
Sparse RCNN再升级 | ResNet50在不需要NMS和二分匹配的情况下达到48.1AP


最近的端到端多目标检测器通过去除手工制作的过程来简化推理流程,例如使用非最大抑制 (NMS) 去除重复的边界框。然而,在训练中,它们需要二分匹配来计算检测器输出的损失。与端到端方法的方向性相反,二分匹配使得端到端检测器的训练变得复杂。
在本文中旨在提出一种无需二分匹配即可训练端到端多目标检测器的方法。为此,将端到端多目标检测视为使用混合模型的密度估计。提出了新的检测器,称为稀疏混合密度目标检测器(
Sparse MDOD),使用混合模型估计边界框的分布。
Sparse MDOD通过最小化负对数似然和最大分量最大化损失来训练检测器,该损失可以避免重复预测。在训练过程中,不需要额外的过程(如二分匹配)直接从网络输出计算损失。此外,Sparse MDOD在MS-COCO上也优于现有目标检测器。
1背景简介
大多数基于深度神经网络的传统多目标检测方法通过密集预测方案中的网络输出来获取各种候选边界框。然后,他们需要使用非最大抑制(NMS)获得表示对象的最终边界框,并删除候选对象中的重复项(图1左侧)。因此,这些检测器的性能高度依赖于使用NMS的后处理步骤。

同时,一些工作侧重于减少多目标检测的手工设计组件。在这一研究方向中,Sparse RCNN、DETR等提出了端到端的多目标检测方法,可以直接预测一组边界框,而不依赖于NMS。这些端到端方法通过在推理时消除重复边界框(NMS)的删除步骤来缩减推理管道。
