
拜托,别问我什么各种Tree了,干就完事!
此动画内容为本文目录,时常一分钟,觉得太花时间可以跳过。本来一个思维导图可以搞定。但这一次尝试下这种方式,先放松放松。
一、 二叉树
二叉树是每个节点最多有两个子树的树结构。它有五种基本形态:二叉树可以是空集;根可以有空的左子树或右子树;或者左、右子树皆为空。如下图所示
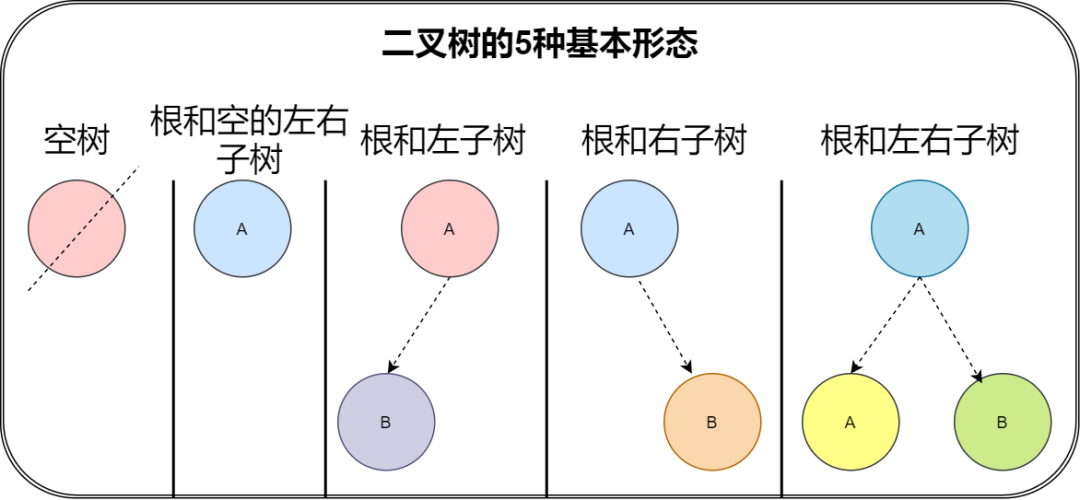
1 二叉树的五种性质
掌握二叉树的五种性质,能让我们在笔试中做题变得游刃有余,也就有更多的时间处理其他的题目。其具体的性质看下图。

2 两个特别的二叉树
完全二叉树:对于深度为K的,有n个结点的二叉树,当且仅当其每一个结点都与深度为K的满二叉树中编号从1至n的结点一一对应时称之为完全二叉树。
满二叉树:除了叶结点外每一个结点都有左右子叶且叶子结点都处在最底层的二叉树
完全二叉树和满二叉树长啥样呢?

3 常见的存储方法
我们知道数组最大的一个特点就是内存连续,方便随机访问,下标通常从0开始。好了,知道这些我们就先看看用数组如何存储一棵二叉树。

我们了解了二叉树的一点基本概念后,为了表示节点之间的关系,引入链表结构,用左右两个指针分别指向左节点和右节点,这样就可以串联整个二叉树,如下图所示。

3 二叉树的遍历
先序遍历:访问根节点,访问当前节点的左子树;若当前节点无左子树,则访问当前节点的右子树;

中序遍历访问当前节点的左子树;访问根节点;访问当前节点的右子树;

后序遍历:从根节点出发,依次遍历各节点的左右子树,直到当前节点左右子树遍历完成后,才访问该节点元素。

层次遍历:从上往下一层一层遍历

说实话,写的花里胡哨,但是您看到这里不容易了,可以听听音乐,谢谢您的查看!
