
技术角度看数据中台(一):数据埋点
数据中台专题从今天开始分享啦~
因该体系涉及的技术点比较多,所以作为一个系列来分享。今天主要跟大家分享系统整体架构和数据埋点。
ps:下文说的“埋点sdk”指的是开发封装好的一份埋点代码,需要接入埋点的用户,可以通过在前端代码引入此sdk来上报数据。“用户”指的是接入我们埋点sdk的公司客户。
目录
1、系统关键架构
2、埋点类型
3、埋点核心数据模型
系统关键架构
要搭建出一个用户行为采集和分析系统,一般需要以下功能模块:
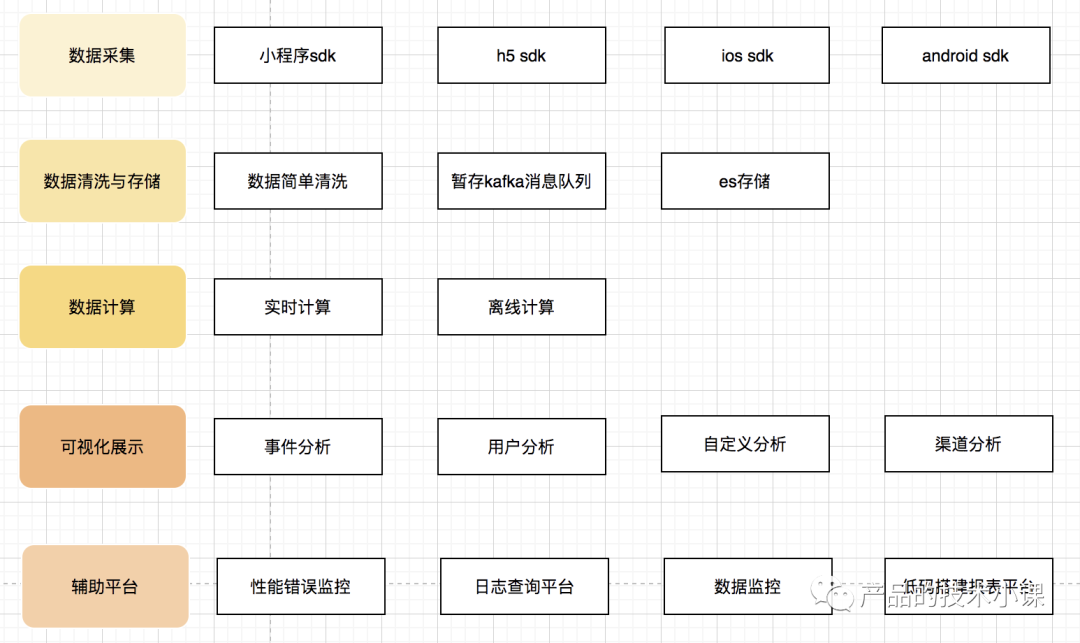
这个也是整体的架构。主要包括数据采集sdk、数据清洗与存储服务、数据计算、辅助平台、可视化展示模块。
因不同的载体,环境不同,开发语言不同,所以数据采集sdk可以分为小程序sdk,h5 sdk,ios sdk和android sdk。可根据自己用户群体常使用的平台,开发相应的sdk。
埋点类型
数据采集与上报是整个流程中最重要的一环,只有确保数据的全面、准确、及时,最后得到的结果才是可靠的、有价值的。
从采集方案上,可分为以下3种采集类型。
1、代码埋点
代码埋点指的是,用户通过浏览、点击等触发的事件,要通过调用sdk的方法上报事件的数据。友盟、百度统计等采用了这种方案。
优点:
1)精准的定位埋点位置
2)可以采集到更多自定义的数据
缺点:
1)埋点效率低
每次有新页面,都要根据需求埋点。
使用场景:适用于精准定位埋点位置、采集更多跟业务相关数据的复杂场景。
2、全埋点
全埋点也叫无埋点,全埋点不是说不用埋点,而是sdk自动采集所有事件并上报,然后后台通过一定的规则把想要的数据清洗出来。代表方案是国内的growing io。
优点:
1)埋点效率高
不需要每次产品提一次需求,就找所有开发包括前端、后台、数据过一遍埋点需求。
2)不容易出错
因为全埋点是直接上报了所有的用户行为事件,避免手工埋点失误。
3)有利于做自定义分析
因为数据比较全,如果用户想要知道某个按钮的点击次数,那只要搜索这个按钮的唯一id,后台就可以把按钮的点击次数搜索出来了。