最近的端到端检测方法通过在网络输出(候选边界框)和GT之间通过二分匹配搜索唯一匹配来解决训练阶段的重复边界框问题(图1的中心),有效地移除了推理管道中重复边界框移除的步骤。在端到端方法中,检测性能不再依赖于使用NMS进行的后处理。
然而,与他们缩小推理管道的意图相反,他们在训练管道上没有做出足够的工作,并且仍然严重依赖二分匹配,这也是另一个可能阻碍整体训练的手工设计的组件。
图1说明了传统的基于NMS(左)和基于二分匹配的端到端(中心)检测器的训练和推理管道。在后一种情况下,检测器输出的N个GT边界框和K个候选边界框之间可能存在最多个可能的二分匹配。大多数以前的端到端方法都使用匈牙利方法来找到最佳的二分匹配。与GT匹配的检测器输出被分类为前景对象,并被训练为具有高置信度分数。
尽管端到端方法已经成功地消除了重复的边界框,但它们在训练期间仍然使用二分匹配,这使得学习变得复杂。除其他外,它对二分匹配的要求与端到端检测器的核心理念不符,即减少手工制作的组件并简化整个管道。
本文的目标是通过去除二分匹配步骤(图1右侧)来简化端到端多目标检测的训练流程。为此,提出了一种新颖的端到端多目标检测网络,称为稀疏混合密度目标检测器(Sparse MDOD)。
Sparse MDOD受混合密度目标检测器(MDOD)的启发,使用混合模型将边界框信息预测为统计分布的一种形式。混合模型由柯西分布和分类分布组成。这里,柯西分布和分类分布分别表示框坐标和类别概率。采用Sparse R-CNN作为Sparse MDOD的基线架构。此外,提出了最大分量最大化(MCM)损失,即基于混合模型的密度估计的正则化项,将Sparse MDOD训练为无需二分匹配的端到端多目标检测器。
