
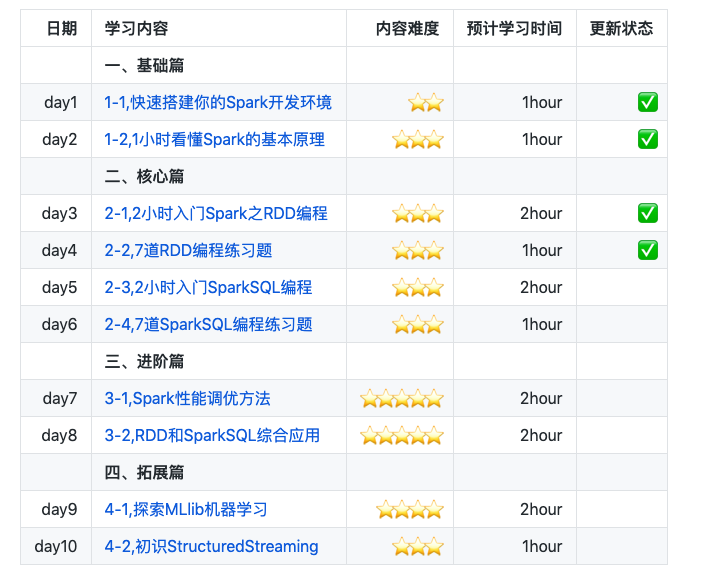
2小时入门Spark之RDD编程
公众号后台回复关键字:pyspark,获取本项目github地址。
本节将介绍RDD数据结构的常用函数。包括如下内容:
- 创建RDD
- 常用Action操作
- 常用Transformation操作
- 常用PairRDD的转换操作
- 缓存操作
- 共享变量
- 分区操作
这些函数中,我最常用的是如下15个函数,需要认真掌握其用法。
- map
- flatMap
- mapPartitions
- filter
- count
- reduce
- take
- saveAsTextFile
- collect
- join
- union
- persist
- repartition
- reduceByKey
- aggregateByKey
import findspark
#指定spark_home为刚才的解压路径,指定python路径
spark_home = "/Users/liangyun/ProgramFiles/spark-3.0.1-bin-hadoop3.2"
python_path = "/Users/liangyun/anaconda3/bin/python"
findspark.init(spark_home,python_path)
import pyspark
from pyspark import SparkContext, SparkConf
conf = SparkConf().setAppName("rdd_tutorial").setMaster("local[4]")
sc = SparkContext(conf=conf)
print(pyspark.__version__)
3.0.1
一,创建RDD
创建RDD主要有两种方式,一个是textFile加载本地或者集群文件系统中的数据,
第二个是用parallelize方法将Driver中的数据结构并行化成RDD。
#从本地文件系统中加载数据
file = "./data/hello.txt"
rdd = sc.textFile(file,3)
rdd.collect()
['hello world',
'hello spark',
'spark love jupyter',
'spark love pandas',
'spark love sql']
#从集群文件系统中加载数据
#file = "hdfs://localhost:9000/user/hadoop/data.txt"
#也可以省去hdfs://localhost:9000
#rdd = sc.textFile(file,3)
#parallelize将Driver中的数据结构生成RDD,第二个参数指定分区数
rdd = sc.parallelize(range(1,11),2)
rdd.collect()
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
二,常用Action操作
Action操作将触发基于RDD依赖关系的计算。
collect
rdd = sc.parallelize(range(10),5)
#collect操作将数据汇集到Driver,数据过大时有超内存风险
all_data = rdd.collect()
all_data
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
take
#take操作将前若干个数据汇集到Driver,相比collect安全
rdd = sc.parallelize(range(10),5)
part_data = rdd.take(4)
part_data
[0, 1, 2, 3]
takeSample
#takeSample可以随机取若干个到Driver,第一个参数设置是否放回抽样
rdd = sc.parallelize(range(10),5)
sample_data = rdd.takeSample(False,10,0)
sample_data
[7, 8, 1, 5, 3, 4, 2, 0, 9, 6]
first
#first取第一个数据
rdd = sc.parallelize(range(10),5)
first_data = rdd.first()
print(first_data)
0
count
#count查看RDD元素数量
rdd = sc.parallelize(range(10),5)
data_count = rdd.count()
print(data_count)
10
reduce
#reduce利用二元函数对数据进行规约
rdd = sc.parallelize(range(10),5)
rdd.reduce(lambda x,y:x+y)
45
foreach
#foreach对每一个元素执行某种操作,不生成新的RDD
#累加器用法详见共享变量
rdd = sc.parallelize(range(10),5)
accum = sc.accumulator(0)
rdd.foreach(lambda x:accum.add(x))
print(accum.value)
45
countByKey
#countByKey对Pair RDD按key统计数量
pairRdd = sc.parallelize([(1,1),(1,4),(3,9),(2,16)])
pairRdd.countByKey()
defaultdict(int, {1: 2, 3: 1, 2: 1})
saveAsTextFile
#saveAsTextFile保存rdd成text文件到本地
text_file = "./data/rdd.txt"