缺点:
1)数据量庞大
全埋点把所有的事件数据都上报,数据量比较庞大,增大了服务器、数据清洗的压力。
使用场景:适用于采集更多的用户行为数据,做自定义分析,以及想提高埋点效率的场景。
3、可视化埋点
指的是通过一个可视化的埋点工具,运营人员圈选好需要埋点的控件和属性,sdk接收到服务端下发的埋点事件列表后,自动上报相应的埋点。
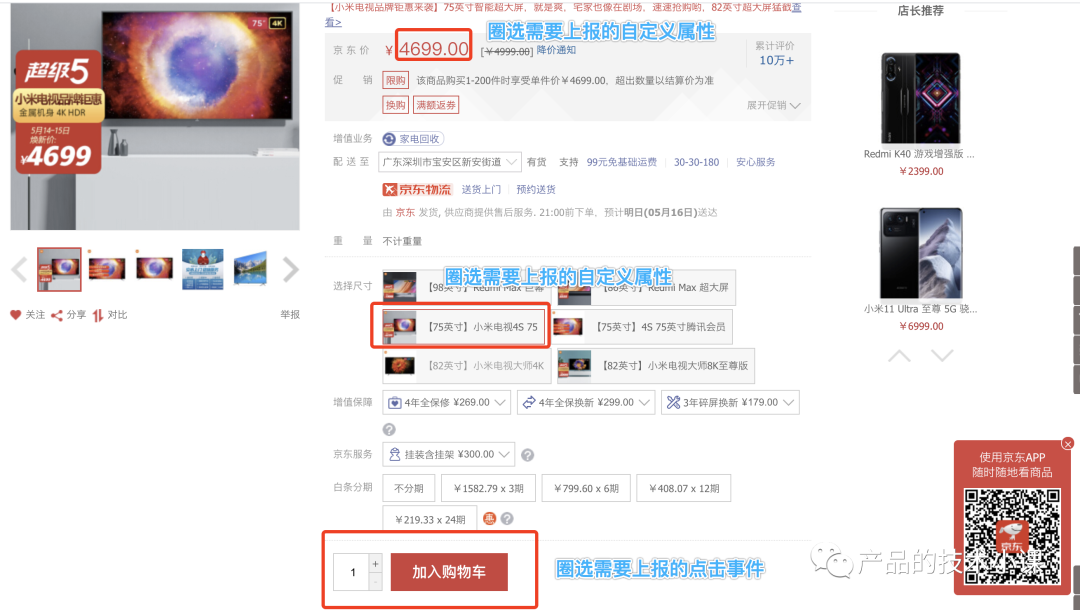
举个例子,当运营想要上线一个活动,但是这个活动也一样需要埋点。假设她想要埋一个当用户点击购物车时,把商品的规格、价格也上报。
这个需求用全埋点的方案是做不到的,因为你不知道要上报哪些自定义属性。
这时可视化埋点的作用就很明显了。看下图,运营圈选了要上报的事件:“加入购物车”,圈选“属性”: 商品价格、商品尺寸。
优点:
1)提高埋点效率
运营人员可直接埋点,无需开发介入
缺点:
1)容易受界面控件位置的影响
当你圈选要埋点的控件时,sdk会自动找出控件在界面的唯一位置,但是如果界面的结构发生了变化,比如改变了控件的位置,上报时可能就找不到该控件了。所以为了上报数据的稳定性,一般会增加一个预警机制,如果在一定周期内,同一个事件上报量明显下降,则告警客户,数据埋点可能出现了问题。
2)只能上报视觉范围内的属性
它只能圈选看得见的控件属性,如果用户想要上报的数据是异步产生的,看不见的,就只能用代码埋点的方案来上报了。
适用场景:适用于生命周期比较短页面的埋点,比如运营活动页面。
小结: 一般来说,一个成熟的sdk,这3种埋点都要支持,因为他们的适用场景是不一样的,3种埋点方式结合使用比较合理。代码埋点用于埋业务数据复杂的场景,全埋点用于收集更多的用户数据做自定义分析等数据挖掘场景,可视化埋点用于运营活动页面等生命周期较短的页面场景。
埋点核心数据模型
事件和用户是数据上报的2大核心内容。
一、事件模型
当我们点击一个控件时,要上报哪些内容才能全面的分析这个点击行为呢?
