
Spark:RDD任务切分之Stage任务划分(图解和源码)
微信公众号:王了个博
专注于大数据技术,人工智能和编程语言
个人既可码代码也可以码文字。欢迎转发与关注
RDD任务切分中间分为:Application、Job、Stage和Task
(1)Application:初始化一个SparkContext即生成一个Application;
(2)Job:一个Action算子就会生成一个Job;
(3)Stage:Stage等于宽依赖的个数加1;
(4)Task:一个Stage阶段中,最后一个RDD的分区个数就是Task的个数。
注意:Application->Job->Stage->Task每一层都是1对n的关系
主要步骤
代码样例:主程序
1// 代码样例
2def main(args: Array[String]): Unit = {
3 //1.创建SparkConf并设置App名称
4 val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
5 //2.创建SparkContext,该对象是提交Spark App的入口
6 val sc: SparkContext = new SparkContext(conf)
7 val rdd:RDD[String] = sc.textFile("input/1.txt")
8 val mapRdd = rdd.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
9 mapRdd.saveAsTextFile("outpath")
10 //3.关闭连接
11 sc.stop()
12 }
执行流程图(Yarn-Cluster)
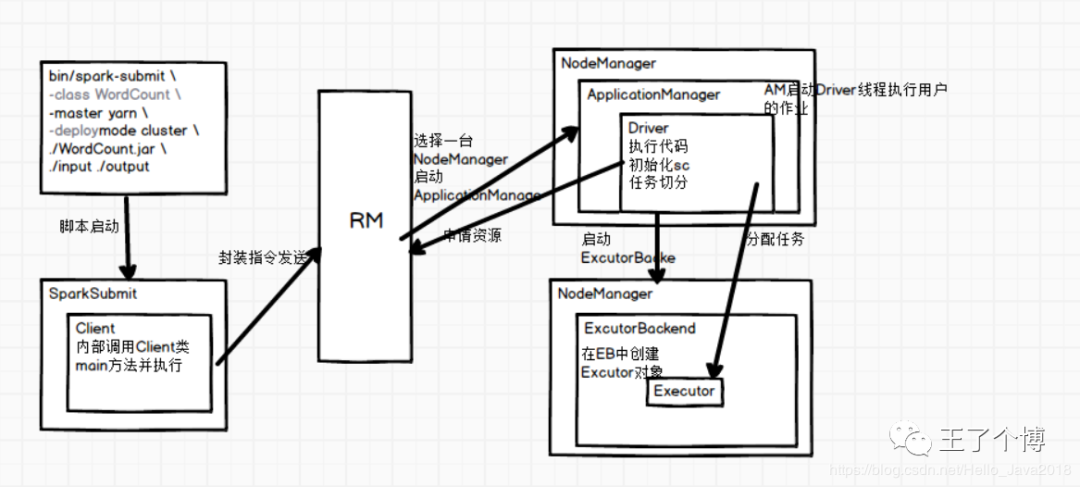