rdd = sc.parallelize(range(5))
rdd.saveAsTextFile(text_file)
#重新读入会被解析文本
rdd_loaded = sc.textFile(file)
rdd_loaded.collect()
['2', '3', '4', '1', '0']
三,常用Transformation操作
Transformation转换操作具有懒惰执行的特性,它只指定新的RDD和其父RDD的依赖关系,只有当Action操作触发到该依赖的时候,它才被计算。
map
#map操作对每个元素进行一个映射转换
rdd = sc.parallelize(range(10),3)
rdd.collect()
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
rdd.map(lambda x:x**2).collect()
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
filter
#filter应用过滤条件过滤掉一些数据
rdd = sc.parallelize(range(10),3)
rdd.filter(lambda x:x>5).collect()
[6, 7, 8, 9]
flatMap
#flatMap操作执行将每个元素生成一个Array后压平
rdd = sc.parallelize(["hello world","hello China"])
rdd.map(lambda x:x.split(" ")).collect()
[['hello', 'world'], ['hello', 'China']]
rdd.flatMap(lambda x:x.split(" ")).collect()
['hello', 'world', 'hello', 'China']
sample
#sample对原rdd在每个分区按照比例进行抽样,第一个参数设置是否可以重复抽样
rdd = sc.parallelize(range(10),1)
rdd.sample(False,0.5,0).collect()
[1, 4, 9]
distinct
#distinct去重
rdd = sc.parallelize([1,1,2,2,3,3,4,5])
rdd.distinct().collect()
[4, 1, 5, 2, 3]
subtract
#subtract找到属于前一个rdd而不属于后一个rdd的元素
a = sc.parallelize(range(10))
b = sc.parallelize(range(5,15))
a.subtract(b).collect()
[0, 1, 2, 3, 4]
union
#union合并数据
a = sc.parallelize(range(5))
b = sc.parallelize(range(3,8))
a.union(b).collect()
[0, 1, 2, 3, 4, 3, 4, 5, 6, 7]
intersection
#intersection求交集
a = sc.parallelize(range(1,6))
b = sc.parallelize(range(3,9))
a.intersection(b).collect()
[3, 4, 5]
cartesian
#cartesian笛卡尔积
boys = sc.parallelize(["LiLei","Tom"])
girls = sc.parallelize(["HanMeiMei","Lily"])
boys.cartesian(girls).collect()
[('LiLei', 'HanMeiMei'),
('LiLei', 'Lily'),
('Tom', 'HanMeiMei'),
('Tom', 'Lily')]
sortBy
#按照某种方式进行排序
#指定按照第3个元素大小进行排序
rdd = sc.parallelize([(1,2,3),(3,2,2),(4,1,1)])
rdd.sortBy(lambda x:x[2]).collect()
[(4, 1, 1), (3, 2, 2), (1, 2, 3)]
zip
#按照拉链方式连接两个RDD,效果类似python的zip函数
#需要两个RDD具有相同的分区,每个分区元素数量相同
rdd_name = sc.parallelize(["LiLei","Hanmeimei","Lily"])
rdd_age = sc.parallelize([19,18,20])
rdd_zip = rdd_name.zip(rdd_age)
print(rdd_zip.collect())
[('LiLei', 19), ('Hanmeimei', 18), ('Lily', 20)]
zipWithIndex
#将RDD和一个从0开始的递增序列按照拉链方式连接。
rdd_name = sc.parallelize(["LiLei","Hanmeimei","Lily","Lucy","Ann","Dachui","RuHua"])
rdd_index = rdd_name.zipWithIndex()
print(rdd_index.collect())
[('LiLei', 0), ('Hanmeimei', 1), ('Lily', 2), ('Lucy', 3), ('Ann', 4), ('Dachui', 5), ('RuHua', 6)]
四,常用PairRDD的转换操作
PairRDD指的是数据为长度为2的tuple类似(k,v)结构的数据类型的RDD,其每个数据的第一个元素被当做key,第二个元素被当做value.