看下图:
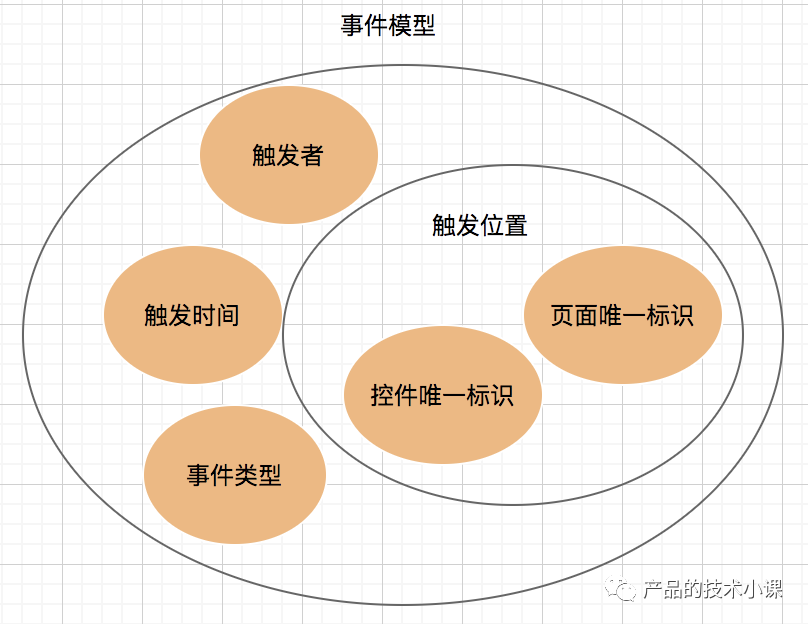
准确的说,一个事件的触发,有4个因素:
1、触发者
触发者即触发事件的用户。需要一个唯一标识,来识别不同的用户。下面的用户模型将会讲到。
2、触发位置
如何识别一个网页里面,事件触发的位置?需要一个页面的唯一标识和控件的唯一标识。
页面的唯一标识一般通过url标记,但要处理好url后面的参数。控件的唯一标识一般通过元素在整个文档中的xpath路径来标记。
xpath是啥?就是能唯一标记控件在网页的唯一位置的一种标记方法。
3、触发的事件
事件类型有浏览、点击、曝光、悬浮,下拉、滚动、长按、右键等等,最常用的还是浏览和点击。
4、触发的时间
事件触发的时间一般取的是客户端时间,也就是用户的本地时间,如果用户的设备是移动端,取的就是手机时间,如果是电脑,取的就是电脑的时间。
但是客户端的时间不太准确,因为用户可以去更改设备时间。
所以我们需要一个机制去校准客户端时间。一般的做法是,在上报事件时,我们会上报事件触发时间t1和数据发送时间t2,服务端也会拿到一个接收数据的时间t3,如果t3-t2>60s,则认为客户端时间不准,要对客户端时间进行修正,修正后的客户端时间是:t1 + (t3 - t2) 。
为啥t3-t2>60s会认为不准,因为数据发送到接收的时间,一般不会超过60s。
二、用户模型
每个用户都需要一个唯一标识。选择一个合适的用户标识对于用户行为分析的准确性有很大的影响。
这里说的唯一标识是发生事件行为用户id在数据中台的标记,不是业务中的登录id。
1)小程序用户
如果是小程序用户,可直接使用用户的openid,需要上报用户openid和unionid。如果同一个微信开放平台账号下,有多个小程序/公众号,就可以通过unionid来打通用户体系。
2)h5用户
如果是h5用户的话,sdk会创建一个uuid来唯一标记用户,uuid根据用户的浏览器类型、屏幕宽高、分辨率等特性生成。
3)app用户
优先使用设备id来唯一标记用户,但如果取不到设备id,则使用一个sdk创建一个随机的uuid来标记。
如果是游客,并且游客后面登录了系统,该如何把游客和已登录状态的用户id的行为数据关联起来?
如果用户在未登录状态下触发了事件,那么sdk会创建一个uuid来唯一标记这个用户,uuid不仅会随着行为数据上报,也会存在本地存储中,如果以后用户注册登录了,就可以拿这个uuid去跟登录id去做关联,就可以把以前用户未登录时的行为事件数据和已登录状态的行为数据关联起来。
--- end ---
专题第一篇写到这就完了,后面大概率会写埋点上报的稳定性保障、数据监控、数据清洗、数据可视化等内容。
如果看的人多的话,就继续往下写吧😆。码字不易,如果觉得写的不错的话,麻烦帮忙点下在看/分享,感恩。
推荐8款好用的数据采集工具
爬虫的基本原理及应用场景
一文讲透文件上传
如何做一次完美的 ABTest?