拜托!别再问我多线程的这些问题了

很多同学面对多线程的问题都很头大,因为自己做项目很难用到,但是但凡高薪的职位面试都会问到。。毕竟现在大厂里用的都是多线程高并发,所以这块内容不吃透肯定是不行的。
今天这篇文章,作为多线程的基础篇,先来谈谈以下问题:
为什么要用多线程? 程序 vs 进程 vs 线程 创建线程的 4 种方式?
为什么要用多线程
任何一项技术的出现都是为了解决现有问题。
之前的互联网大多是单机服务,体量小;而现在的更多是集群服务,同一时刻有多个用户同时访问服务器,那么会有很多线程并发访问。
比如在电商系统里,同一时刻比如整点抢购时,大量用户同时访问服务器,所以现在公司里开发的基本都是多线程的。
使用多线程确实提高了运行的效率,但与此同时,我们也需要特别注意数据的增删改情况,这就是线程安全问题,比如之前说过的 HashMap vs HashTable,Vector vs ArrayList。
要保证线程安全也有很多方式,比如说加锁,但又可能会出现其他问题比如死锁,所以多线程相关问题会比较麻烦。
因此,我们需要理解多线程的原理和它可能会产生的问题以及如何解决问题,才能拿下高薪职位。
进程 vs 线程
程序 program
说到进程,就不得不先说说程序。
程序,说白了就是代码,或者说是一系列指令的集合。比如「微信.exe」这就是一个程序,这个文件最终是要拿到 CPU 里面去执行的。
进程 process
当程序运行起来,它就是一个进程。
所以程序是“死”的,进程是“活”的。
比如在任务管理器里的就是一个个进程,就是“动起来”的应用程序。
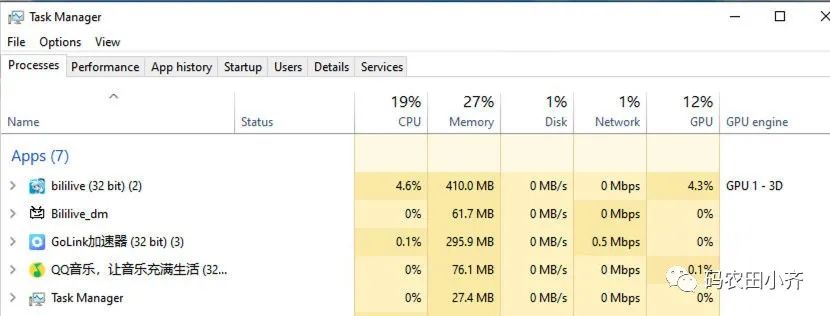
Q:这些进程是并行执行的吗?
单核 CPU 一个时间片里只能执行一个进程。但是因为它切换速度很快,所以我们感受不到,就造成了一种多进程的假象。(多核 CPU 那真的就是并行执行的了。)
Q:那如果这个进程没执行完呢?
当进程 A 执行完一个时间片,但是还没执行完时,为了方便下次接着执行,要保存刚刚执行完的这些数据信息,叫做「保存现场」。
然后等下次再抢到了资源执行的时候,先「恢复现场」,再开始继续执行。
这样循环往复。。
这样反复的保存啊、恢复啊,都是额外的开销,也会让程序执行变慢。
Q:有没有更高效的方式呢?