reduceByKey
#reduceByKey对相同的key对应的values应用二元归并操作
rdd = sc.parallelize([("hello",1),("world",2),
("hello",3),("world",5)])
rdd.reduceByKey(lambda x,y:x+y).collect()
[('hello', 4), ('world', 7)]
groupByKey
#groupByKey将相同的key对应的values收集成一个Iterator
rdd = sc.parallelize([("hello",1),("world",2),("hello",3),("world",5)])
rdd.groupByKey().collect()
[('hello', ),
('world', )]
sortByKey
#sortByKey按照key排序,可以指定是否降序
rdd = sc.parallelize([("hello",1),("world",2),
("China",3),("Beijing",5)])
rdd.sortByKey(False).collect()
[('world', 2), ('hello', 1), ('China', 3), ('Beijing', 5)]
join
#join相当于根据key进行内连接
age = sc.parallelize([("LiLei",18),
("HanMeiMei",16),("Jim",20)])
gender = sc.parallelize([("LiLei","male"),
("HanMeiMei","female"),("Lucy","female")])
age.join(gender).collect()
[('LiLei', (18, 'male')), ('HanMeiMei', (16, 'female'))]
leftOuterJoin和rightOuterJoin
#leftOuterJoin相当于关系表的左连接
age = sc.parallelize([("LiLei",18),
("HanMeiMei",16)])
gender = sc.parallelize([("LiLei","male"),
("HanMeiMei","female"),("Lucy","female")])
age.leftOuterJoin(gender).collect()
[('LiLei', (18, 'male')), ('HanMeiMei', (16, 'female'))]
#rightOuterJoin相当于关系表的右连接
age = sc.parallelize([("LiLei",18),
("HanMeiMei",16),("Jim",20)])
gender = sc.parallelize([("LiLei","male"),
("HanMeiMei","female")])
age.rightOuterJoin(gender).collect()
[('LiLei', (18, 'male')), ('HanMeiMei', (16, 'female'))]
cogroup
#cogroup相当于对两个输入分别goupByKey然后再对结果进行groupByKey
x = sc.parallelize([("a",1),("b",2),("a",3)])
y = sc.parallelize([("a",2),("b",3),("b",5)])
result = x.cogroup(y).collect()
print(result)
print(list(result[0][1][0]))
[('a', (, )), ('b', (, ))]
[1, 3]
subtractByKey
#subtractByKey去除x中那些key也在y中的元素
x = sc.parallelize([("a",1),("b",2),("c",3)])
y = sc.parallelize([("a",2),("b",(1,2))])
x.subtractByKey(y).collect()
[('c', 3)]
foldByKey
#foldByKey的操作和reduceByKey类似,但是要提供一个初始值
x = sc.parallelize([("a",1),("b",2),("a",3),("b",5)],1)
x.foldByKey(1,lambda x,y:x*y).collect()
