# 注意这里索引加1是因为索引0对应 ViT 的 cls_token
unmask_tokens += self.encoder.pos_embed.repeat(b, 1, 1)[batch_ind, unmask_ind + 1]
# 真正的编码过程
encoded_tokens = self.encoder.transformer(unmask_tokens)
Decode
Encoder 玩完后输出编码后的 tokens,首先将编码后的 tokens 和 添加了位置信息后的 mask tokens 按原先对应 patches 的次序拼起来,然后喂给 Decoder 解码。需要注意的是,编码后的 tokens 维度若与 Decoder 要求的输入维度不一致,需要使用 linear projection 进行转换。
# 对编码后的 tokens 维度进行转换,从而符合 Decoder 要求的输入维度
enc_to_dec_tokens = self.enc_to_dec(encoded_tokens)
# 由于 mask token 实质上只有1个,因此要对其进行扩展,从而和 masked patches 一一对应
# (decoder_dim)->(b, n_masked, decoder_dim)
mask_tokens = self.mask_embed[None, None, :].repeat(b, num_masked, 1)
# 为 mask tokens 加入位置信息
mask_tokens += self.decoder_pos_embed(mask_ind)
# 将 mask tokens 与 编码后的 tokens 拼接起来
# (b, n_patches, decoder_dim)
concat_tokens = torch.cat([mask_tokens, enc_to_dec_tokens], dim=1)
# Un-shuffle:恢复原先 patches 的次序
dec_input_tokens = torch.empty_like(concat_tokens, device=device)
dec_input_tokens[batch_ind, shuffle_indices] = concat_tokens
# 将全量 tokens 喂给 Decoder 解码
decoded_tokens = self.decoder(dec_input_tokens)
Loss Computation
取出解码后的 mask tokens 送入头部进行像素值预测,然后将预测结果和 masked patches 比较,计算 MSE loss:
# 取出解码后的 mask tokens
dec_mask_tokens = decoded_tokens[batch_ind, mask_ind, :]
# 预测 masked patches 的像素值
# (b, n_masked, n_pixels_per_patch=patch_size**2 x c)
pred_mask_pixel_values = self.head(dec_mask_tokens)
# loss 计算
loss = F.mse_loss(pred_mask_pixel_values, mask_patches)
Reconstruction(Inference)
为了方便观测重建效果,CW 将以上部分串起来在模型中集成了一个推理的方法:
@torch.no_grad
def predict(self, x):
self.eval()
device = x.device
b, c, h, w = x.shape
'''i. Patch partition'''
num_patches = (h // self.patch_h) * (w // self.patch_w)
# (b, c=3, h, w)->(b, n_patches, patch_size**2*c)
patches = x.view(
b, c,
h // self.patch_h, self.patch_h,
w // self.patch_w, self.patch_w
).permute(0, 2, 4, 3, 5, 1).reshape(b, num_patches, -1)
'''ii. Divide into masked & un-masked groups'''
num_masked = int(self.mask_ratio * num_patches)
# Shuffle
# (b, n_patches)
shuffle_indices = torch.rand(b, num_patches, device=device).argsort()
mask_ind, unmask_ind = shuffle_indices[:, :num_masked], shuffle_indices[:, num_masked:]
# (b, 1)
batch_ind = torch.arange(b, device=device).unsqueeze(-1)
mask_patches, unmask_patches = patches[batch_ind, mask_ind], patches[batch_ind, unmask_ind]
'''iii. Encode'''
unmask_tokens = self.encoder.patch_embed(unmask_patches)
# Add position embeddings
unmask_tokens += self.encoder.pos_embed.repeat(b, 1, 1)[batch_ind, unmask_ind + 1]
encoded_tokens = self.encoder.transformer(unmask_tokens)
'''iv. Decode'''
enc_to_dec_tokens = self.enc_to_dec(encoded_tokens)
# (decoder_dim)->(b, n_masked, decoder_dim)
mask_tokens = self.mask_embed[None, None, :].repeat(b, num_masked, 1)
# Add position embeddings
mask_tokens += self.decoder_pos_embed(mask_ind)
# (b, n_patches, decoder_dim)
concat_tokens = torch.cat([mask_tokens, enc_to_dec_tokens], dim=1)
# dec_input_tokens = concat_tokens
dec_input_tokens = torch.empty_like(concat_tokens, device=device)
# Un-shuffle
dec_input_tokens[batch_ind, shuffle_indices] = concat_tokens
decoded_tokens = self.decoder(dec_input_tokens)
'''v. Mask pixel Prediction'''