如果两个线程归属同一个进程,就不需要保存、恢复现场了。
这就是 NIO 模型的思路,也是 NIO 模型比 BIO 模型效率高很多的原因,我们之后再讲。
线程 thread
线程,是一个进程里的具体的执行路径,就是真正干活的。
在一个进程里,一个时间片也只能有一个线程在执行,但因为时间片的切换速度非常快,所以看起来就好像是同时进行的。
一个进程里至少有一个线程。比如主线程,就是我们平时写的 main() 函数,是用户线程;还有 gc 线程是 JVM 生产的,负责垃圾回收,是守护线程。
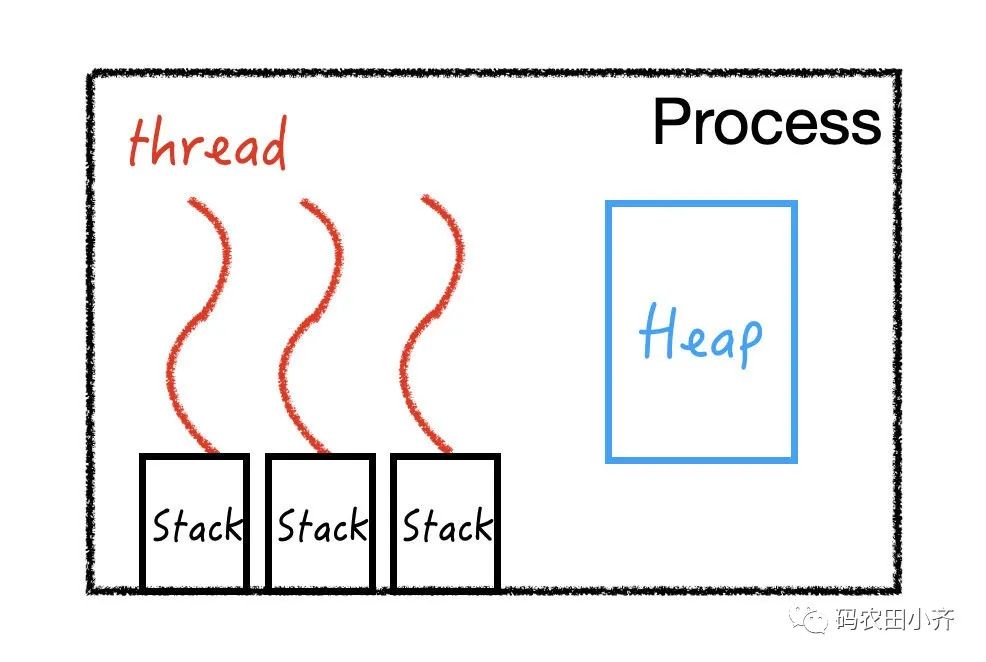
每个线程有自己的栈 stack,记录该线程里面的方法相互调用的关系;
但是一个进程里的所有线程是共用堆 heap 的。
那么不同的进程之间是不可以互相访问内存的,每个进程有自己的内存空间 memeory space,也就是虚拟内存 virtual memory。
通过这个虚拟内存,每一个进程都感觉自己拥有了整个内存空间。
虚拟内存的机制,就是屏蔽了物理内存的限制。
Q:那如果物理内存被用完了呢?
用硬盘,比如 windows 系统的分页文件,就是把一部分虚拟内存放到了硬盘上。
相应的,此时程序运行会很慢,因为硬盘的读写速度比内存慢很多,是我们可以感受到的慢,这就是为什么开多了程序电脑就会变卡的原因。
Q:那这个虚拟内存是有多大呢?
对于 64 位操作系统来说,每个程序可以用 64 个二进制位,也就是 2^64 这么大的空间!