[('a', 3), ('b', 10)]
五,缓存操作
如果一个rdd被多个任务用作中间量,那么对其进行cache缓存到内存中对加快计算会非常有帮助。
声明对一个rdd进行cache后,该rdd不会被立即缓存,而是等到它第一次被计算出来时才进行缓存。
可以使用persist明确指定存储级别,常用的存储级别是MEMORY_ONLY和EMORY_AND_DISK。
如果一个RDD后面不再用到,可以用unpersist释放缓存,unpersist是立即执行的。
缓存数据不会切断血缘依赖关系,这是因为缓存数据某些分区所在的节点有可能会有故障,例如内存溢出或者节点损坏。
这时候可以根据血缘关系重新计算这个分区的数据。
#cache缓存到内存中,使用存储级别 MEMORY_ONLY。
#MEMORY_ONLY意味着如果内存存储不下,放弃存储其余部分,需要时重新计算。
a = sc.parallelize(range(10000),5)
a.cache()
sum_a = a.reduce(lambda x,y:x+y)
cnt_a = a.count()
mean_a = sum_a/cnt_a
print(mean_a)
#persist缓存到内存或磁盘中,默认使用存储级别MEMORY_AND_DISK
#MEMORY_AND_DISK意味着如果内存存储不下,其余部分存储到磁盘中。
#persist可以指定其它存储级别,cache相当于persist(MEMORY_ONLY)
from pyspark.storagelevel import StorageLevel
a = sc.parallelize(range(10000),5)
a.persist(StorageLevel.MEMORY_AND_DISK)
sum_a = a.reduce(lambda x,y:x+y)
cnt_a = a.count()
mean_a = sum_a/cnt_a
a.unpersist() #立即释放缓存
print(mean_a)
六,共享变量
当spark集群在许多节点上运行一个函数时,默认情况下会把这个函数涉及到的对象在每个节点生成一个副本。
但是,有时候需要在不同节点或者节点和Driver之间共享变量。
Spark提供两种类型的共享变量,广播变量和累加器。
广播变量是不可变变量,实现在不同节点不同任务之间共享数据。
广播变量在每个机器上缓存一个只读的变量,而不是为每个task生成一个副本,可以减少数据的传输。
累加器主要是不同节点和Driver之间共享变量,只能实现计数或者累加功能。
累加器的值只有在Driver上是可读的,在节点上不可见。
#广播变量 broadcast 不可变,在所有节点可读
broads = sc.broadcast(100)
rdd = sc.parallelize(range(10))
print(rdd.map(lambda x:x+broads.value).collect())
print(broads.value)
[100, 101, 102, 103, 104, 105, 106, 107, 108, 109]
100
#累加器 只能在Driver上可读,在其它节点只能进行累加
total = sc.accumulator(0)
rdd = sc.parallelize(range(10),3)
rdd.foreach(lambda x:total.add(x))
total.value
45
# 计算数据的平均值
rdd = sc.parallelize([1.1,2.1,3.1,4.1])
total = sc.accumulator(0.1)
count = sc.accumulator(0)
def func(x):
total.add(x)
count.add(1)
rdd.foreach(func)
total.value/count.value
2.625
七,分区操作
分区操作包括改变分区操作,以及针对分区执行的一些转换操作。
glom:将一个分区内的数据转换为一个列表作为一行。
coalesce:shuffle可选,默认为False情况下窄依赖,不能增加分区。repartition和partitionBy调用它实现。
repartition:按随机数进行shuffle,相同key不一定在同一个分区
partitionBy:按key进行shuffle,相同key放入同一个分区
HashPartitioner:默认分区器,根据key的hash值进行分区,相同的key进入同一分区,效率较高,key不可为Array.