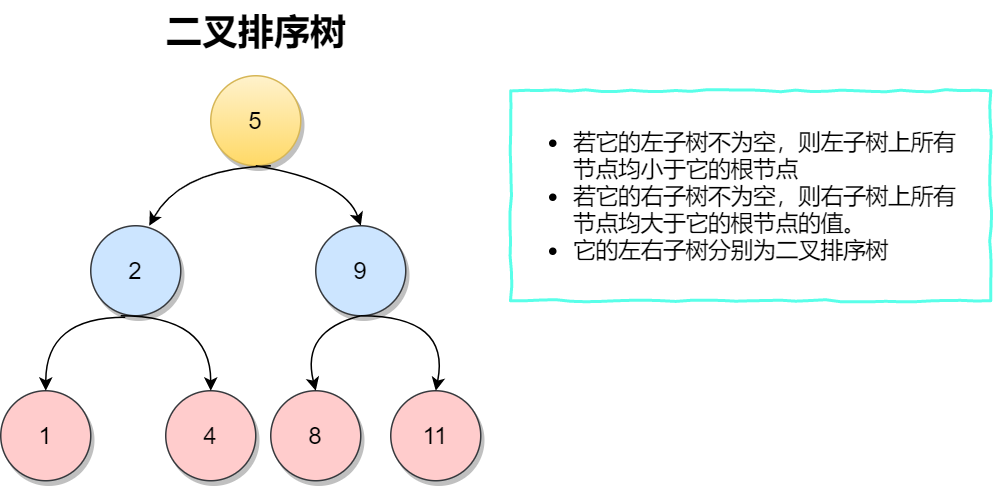
二、 二叉排序树
二叉排序树(Binary Sort Tree)又称二叉查找树、二叉搜索树。它或者是一棵空树;或者是具有下列性质的二叉树:
(1)若左子树不空,则左子树上所有结点的值均小于它的根结点的值;
(2)若右子树不空,则右子树上所有结点的值均大于它的根结点的值;
(3)左、右子树也分别为二叉排序树;
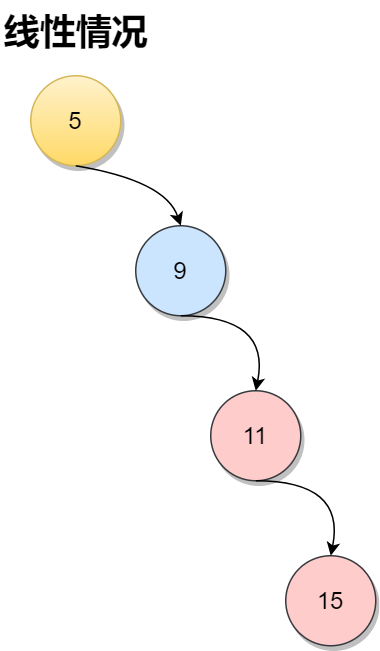
其高度与树中结点个数n成对数关系,检索的时间开销为O(logn)。但是很有可能检索的时间将变成线性的情况。
三、 哈夫曼树
哈夫曼树也叫做最优二叉树,一种带权路径长度最短的二叉树。那么什么是树的带权路径长度,它是树中所有的叶子节点的权值乘上其根节点的路径长度。
1 如何构造哈夫曼树

四、 平衡二叉树
之前我们知道了二叉排序树出现了线性的情况,所以需要想办法避免那种情况发生。这样两位爷爷发明了平衡二叉排序树,又叫AVL树。那么是怎么定义的呢?平衡二叉排序树是一类特殊的二叉排序树,它或者为空树,或者其左右子树都是平衡二叉排序树,而且其左右的子数高度之差绝对值不超过1.为了保证相对平衡,每次插入元素都会做相应的旋转,那么下面来看看这几种情况。
1 平衡二叉树与非平衡二叉树

2 平衡调整
LL型调整
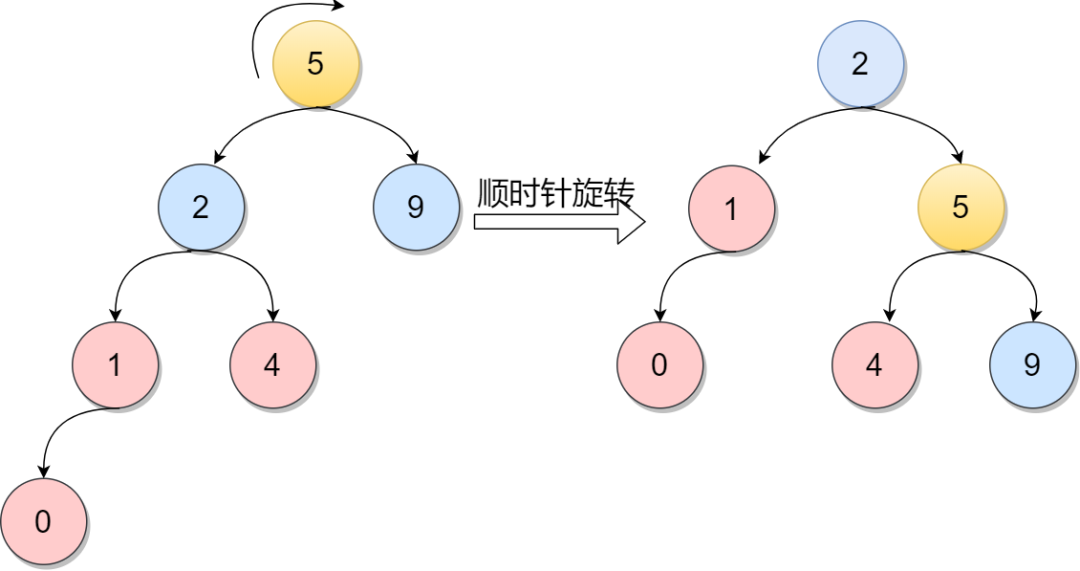
如下图,因为在A的左孩子的左孩子插入新的节点,导致A的平衡因子从1变为2,不在满足根本性质[-1,1],所以需要通过旋转。显然,按照大小关系,结点B应作为新的根结点,其余两个节点分别作为左右孩子节点才能平衡,这样看来,仿佛A结点绕结点B顺时针旋转一样。
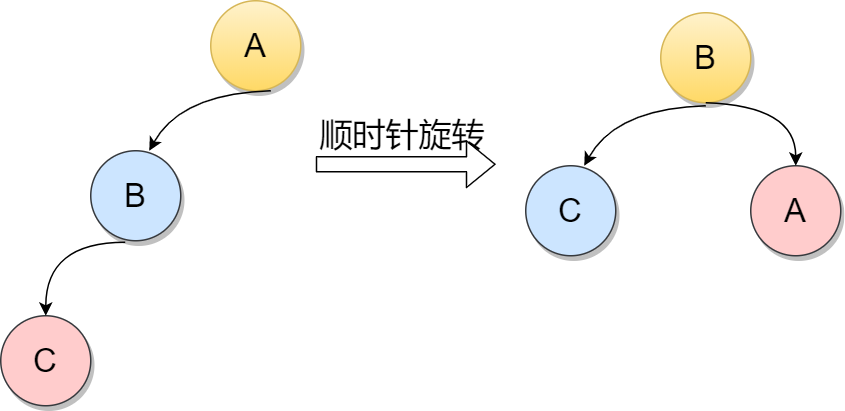
下图中,当在节点5的左子树中插入节点的时候而导致不平衡。这种情况调整如下:首先将元素5的左孩子2提升为新的根结点;然后将原来的根结点元素5变为元素2的右孩子;其他各子树按大小关系连接。
RR型调整
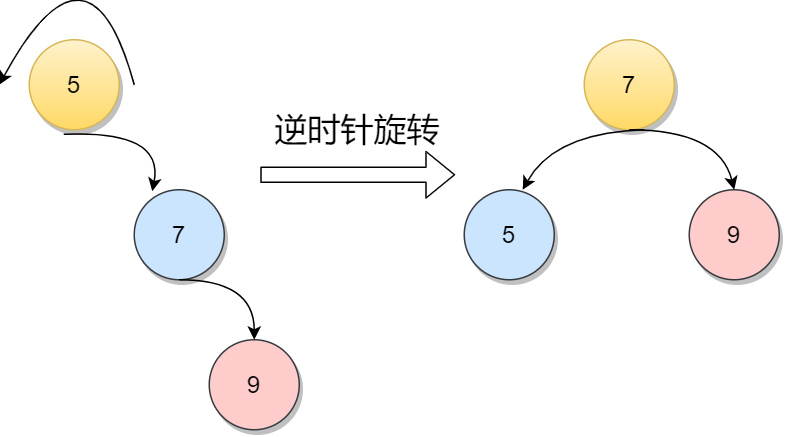
如下图,因为在元素5的右孩子的右孩子插入新的节点,导致元素5的平衡因子从-1变为-2,不在满足根本性质[-1,1],所以需要通过旋转。显然,按照大小关系,结点元素7应作为新的根结点,其余两个节点分别作为左右孩子节点才能平衡,这样看来,仿佛节点元素5绕结点元素7逆时针旋转一样。
RR型调整的一般形式如下图所示,表示节点元素4的右子树5(不一定为空)中插入结点(图中阴影部分所示)而导致不平衡( h 表示子树的深度)。这种情况调整如下:
LR调整
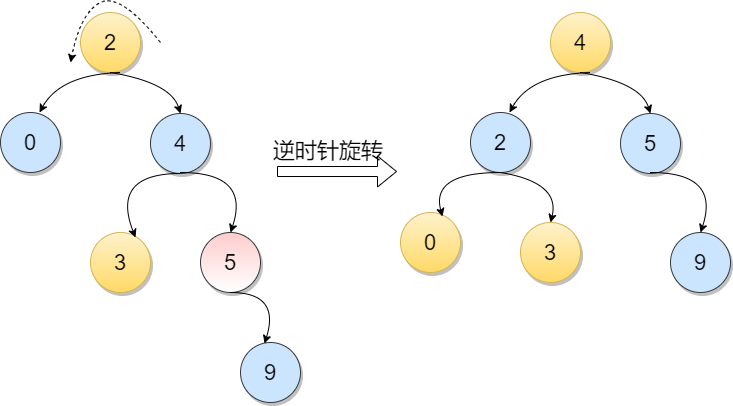