现在一步一步分析
1. 第一步
执行main方法
初始化sc
执行到Action算子
这个阶段会产生血缘依赖关系,具体的数据处理还没有开始
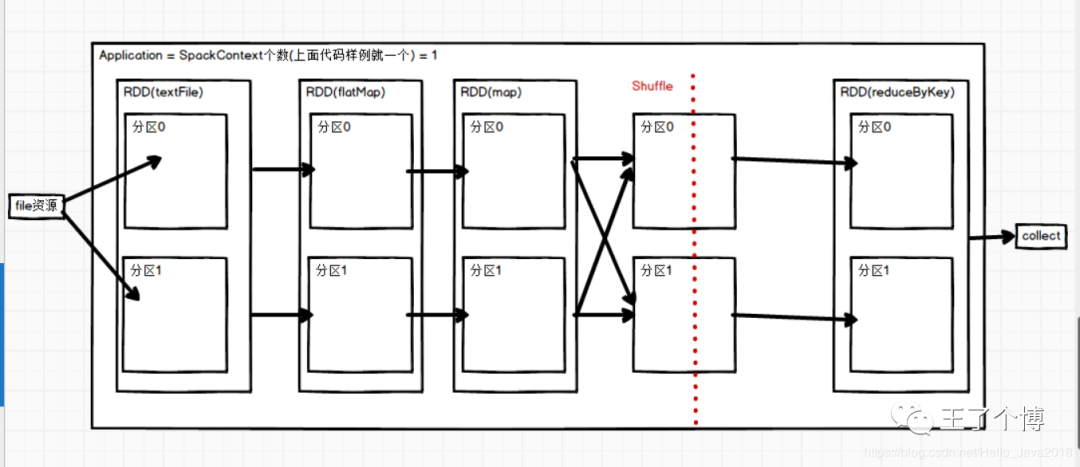
2. 第二步:DAGScheduler对上面的job切分stage,stage产生task
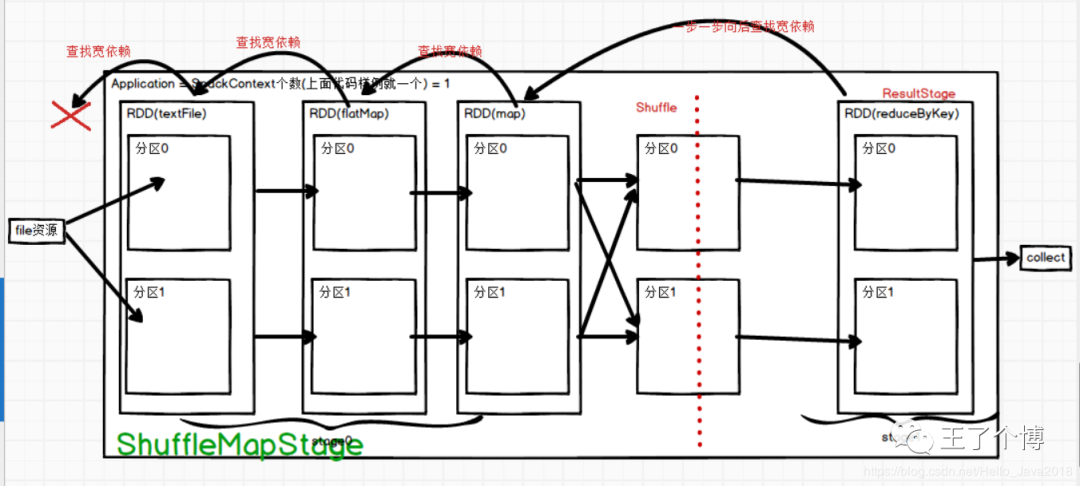
DAGScheduler:先划分阶段(stage)再划分任务(task)
这个时候会产生Job的stage个数 = 宽依赖的个数+1 = 2 (这个地方产生一个宽依赖),也就是产生shuffle这个地方
Job的Task个数= 一个stage阶段中,最后一个RDD的分区个数就是Task的个数(2+2 =4)
shuffle前的ShuffleStage产生两个,shuffle后reduceStage产生两个
3. 第三步:TaskSchedule通过TaskSet获取job的所有Task,然后序列化分给Exector
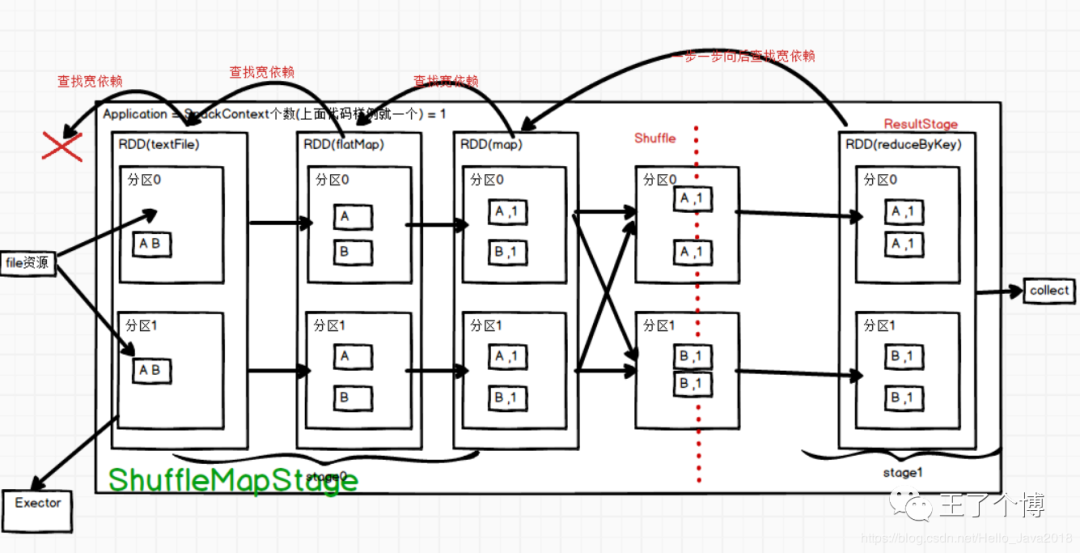
job的个数也就是 = Action算子的个数(这里只一个collect)= 1
源码分析
一步一步从 collect()方法 找会找到这段主要代码
collect()方法中找
1var finalStage: ResultStage = null
2 try {
3 // New stage creation may throw an exception if, for example, jobs are run on a
4 // HadoopRDD whose underlying HDFS files have been deleted.