本文的工作通过几个方面对以前的端到端方法进行了改进。在训练阶段Sparse MDOD通过只计算目标函数而不依赖二分匹配来训练。这与端到端检测方法的理念是一致的,即避免复杂的管道。Sparse MDOD可以以更简单的方式替代以前基于二分匹配的端到端多对象检测方法。此外,在代表性的多目标检测数据集MS-COCO上评估了Sparse MDOD,它优于基线Sparse R-CNN以及其他多目标检测器。Sparse MDOD在不使用二分匹配的情况下实现了SOTA检测性能。
2Sparse Mixture Density Object Detector
2.1 Mixture model
对于图像X上的多个GT ,每个GT 包含对象位置的坐标(左、上、右、下)和一个one-hot类信息。本文提出的Sparse MDOD有条件地使用混合模型估计了图像X的g的分布。
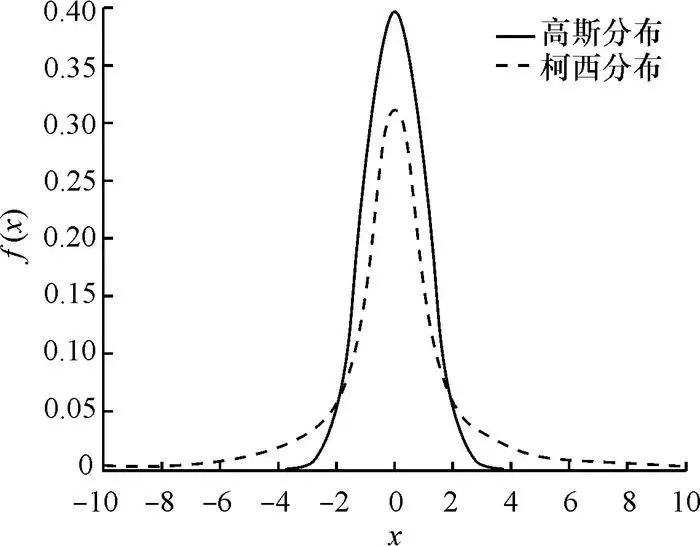
遵循了MDOD中使用的混合模型的设计,混合模型由2种类型的概率分布组成:柯西(连续)分布和分类(离散)分布。
柯西分布是一个连续的概率分布,其形状类似的高斯分布。然而,它的尾部比高斯分布更重,并且由于浮点精度,它不太可能产生下流问题。这里使用4维柯西来表示物体的位置坐标的分布。
此外,分类分布被用来估计对象的类表示的类概率。
混合模型的概率密度函数定义如下:
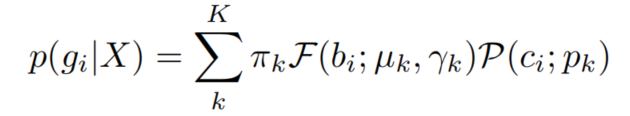
这里,k是K个混合组分的指标,相应的混合系数用表示。F和P分别表示柯西分布的概率密度函数和分类分布的概率质量函数。
和是柯西分布的参数。是分类分布的类概率。这里,C是目标的可能类别数,不包括背景类别。
为了避免使混合模型过于复杂,假设中的每个元素都独立于其他元素。因此,对柯西的概率密度函数进行分解如下:
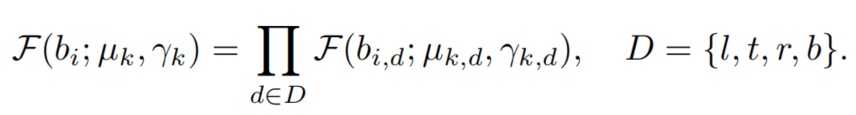
在这里,d是边界框坐标d的集合中的一个元素。
2.2 Sparse MDOD架构
对于Sparse MDOD,采用了Sparse R-CNN的整体架构及其网络特性,例如可学习的建议框、动态头部和多阶段结构。
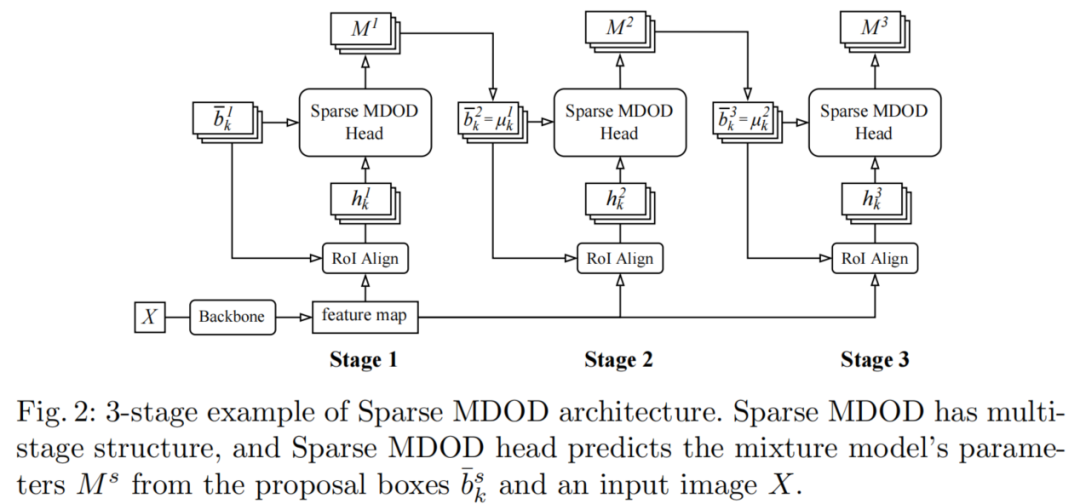
图2显示了使用3阶段结构时的Sparse MDOD网络。首先,Backbone网络从输入图像 X 输出特征图。在第1阶段,通过RoI align预定义的可学习建议框和特征图可以得到RoI特征。
然后,Sparse MDOD head从预测,混合模型的参数和前景概率。这里,混合分量K的数量等于提议框的数量。在第s阶段(s≥2),重复从RoI align到Sparse MDOD head的过程。是前一阶段的预测位置参数,用作当前阶段的建议框。在Sparse R-CNN之后使用6阶段结构。Sparse MDOD head的细节如图3所示。
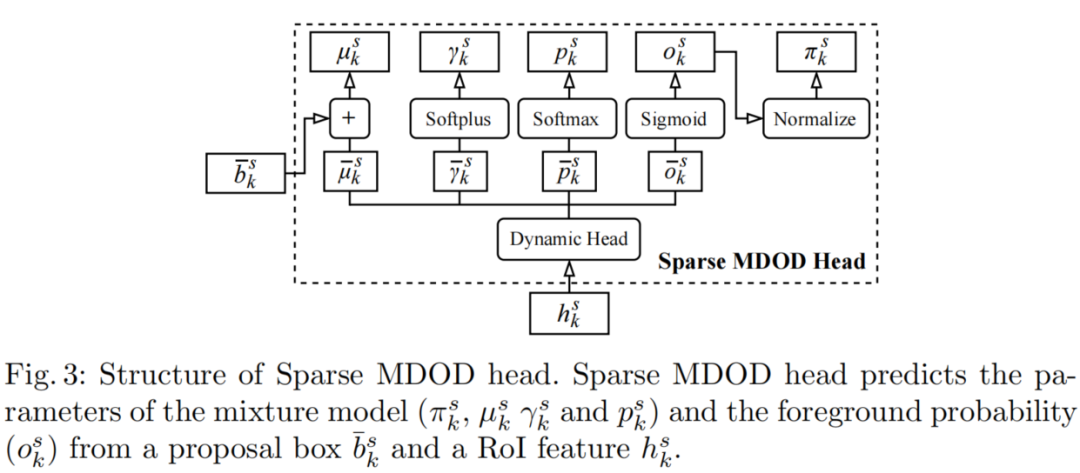
Dynamic head从输出和。位置参数表示一个混合组件的坐标,它是通过在中添加产生的。正尺度参数是通过应用Softmax得到的,Softmax可以将转换为一个正值。沿类维度应用softmax函数计算目标类概率。
