
干货 | 大规模数据调参就用这个包

文章介绍了一种快速的参数选择方案 -- Successive Halving,在我们之前的实验中,该方法速度又快而且效果也可以接受。
Successive Halving
Successive Halving(SH)就像候选参数组合之间的竞赛。SH是一个迭代选择过程,
在第一次迭代中,用少量资源评估所有候选(参数组合)。 在下一次迭代中选择其中的一些候选项,分配更多的资源给予这些候选。
在对于参数调整,资源通常是训练样本的数量,但也可以是任意的数值参数,例如随机森林中的n_estimators。
案例
如下图所示:
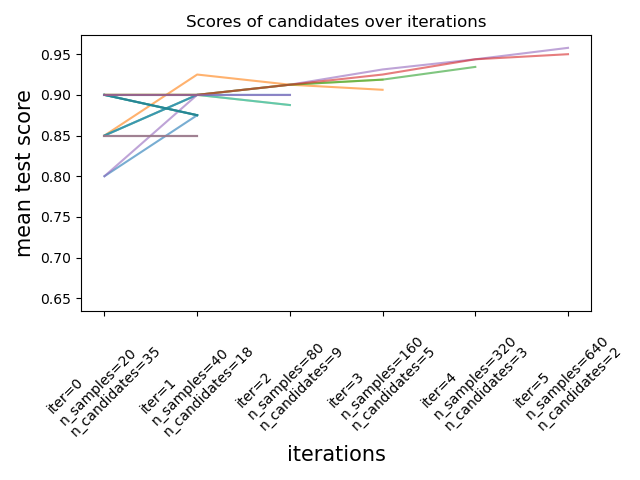
此处我们的资源是样本的个数,每次迭代都会为每个候选分配越来越多的资源。其步骤为:
在第一轮,我们有35个候选参数,我们使用20个样本进行训练;然后从35个候选参数中挑选出18个样本进入第二轮; 在第二轮,我们有18个候选参数,我们使用40个样本进行训练;然后从18个候选参数中挑选出9个样本进入第三轮; 依此类推,直到候选参数的个数达到我们的设定则停止。
1. 数据集生成
from sklearn.experimental import enable_halving_search_cv
from sklearn.model_selection import HalvingGridSearchCV
from sklearn.model_selection import HalvingRandomSearchCV
from sklearn.datasets import make_classification
from sklearn.ensemble import RandomForestClassifier
import pandas as pd
X, y = make_classification(n_samples=1000, random_state=0)
2. HalvingGridSearchCV
param_grid = {'max_depth': [3,5,7,10],
'min_samples_leaf': [2,5,7,10]}
base_estimator = RandomForestClassifier(random_state=0)
sh = HalvingGridSearchCV(base_estimator, param_grid, cv=5,
factor=2, resource='n_estimators',
min_resources =10, max_resources=3000).fit(X, y)
输出模型的最好结参数
# 输出模型的最好的参数
sh.best_estimator_
RandomForestClassifier(max_depth=7, min_samples_leaf=7, n_estimators=160,
random_state=0)
模型的交叉结果
sh.cv_results_
{'iter': array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1,
1, 1, 2, 2, 2, 2, 3, 3, 4]),
'n_resources': array([ 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10,
10, 10, 10, 20, 20, 20, 20, 20, 20, 20, 20, 40, 40,
40, 40, 80, 80, 160]),
'mean_fit_time': array([0.01928229, 0.01584716, 0.015414 , 0.01495667, 0.01724477,
0.01833501, 0.01802239, 0.0175746 , 0.01825719, 0.01801496,
0.01770639, 0.01858926, 0.01929336, 0.01819983, 0.01763158,
0.01695471, 0.03814454, 0.03725901, 0.03484864, 0.03506536,
0.03535094, 0.03335671, 0.03274951, 0.03632708, 0.06523113,
0.0686976 , 0.06733208, 0.06619411, 0.13683538, 0.13806734,
0.27292347]),
......
'mean_score_time': array([0.00161152, 0.0014842 , 0.00139074, 0.00130529, 0.00133247,
0.00145178, 0.00153761, 0.00143166, 0.00140243, 0.00151205,
0.00139952, 0.00150151, 0.0014555 , 0.00144758, 0.0014502 ,
0.00136704, 0.00250249, 0.00238037, 0.00228252, 0.00222058,
0.00220017, 0.00222421, 0.00221481, 0.00224967, 0.00379901,
0.00384221, 0.00396533, 0.00388794, 0.00718961, 0.00746694,
0.01394658]),
......Successive Halving适用于目前所有模型的参数的调节,关于此处我个人有一些小小的建议:
当数据量不大的时候,考虑直接将resource设置为n_estimators; 当数据量很大的时候,考虑将resource设置为n_samples,但min_resources不建议太小; 当数据量很大的时候,先对数据进行采样(不建议采样量太小),然后将resource设置为n_estimators;
最后我们固定住其它参数再寻找最优的n_estimators值,效果会更好些。
Tuning the hyper-parameters of an estimator Non-stochastic Best Arm Identification and Hyperparameter Optimization sklearn.model_selection.HalvingGridSearchCV search_successive_halving代码
✄------------------------------------------------
双一流大学研究生团队创建,一个专注于目标检测与深度学习的组织,希望可以将分享变成一种习惯。
整理不易,点赞三连!
评论