5 finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite)
6 } catch {
7 case e: Exception =>
8 logWarning("Creating new stage failed due to exception - job: " + jobId, e)
9 listener.jobFailed(e)
10 return
11 }
finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite)
根据上面图片流程,程序需要找到最后一个Rdd然后创建ResultStage
ResultStage的创建
1private def createResultStage(
2 rdd: RDD[_],
3 func: (TaskContext, Iterator[_]) => _,
4 partitions: Array[Int],
5 jobId: Int,
6 callSite: CallSite): ResultStage = {
7 val parents = getOrCreateParentStages(rdd, jobId)
8 val id = nextStageId.getAndIncrement()
9 val stage = new ResultStage(id, rdd, func, partitions, parents, jobId, callSite)
10 stageIdToStage(id) = stage
11 updateJobIdStageIdMaps(jobId, stage)
12 stage
13 }R
14
stage = new ResultStage(id, rdd, func, partitions, parents, jobId, callSite)
parents = getOrCreateParentStages(rdd, jobId)
上面的createResultStage会创建一个ResultStage,同时给这个Stage 找到parents,也就是血缘依赖关系
3. getOrCreateParentStages(血缘依赖关系)
1private def getOrCreateParentStages(rdd: RDD[_], firstJobId: Int): List[Stage] = {
2 getShuffleDependencies(rdd).map { shuffleDep =>
3 getOrCreateShuffleMapStage(shuffleDep, firstJobId)
4 }.toList
5 }
1private[scheduler] def getShuffleDependencies(
2 rdd: RDD[_]): HashSet[ShuffleDependency[_, _, _]] = {
3 val parents = new HashSet[ShuffleDependency[_, _, _]]
4 val visited = new HashSet[RDD[_]]
5 val waitingForVisit = new Stack[RDD[_]]
6 waitingForVisit.push(rdd)
7 while (waitingForVisit.nonEmpty) {
8 val toVisit = waitingForVisit.pop()
9 if (!visited(toVisit)) {
10 visited += toVisit
11 toVisit.dependencies.foreach {
12 case shuffleDep: ShuffleDependency[_, _, _] =>
13 parents += shuffleDep
14 case dependency =>
15 waitingForVisit.push(dependency.rdd)
16 }
17 }
18 }
19 parents
20 }
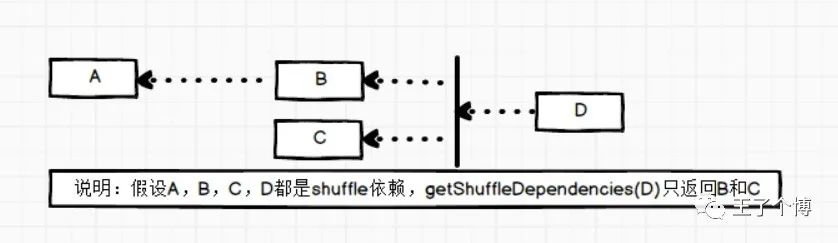
说明:假设A,B,C,D都是shuffle依赖,getShuffleDependencies(D)只返回B和C
然后把上面返回的B,C分别遍历,然后创建对应的Stage
即方法getOrCreateShuffleMapStage
4. getOrCreateShuffleMapStage
1private def getOrCreateShuffleMapStage(
2 shuffleDep: ShuffleDependency[_, _, _],
3 firstJobId: Int): ShuffleMapStage = {
4 shuffleIdToMapStage.get(shuffleDep.shuffleId) match {
5 case Some(stage) =>
6 stage
7
8 case None =>
9 // Create stages for all missing ancestor shuffle dependencies.