总结
总结一下,在一个时间片里,一个 CPU 只能执行一个进程。
CPU 给某个进程分配资源后,这个进程开始运行;进程里的线程去抢占资源,一个时间片就只有一个线程能执行,谁先抢到就是谁的。
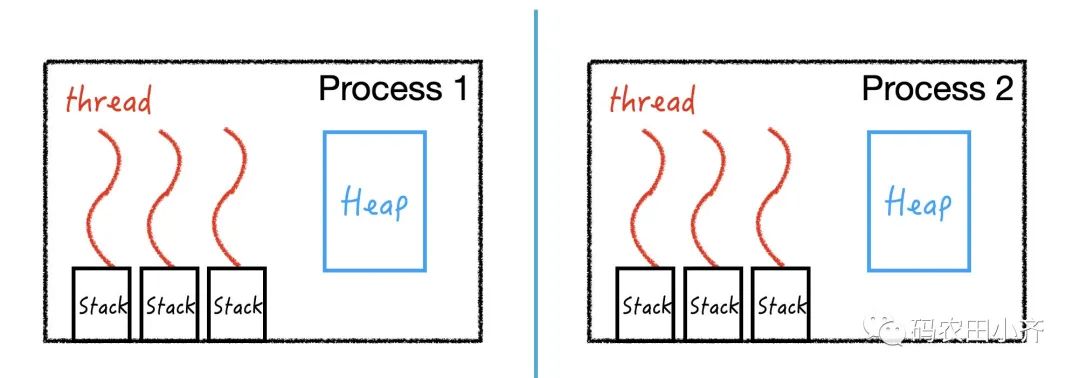
多进程 vs 多线程
每个进程是独立的,进程 A 出问题不会影响到进程 B;
虽然线程也是独立运行的,但是一个进程里的线程是共用同一个堆,如果某个线程 out of memory,那么这个进程里所有的线程都完了。
所以多进程能够提高系统的容错性 fault tolerance ,而多线程最大的好处就是线程间的通信非常方便。
进程之间的通信需要借助额外的机制,比如进程间通讯 interprocess communication - IPC,或者网络传递等等。
如何创建线程
上面说了一堆概念,接下来我们看具体实现。
Java 中是通过 java.lang.Thread 这个类来实现多线程的功能的,那我们先来看看这个类。
从文档中我们可以看到,Thread 类是直接继承 Object 的,同时它也是实现了 Runnable 接口。
官方文档里也写明了 2 种创建线程的方式:
一种方式是从 Thread 类继承,并重写 run(),run() 方法里写的是这个线程要执行的代码;
启动时通过 new 这个 class 的一个实例,调用 start() 方法启动线程。

二是实现 Runnable 接口,并实现 run(),run() 方法里同样也写的是这个线程要执行的代码;
稍有不同的是启动线程,需要 new 一个线程,并把刚刚创建的这个实现了 Runnable 接口的类的实例传进去,再调用 start(),这其实是代理模式。

如果面试官问你,还有没有其他的,那还可以说:
实现
Callable接口;通过线程池来启动一个线程。
但其实,用线程池来启动线程时也是用的前两种方式之一创建的。
这两种方式在这里就不细说啦,我们具体来看前两种方式。
继承 Thread 类
public class MyThread extends Thread {
@Override
public void run() {
for (int i = 0; i < 100; i++) {
System.out.println("小齐666:" + i);
}
}
public static void main(String[] args) {
MyThread myThread = new MyThread();
myThread.start();
for (int i = 0; i < 100; i++) {
System.out.println("主线程" + i + ":齐姐666");
}
}
}
在这里,
main函数是主线程,是程序的入口,执行整个程序;程序开始执行后先启动了一个新的线程
myThread,在这个线程里输出“小齐”;主线程并行执行,并输出“主线程i:齐姐”。
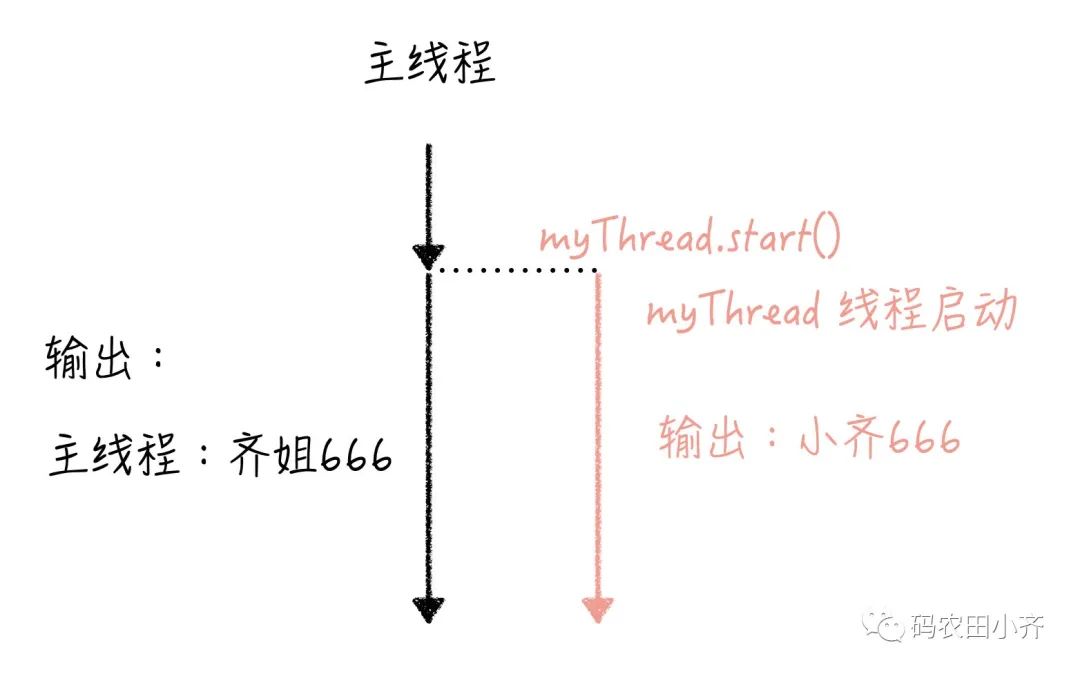
来看下结果,就是两个线程交替夸我嘛~
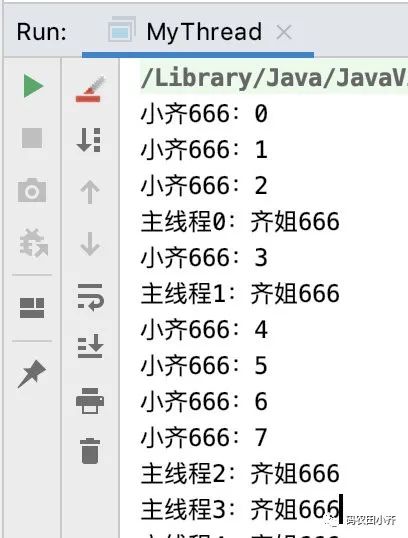
Q:为啥和我运行的结果不一样?
多线程中,每次运行的结果可能都会不一样,因为我们无法人为控制哪条线程在什么时刻先抢到资源。
当然了,我们可以给线程加上优先级 priority,但高优先级也无法保证这条线程一定能先被执行,只能说有更大的概率抢到资源先执行。
实现 Runnable 接口
这种方式用的更多。
public class MyRunnable implements Runnable {
@Override
public void run() {
for(int i = 0; i < 100; i++) {
System.out.println("小齐666:" + i);
}
}
public static void main(String[] args) {
new Thread(new MyRunnable()).start();
for(int i = 0; i < 100; i++) {
System.out.println("主线程" + i + ":齐姐666");
}
}
}
结果也差不多:
像前文所说,这里线程启动的方式和刚才的稍有不同,因为新建的的这个类只是实现了 Runnable 接口,所以还需要一个线程来“代理”执行它,所以需要把我们新建的这个类的实例传入到一个线程里,这里其实是代理模式。这个设计模式之后再细讲。
小结
那这两种方式哪种好呢?
使用 Runnable 接口更好,主要原因是 Java 单继承。
另外需要注意的是,在启动线程的的时候用的是 start(),而不是 run()。
调用 run() 仅仅是调用了这个方法,是普通的方法调用;而 start() 才是启动线程,然后由 JVM 去调用该线程的 run() 。

推荐阅读:
 喜欢我可以给我设为星标哦
喜欢我可以给我设为星标哦