请注意,它是否是一个对象的概率不是通过来计算的,而是使用提出的另一种学习前景概率的方法来计算的。在混合模型中,混合组件的概率表示为混合系数。换句话说,可能属于前景区域的混合成分具有较高的值。在这方面,假设π可以看作是比例前景概率,这样等于1。根据这个假设,建议用前景概率o来表示混合系数。如图3所示,Softmax激活从输出。然后,通过将归一化为来计算。
2.3 推理
在推理中,最后阶段的用作预测边界框的坐标。Sparse MDOD的类概率是的输出,只是没有背景概率的对象类的概率。因此,不直接使用p作为预测的置信度分数。相反,通过混合系数 π学习到的前景概率o与p一起使用。
输出预测的置信度分数计算如下:
与其他端到端多目标检测器的方式相同,Sparse MDOD也可以在没有任何后处理(如NMS)过程的情况下获得最终预测。
2.4 训练
Sparse MDOD被训练以通过混合模型最大化输入图像X的g似然性。损失函数被简单地定义为概率密度函数的负对数似然(NLL)如下:
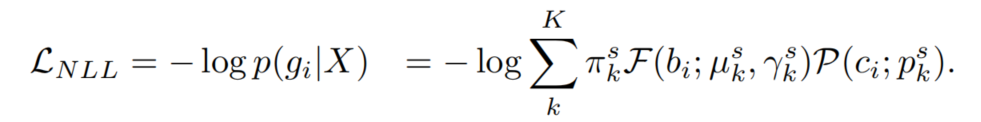
Sparse MDOD通过最小化NLL损失()来学习边界框的坐标和目标类的概率为µ和p。前景概率o并不直接用于计算NLL损失,而是通过表示混合成分概率的π进行训练(见图3)。
在这里,需要考虑NLL损失并不限制单一GT的多个混合分量之间的分布冗余。这个问题可能导致预测的边界框的重复,以及一个物体的概率分散到几个混合成分。因此,引入了最大分量最大化(MCM)损失,这是混合模型的密度估计的正则化项:
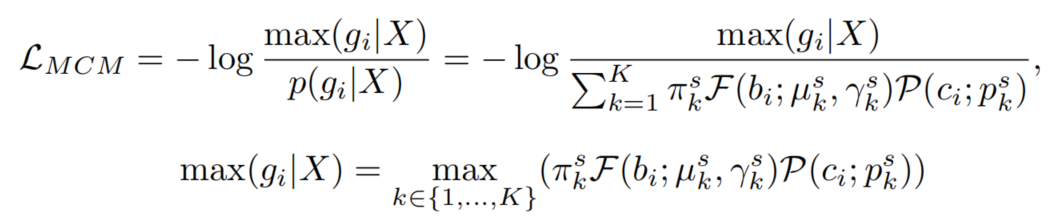
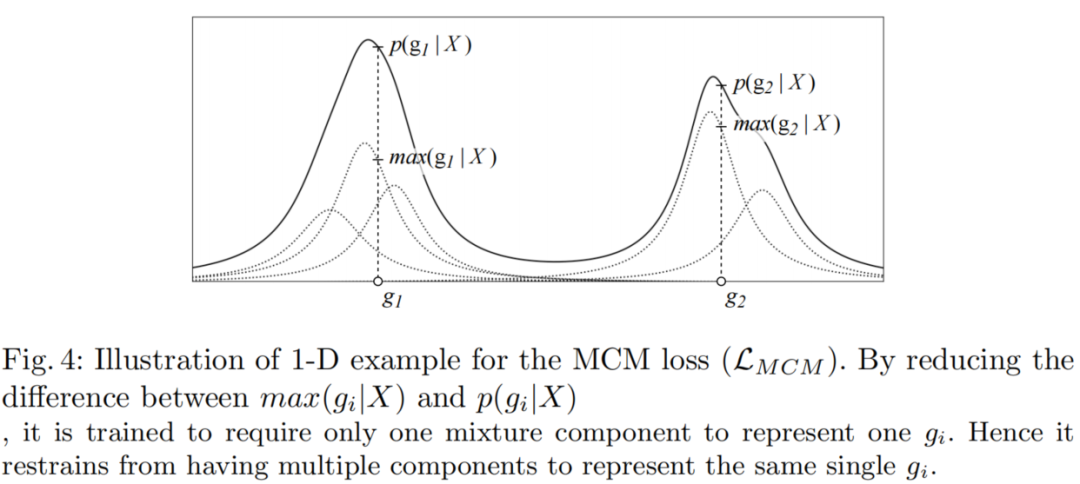
图4显示了MCM损失()的一维示例。最小化MCM损失会减小和之间的似然差异。通过这一点,混合模型被训练为最大化只有一个混合分量对于一个GT的概率,同时降低其他相邻分量的概率。因此总损失函数定义如下:
其中 β 用于调整NLL和MCM损失之间的平衡。为Sparse MDOD的所有阶段计算总损失(L),然后将它们相加并反向传播。计算总损失不需要任何额外的过程,例如二分匹配。
3实验
有无NMS的结果
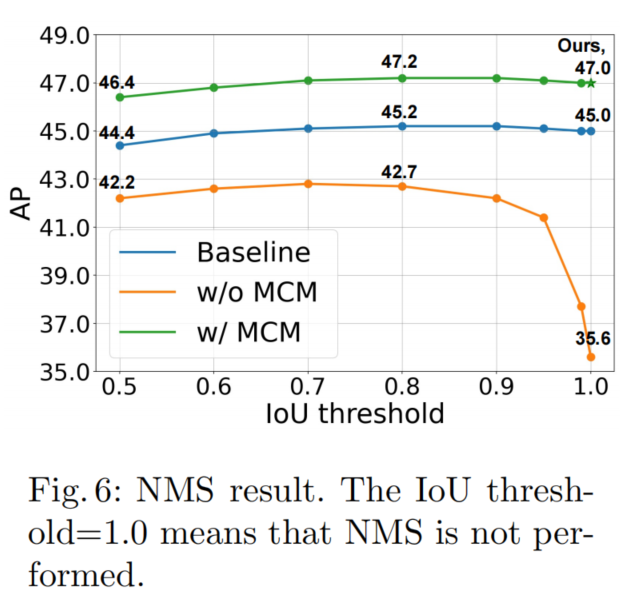
可以看到,使用本文的方法,有没有NMS影响微乎其微。
与Sparse RCNN对比
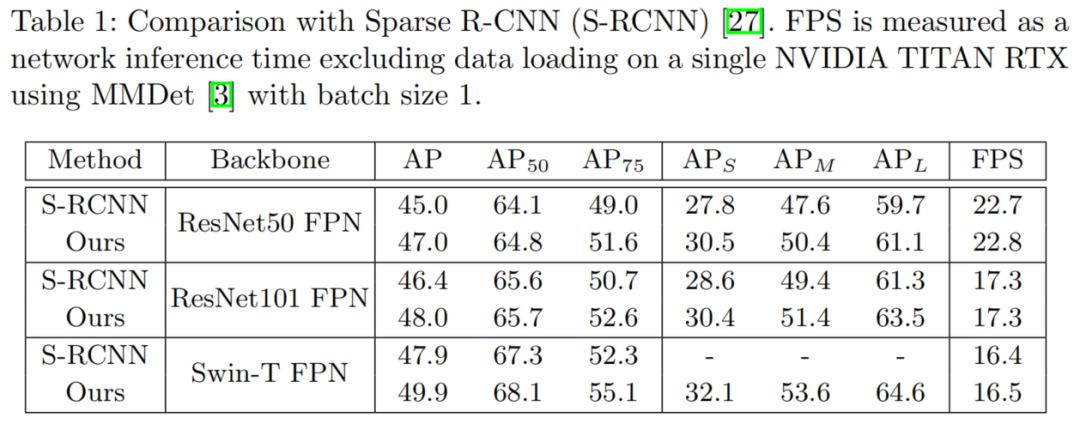
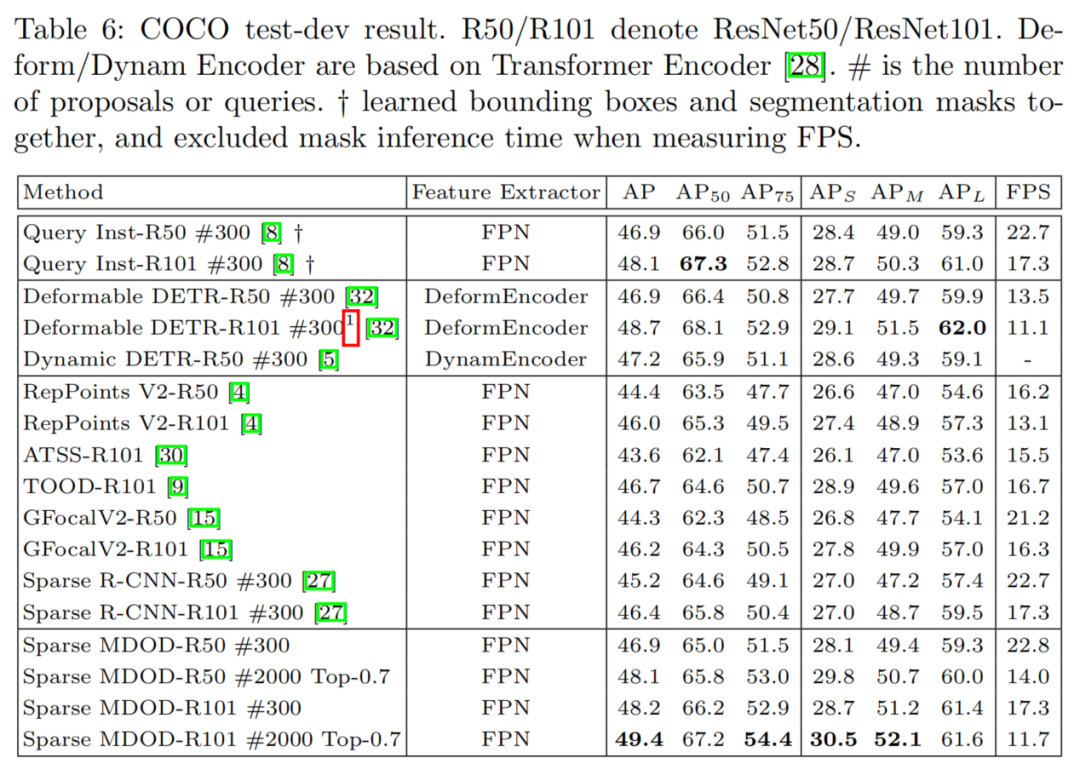
SOTA结果
可视化结果

4参考
[1].Sparse MDOD:Training End-to-End Multi-Object Detector without Bipartite Matching
5推荐阅读
分割冠军 | 超越Swin v2、PvT v2等模型,ViT-Adaptiver实现ADE20K冠军60.5mIoU
DAFormer | 使用Transformer进行语义分割无监督域自适应的开篇之作
ResNet50 文艺复兴 | ViT 原作者让 ResNet50 精度达到82.8%,完美起飞!!!
长按扫描下方二维码添加小助手。
可以一起讨论遇到的问题
声明:转载请说明出处
扫描下方二维码关注【集智书童】公众号,获取更多实践项目源码和论文解读,非常期待你我的相遇,让我们以梦为马,砥砺前行!