10 getMissingAncestorShuffleDependencies(shuffleDep.rdd).foreach { dep =>
11
12 if (!shuffleIdToMapStage.contains(dep.shuffleId)) {
13 createShuffleMapStage(dep, firstJobId)
14 }
15 }
16 // Finally, create a stage for the given shuffle dependency.
17 createShuffleMapStage(shuffleDep, firstJobId)
18 }
19 }
对于不存在的ShuffleMapStage, 调用createShuffleMapStage创建stage
5. ShuffleMapStage创建
1def createShuffleMapStage(shuffleDep: ShuffleDependency[_, _, _], jobId: Int): ShuffleMapStage = {
2 val rdd = shuffleDep.rdd
3 val numTasks = rdd.partitions.length
4 val parents = getOrCreateParentStages(rdd, jobId)
5 val id = nextStageId.getAndIncrement()
6 val stage = new ShuffleMapStage(id, rdd, numTasks, parents, jobId, rdd.creationSite, shuffleDep)
也即最后一句创建了ShuffleMapStage,剩下的就是提交Stage了
以上ResultStage和ShuffleMapStage创建好了(图中可体现过程)
6. handleJobSubmitted() 执行代码
1private[scheduler] def handleJobSubmitted(jobId: Int,
2 finalRDD: RDD[_],
3 func: (TaskContext, Iterator[_]) => _,
4 partitions: Array[Int],
5 callSite: CallSite,
6 listener: JobListener,
7 properties: Properties) {
8 var finalStage: ResultStage = null
9 try {
10 // New stage creation may throw an exception if, for example, jobs are run on a
11 // HadoopRDD whose underlying HDFS files have been deleted.
12 finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite)
13 } catch {
14 case e: Exception =>
15 logWarning("Creating new stage failed due to exception - job: " + jobId, e)
16 listener.jobFailed(e)
17 return
18 }
19
20 val job = new ActiveJob(jobId, finalStage, callSite, listener, properties)
21 clearCacheLocs()
22 logInfo("Got job %s (%s) with %d output partitions".format(
23 job.jobId, callSite.shortForm, partitions.length))
24 logInfo("Final stage: " + finalStage + " (" + finalStage.name + ")")
25 logInfo("Parents of final stage: " + finalStage.parents)
26 logInfo("Missing parents: " + getMissingParentStages(finalStage))
27
28 val jobSubmissionTime = clock.getTimeMillis()
29 jobIdToActiveJob(jobId) = job
30 activeJobs += job
31 finalStage.setActiveJob(job)
32 val stageIds = jobIdToStageIds(jobId).toArray
33 val stageInfos = stageIds.flatMap(id => stageIdToStage.get(id).map(_.latestInfo))
34 listenerBus.post(
35 SparkListenerJobStart(job.jobId, jobSubmissionTime, stageInfos, properties))
36 submitStage(finalStage)
37 }
val job = new ActiveJob(jobId, finalStage, callSite, listener, properties)
finalStage.setActiveJob(job)
找到finalStage后(也即上面源码分析中的ResultStage),把最后阶段传了进来,需要和Job联系在一起
7. submitStage(finalStage)
1private def submitStage(stage: Stage) {
2 val jobId = activeJobForStage(stage)
3 if (jobId.isDefined) {
4 logDebug("submitStage(" + stage + ")")
5 if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
6 val missing = getMissingParentStages(stage).sortBy(_.id)
把最后阶段的finalStage(ResultStage)交给了getMissingParentStages 主要目的是找前面的stage
8. getMissingParentStages()
1private def getMissingParentStages(stage: Stage): List[Stage] = {
2 val missing = new HashSet[Stage]
3 val visited = new HashSet[RDD[_]]
4 // We are manually maintaining a stack here to prevent StackOverflowError
5 // caused by recursively visiting
6 val waitingForVisit = new Stack[RDD[_]]
7 def visit(rdd: RDD[_]) {
8 if (!visited(rdd)) {
9 visited += rdd
10 val rddHasUncachedPartitions = getCacheLocs(rdd).contains(Nil)
11 if (rddHasUncachedPartitions) {