由于节点元素5的左孩子的右子树上插入新节点,导致不平衡。此时元素5的平衡因子由1变为2。第一张图是LR型的最简单形式。显然,按照大小关系,元素3应作为新的根结点,其余两个节点分别作为左右孩子节点才能平衡。
由于节点元素6增加一个左孩子,导致元素4变得不平衡。先顺时针旋转元素7再逆时针旋转4元素达到平衡。
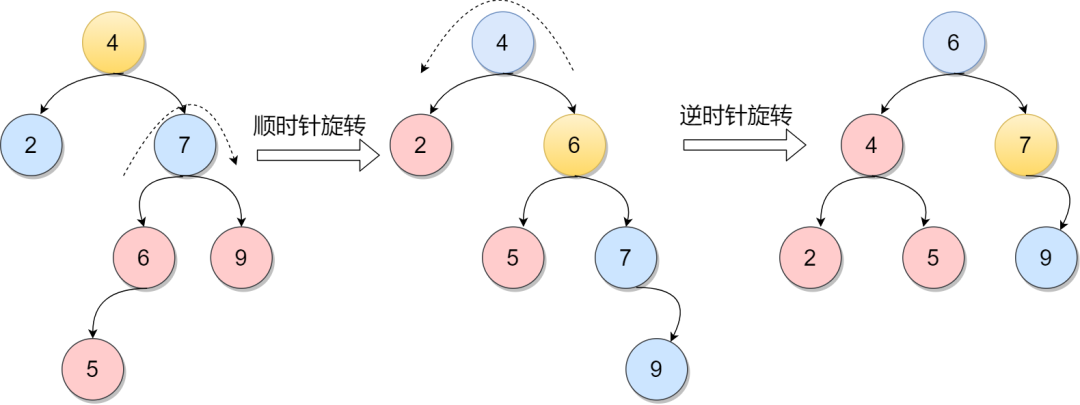
RL调整
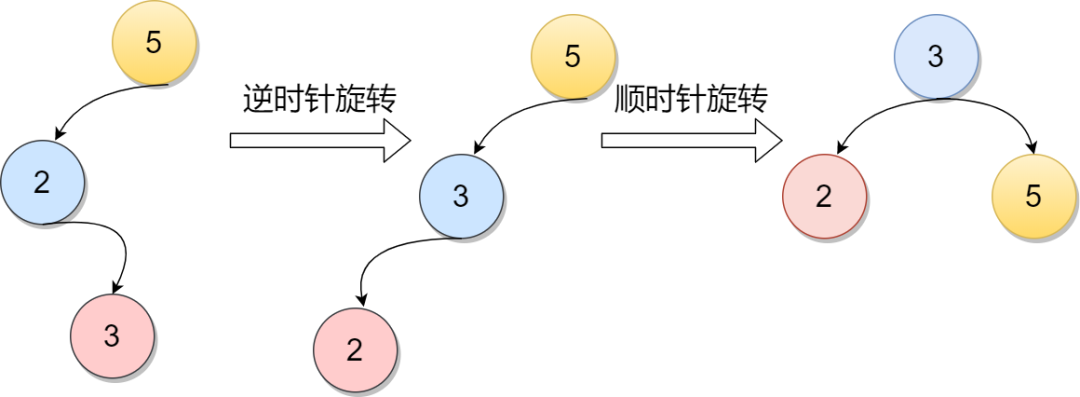
当在元素5的右孩子的左子树增加一个节点7的时候,会造成不平衡的情况。先逆时针旋转成RR情况,再将元素5顺时针旋转。
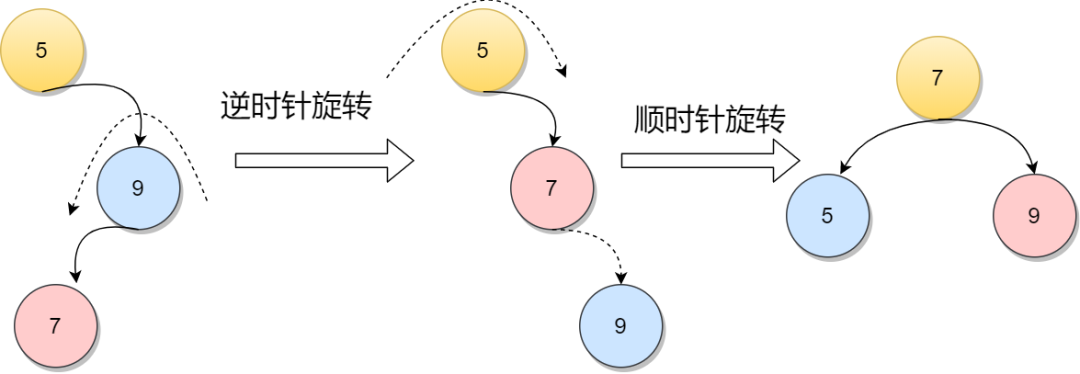
第二种情况方法类似,看起来会复杂一点。当在元素7得左孩子6增加左孩子元素5得时候,导致元素4变得不平衡。那么先顺时针调整元素7,再逆时针调整元素4
五、 B树和B+树
小伙伴们有没有想过,为什么很多数据库中的索引采用B+树呢?以及为什么索引是放在磁盘上。
1 B树
如果使用二叉树作为索引的底层实现结构,树会变得很高,从而增加了磁盘的IO次数,从而影响数据查询时间。因此为了降低其高度,让一个节点有多个子节点,B树就诞生了。
B树的容颜
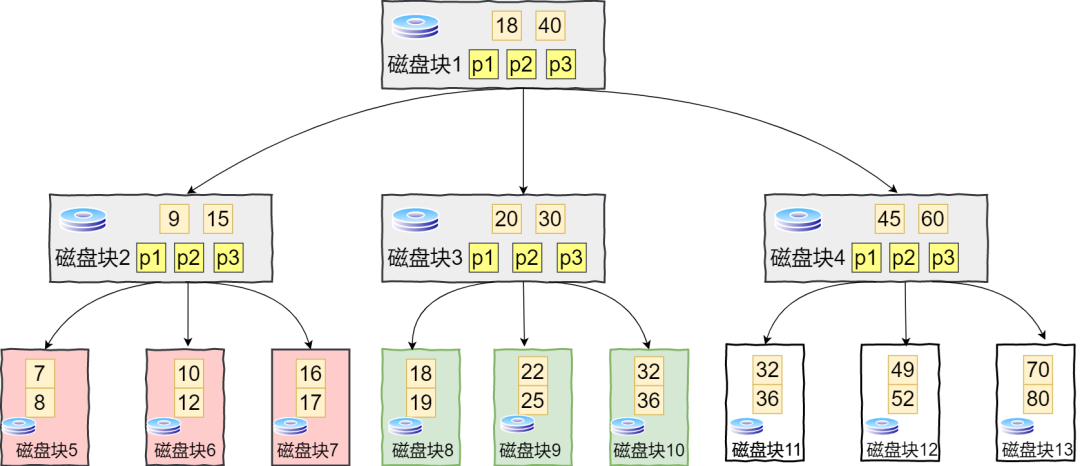
一个M阶B树的哪些特性
官方英文
1、Every node has at most m children.
2、Every non-leaf node (except root) has at least [m/2] child nodes.
3、The root has at least two children if it is not a leaf node.
4、A non-leaf node with k children contains k − 1 keys.
5、All leaves appear in the same level.
中文
根节点的儿子数量范围[2,M]
每个中间节点包含 k-1 个关键字和 k 个孩子,孩子的数量 = 关键字的数量 +1,k 的取值范围为 [ceil(M/2), M]。
叶子节点包括 k-1 个关键字(叶子节点没有孩子),k 的取值范围为 [ceil(M/2), M]。
假设中间节点节点的关键字为:Key[1], Key[2], …, Key[k-1],且关键字按照升序排序,即 Key[i]
所有叶子节点位于同一层。
举个例子
上图为三阶图,查看磁盘3,关键字为20,30.三个孩子分别是(18,19),(22,25),(32,36).其中(18,19)小于20,(22,25)在(20,30)之间,(32,36)大于30.
那么在查找搜索的过程中,是怎样的访问过程呢?假设查找元素7
与根节点比较,得到指针p1
根据p1来到磁盘2,关键字为(9,15),发现小于9,得到指针p1
根据p1来到磁盘5,关键字为(7,8),发现正好有7.
2 B+树
前文介绍了二分查找方法为O(log2n),但是会出现深度非常大退化为链表,其查找数据的时间复杂度变为O(n)。从而就出现了平衡二叉树。
B+树容颜
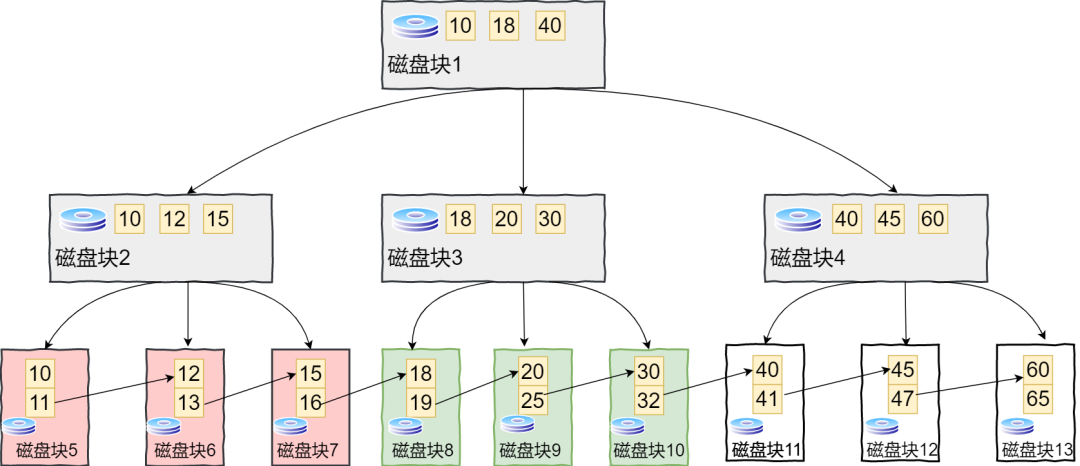
B+树性质
有m个孩子的节点就有m个关键字(孩子数量=关键字数),而在B树中孩子数量=关键字数+1
非叶子节点关键字也会出现在子节点中,而且子节点中为所有关键字的最大或最小
非叶子节点只是用来索引,不保存数据的记录。在B树中,非叶子节点既保存索引也保存数据记录。所有关键字都存在于叶子节点,叶子节点构成有序链表,而且关键字按照从大到小或者从小到大顺序连接。
优点:
因为B+树中间节点没有关键字,所以同样大小的磁盘页可以容纳更多的节点元素,也就是说在相同的情况下,B+树更加的矮胖,这样的话,IO的次数也就比较少。
B+树的查询相比B树更加稳定,因为B+树的查询是必须到叶子节点,而B树有可能在中间节点,也可能非中间节点。
B+树叶子节点形成了有序链表,更加有利于范围的查询
那么其查询的过程是什么样的呢。我们假设查询元素13
首先与根节点的关键字(10,18,40)比较,13在10和18之间,此时得到P1指针
磁盘2中的关键字为(10,12,15),这时15大于13,所有磁盘6
关键字为(12,13),找到13
六、 红黑树
虽然在大部分情况下,面试中不会让你写出来,在面试中还是经常会问原理的内容,所以了解了解更稳妥(比如c++中的很荣STL底层就是基于它),时间复杂度是O(lgn)。其基本概念如下。
1 红黑树的性质
首先红黑树的节点要么是红色,要么是黑色。
1 根节点是黑色的
2 每个叶子节点是黑色的且不存储数据
3 任何相邻的节点不能同时为红色
4 每个节点,从该节点到可达的叶子节点的所有路径,其黑色节点的数目相同。
参考连接
https://blog.csdn.net/isunbin/article/details/81707606
https://www.javatpoint.com/b-plus-tree
https://time.geekbang.org/column/intro/100029501
https://www.cnblogs.com/geektcp/p/9992213.html