dec_mask_tokens = decoded_tokens[batch_ind, mask_ind, :]
# (b, n_masked, n_pixels_per_patch=patch_size**2 x c)
pred_mask_pixel_values = self.head(dec_mask_tokens)
# 比较下预测值和真实值
mse_per_patch = (pred_mask_pixel_values - mask_patches).abs().mean(dim=-1)
mse_all_patches = mse_per_patch.mean()
print(f'mse per (masked)patch: {mse_per_patch} mse all (masked)patches: {mse_all_patches} total {num_masked} masked patches')
print(f'all close: {torch.allclose(pred_mask_pixel_values, mask_patches, rtol=1e-1, atol=1e-1)}')
'''vi. Reconstruction'''
recons_patches = patches.detach()
# Un-shuffle (b, n_patches, patch_size**2 * c)
recons_patches[batch_ind, mask_ind] = pred_mask_pixel_values
# 模型重建的效果图
# Reshape back to image
# (b, n_patches, patch_size**2 * c)->(b, c, h, w)
recons_img = recons_patches.view(
b, h // self.patch_h, w // self.patch_w,
self.patch_h, self.patch_w, c
).permute(0, 5, 1, 3, 2, 4).reshape(b, c, h, w)
mask_patches = torch.randn_like(mask_patches, device=mask_patches.device)
# mask 效果图
patches[batch_ind, mask_ind] = mask_patches
patches_to_img = patches.view(
b, h // self.patch_h, w // self.patch_w,
self.patch_h, self.patch_w, c
).permute(0, 5, 1, 3, 2, 4).reshape(b, c, h, w)
return recons_img, patches_to_img
出于娱乐的目的,CW 没有考虑太多,快速写下一个很 low 的推理 pipeline:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 读入图像并缩放到适合模型输入的尺寸
from PIL import Image
img_raw = Image.open(os.path.join(BASE_DIR, 'mountain.jpg'))
h, w = img_raw.height, img_raw.width
ratio = h / w
print(f"image hxw: {h} x {w} mode: {img_raw.mode}")
img_size, patch_size = (224, 224), (16, 16)
img = img_raw.resize(img_size)
rh, rw = img.height, img.width
print(f'resized image hxw: {rh} x {rw} mode: {img.mode}')
img.save(os.path.join(BASE_DIR, 'resized_mountain.jpg'))
# 将图像转换成张量
from torchvision.transforms import ToTensor, ToPILImage
img_ts = ToTensor()(img).unsqueeze(0).to(device)
print(f"input tensor shape: {img_ts.shape} dtype: {img_ts.dtype} device: {img_ts.device}")
# 实例化模型并加载训练好的权重
encoder = ViT(img_size, patch_size, dim=512, mlp_dim=1024, dim_per_head=64)
decoder_dim = 512
mae = MAE(encoder, decoder_dim, decoder_depth=6)
weight = torch.load(os.path.join(BASE_DIR, 'mae.pth'), map_location='cpu')
mae.to(device)
# 推理
# 模型重建的效果图,mask 效果图
recons_img_ts, masked_img_ts = mae.predict(img_ts)
recons_img_ts, masked_img_ts = recons_img_ts.cpu().squeeze(0), masked_img_ts.cpu().squeeze(0)
# 将结果保存下来以便和原图比较
recons_img = ToPILImage()(recons_img_ts)
recons_img.save(os.path.join(BASE_DIR, 'recons_mountain.jpg'))
masked_img = ToPILImage()(masked_img_ts)
masked_img.save(os.path.join(BASE_DIR, 'masked_mountain.jpg'))
人在 cafe 时间有限,CW 试着用1张图片训练少轮迭代,该图是我十月份到可可西里无人区拍摄的风景,然后直接用训好的模型在这张原图上进行推理,以下是实验结果:
 原图
原图 mask(ratio=75%) 图
mask(ratio=75%) 图 模型重建效果
模型重建效果由于是在训练集上推理、肉眼也看不出来模型重建的效果图与原图的差别,因此并没有太大的意义,但起码保证了代码可以跑通,模型可以成功拟合数据,作为在 cafe 喝咖啡的附加娱乐项目还是能够过把瘾的。
End
图像和语言是不同性质的信号,图像不像语言一样天然是由一个个可分解的字词组成,它是连续的信号。因此,为了更遵循图像的“本性”,MAE 掩码的时候是对整体图像区域随机掩码,而非有意地对图像做语义性的分割(比如有意地去 mask 掉一些物体或特定区域)。同样地,MAE 重建的目标是像素值,而非语义实体(什么图像化 token 等)。
果然研究/解决一类问题还是要贴近其本质才能更好地 work,并且能够持久 work 的方法也通常是简洁而非花里胡哨的,因为本质就是最纯真的东西,所以说,大道至简。
代码写完,咖啡也喝得差不多了,天色已近黄昏,是时候找个地吃顿好的了,周末愉快,我的朋友们~!
如果觉得有用,就请分享到朋友圈吧!

点个在看 paper不断!