RangePartitioner:只在排序相关函数中使用,除相同的key进入同一分区,相邻的key也会进入同一分区,key必须可排序。
TaskContext: 获取当前分区id方法 TaskContext.get.partitionId
mapPartitions:每次处理分区内的一批数据,适合需要分批处理数据的情况,比如将数据插入某个表,每批数据只需要开启一次数据库连接,大大减少了连接开支
mapPartitionsWithIndex:类似mapPartitions,提供了分区索引,输入参数为(i,Iterator)
foreachPartition:类似foreach,但每次提供一个Partition的一批数据
glom
#glom将一个分区内的数据转换为一个列表作为一行。
a = sc.parallelize(range(10),2)
b = a.glom()
b.collect()
[[0, 1, 2, 3, 4], [5, 6, 7, 8, 9]]
coalesce
#coalesce 默认shuffle为False,不能增加分区,只能减少分区
#如果要增加分区,要设置shuffle = true
#parallelize等许多操作可以指定分区数
a = sc.parallelize(range(10),3)
print(a.getNumPartitions())
print(a.glom().collect())
3
[[0, 1, 2], [3, 4, 5], [6, 7, 8, 9]]
b = a.coalesce(2)
print(b.glom().collect())
[[0, 1, 2], [3, 4, 5, 6, 7, 8, 9]]
repartition
#repartition按随机数进行shuffle,相同key不一定在一个分区,可以增加分区
#repartition实际上调用coalesce实现,设置了shuffle = True
a = sc.parallelize(range(10),3)
c = a.repartition(4)
print(c.glom().collect())
[[6, 7, 8, 9], [3, 4, 5], [], [0, 1, 2]]
#repartition按随机数进行shuffle,相同key不一定在一个分区
a = sc.parallelize([("a",1),("a",1),("a",2),("c",3)])
c = a.repartition(2)
print(c.glom().collect())
[[('a', 1), ('a', 2), ('c', 3)], [('a', 1)]]
partitionBy
#partitionBy按key进行shuffle,相同key一定在一个分区
a = sc.parallelize([("a",1),("a",1),("a",2),("c",3)])
c = a.partitionBy(2)
print(c.glom().collect())
mapPartitions
#mapPartitions可以对每个分区分别执行操作
#每次处理分区内的一批数据,适合需要按批处理数据的情况
#例如将数据写入数据库时,可以极大的减少连接次数。
#mapPartitions的输入分区内数据组成的Iterator,其输出也需要是一个Iterator
#以下例子查看每个分区内的数据,相当于用mapPartitions实现了glom的功能。
a = sc.parallelize(range(10),2)
a.mapPartitions(lambda it:iter([list(it)])).collect()
[[0, 1, 2, 3, 4], [5, 6, 7, 8, 9]]
mapPartitionsWithIndex
#mapPartitionsWithIndex可以获取两个参数
#即分区id和每个分区内的数据组成的Iterator
a = sc.parallelize(range(11),2)
def func(pid,it):
s = sum(it)
return(iter([str(pid) + "|" + str(s)]))
[str(pid) + "|" + str]
b = a.mapPartitionsWithIndex(func)
b.collect()
#利用TaskContext可以获取当前每个元素的分区
from pyspark.taskcontext import TaskContext
a = sc.parallelize(range(5),3)
c = a.map(lambda x:(TaskContext.get().partitionId(),x))
c.collect()
[(0, 0), (1, 1), (1, 2), (2, 3), (2, 4)]
foreachPartitions
#foreachPartition对每个分区分别执行操作
#范例:求每个分区内最大值的和
total = sc.accumulator(0.0)
a = sc.parallelize(range(1,101),3)
def func(it):
total.add(max(it))
a.foreachPartition(func)
total.value
199.0
aggregate
#aggregate是一个Action操作
#aggregate比较复杂,先对每个分区执行一个函数,再对每个分区结果执行一个合并函数。
#例子:求元素之和以及元素个数
#三个参数,第一个参数为初始值,第二个为分区执行函数,第三个为结果合并执行函数。
rdd = sc.parallelize(range(1,21),3)
def inner_func(t,x):
return((t[0]+x,t[1]+1))
def outer_func(p,q):
return((p[0]+q[0],p[1]+q[1]))
rdd.aggregate((0,0),inner_func,outer_func)
(210, 20)
aggregateByKey
#aggregateByKey的操作和aggregate类似,但是会对每个key分别进行操作
#第一个参数为初始值,第二个参数为分区内归并函数,第三个参数为分区间归并函数
a = sc.parallelize([("a",1),("b",1),("c",2),
("a",2),("b",3)],3)
b = a.aggregateByKey(0,lambda x,y:max(x,y),
lambda x,y:max(x,y))
b.collect()
[('b', 3), ('a', 2), ('c', 2)]
公众号后台回复关键字:pyspark,获取本项目github地址。
如果觉得这道RDD大餐味道还不错的话, 欢迎点个再看,分享给你的朋友们哟。??