12 for (dep <- rdd.dependencies) {
13 dep match {
14 case shufDep: ShuffleDependency[_, _, _] =>
15 val mapStage = getOrCreateShuffleMapStage(shufDep, stage.firstJobId)
16 if (!mapStage.isAvailable) {
17 missing += mapStage
18 }
19 case narrowDep: NarrowDependency[_] =>
20 waitingForVisit.push(narrowDep.rdd)
21 }
22 }
23 }
24 }
25 }
26 waitingForVisit.push(stage.rdd)
27 while (waitingForVisit.nonEmpty) {
28 visit(waitingForVisit.pop())
29 }
30 missing.toList
31 }
主要看def visit(rdd: RDD[_])
for (dep <- rdd.dependencies) 还是找ShuffleDependency 一直到找不到为止,会把ShuffleDependency添加到missing中(看有几个shuffle)
开始执行submitMissingTasks,执行的时候会找到有多少Task
9. submitMissingTasks()
1private def submitMissingTasks(stage: Stage, jobId: Int) {
2 val tasks: Seq[Task[_]] = try {
3 stage match {
4 case stage: ShuffleMapStage =>
5 partitionsToCompute.map { id =>
6 val locs = taskIdToLocations(id)
7 val part = stage.rdd.partitions(id)
8 new ShuffleMapTask(stage.id, stage.latestInfo.attemptId,
9 taskBinary, part, locs, stage.latestInfo.taskMetrics, properties, Option(jobId),
10 Option(sc.applicationId), sc.applicationAttemptId)
11 }
12
13 case stage: ResultStage =>
14 partitionsToCompute.map { id =>
15 val p: Int = stage.partitions(id)
16 val part = stage.rdd.partitions(p)
17 val locs = taskIdToLocations(id)
18 new ResultTask(stage.id, stage.latestInfo.attemptId,
19 taskBinary, part, locs, id, properties, stage.latestInfo.taskMetrics,
20 Option(jobId), Option(sc.applicationId), sc.applicationAttemptId)
21 }
22 }
23}
24
25
26override def findMissingPartitions(): Seq[Int] = {
27 val missing = (0 until numPartitions).filter(id => outputLocs(id).isEmpty)
28 assert(missing.size == numPartitions - _numAvailableOutputs,
29 s"${missing.size} missing, expected ${numPartitions - _numAvailableOutputs}")
30 missing
31 }
如果ShuffleMapStage阶段最后的Rdd有两个分区
missing返回的就是 0 和 1
10. partitionsToCompute()
1partitionsToCompute.map { id =>
2 val locs = taskIdToLocations(id)
3 val part = stage.rdd.partitions(id)
4 new ShuffleMapTask(stage.id, stage.latestInfo.attemptId,
5 taskBinary, part, locs, stage.latestInfo.taskMetrics, properties, Option(jobId),
6 Option(sc.applicationId), sc.applicationAttemptId)
7 }
有两个分区,也就会new 两个 ShuffleMapTask,也就两个Task任务
匹配result的原理一样,不再阐述
11. 和第9步submitMissingTasks()同列代码
1if (tasks.size > 0) {
2 logInfo("Submitting " + tasks.size + " missing tasks from " + stage + " (" + stage.rdd + ")")
3 stage.pendingPartitions ++= tasks.map(_.partitionId)
4 logDebug("New pending partitions: " + stage.pendingPartitions)
5 taskScheduler.submitTasks(new TaskSet(
6 tasks.toArray, stage.id, stage.latestInfo.attemptId, jobId, properties))
7 stage.latestInfo.submissionTime = Some(clock.getTimeMillis())
8 }
taskScheduler.submitTasks 提交任务
12. submitTasks()
1override def submitTasks(taskSet: TaskSet) {
2 val tasks = taskSet.tasks
3 logInfo("Adding task set " + taskSet.id + " with " + tasks.length + " tasks")
4 this.synchronized {
5 val manager = createTaskSetManager(taskSet, maxTaskFailures)
6 val stage = taskSet.stageId
7 val stageTaskSets =
8 taskSetsByStageIdAndAttempt.getOrElseUpdate(stage, new HashMap[Int, TaskSetManager])
9 stageTaskSets(taskSet.stageAttemptId) = manager
10 val conflictingTaskSet = stageTaskSets.exists { case (_, ts) =>
11 ts.taskSet != taskSet && !ts.isZombie
12 }
13......
相关阅读: