
Attention跟一维卷积有什么区别?
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文转自:视学算法
Attention跟一维卷积的区别是啥?
权重形成机制不同?
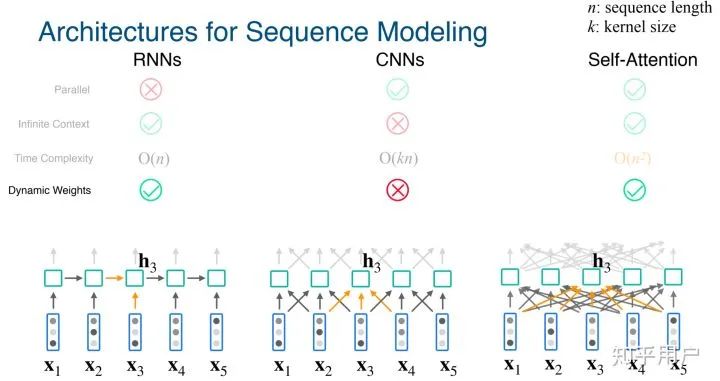
如果只是从运算的算子看,也就是矩阵乘法的角度看,区别不是很大。所以,可以继承同一个实现。
attention输入的key vector 和query matrix,得到的是attention score logits。一维卷积也是类似的。卷积操作在自然语言处理中也不算少见,比如TextCNN,还有ELMO中的char CNN,你看过代码的话,其实也就是卷积核乘以输入,然后卷积核高度为1,宽度为对应的嵌入长度。
如果说区别,那么第一就是输入的特征的意义是什么?第二就是输出的特征的意义是什么,以及应该如何处理这种特征。
比如key dot product query得到的是相似度,attention list要归一化,甚至在transformer中要先对attention score的方差归一化,然后再做softmax归一化。一维卷积得到的是信息提取,所以对于卷积得到的feature map,为了更有效的提取信息,需要池化。
当然,这里只是说了最简单的点积attention。你看过Luong论文的话会了解到更加丰富的attention实现。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
评论