
Sparse R-CNN升级版 | Dynamic Sparse R-CNN使用ResNet50也能达到47.2AP

Sparse R-CNN是最近的一种强目标检测Baseline,通过对稀疏的、可学习的proposal boxes和proposal features进行集合预测。在这项工作中提出了2个动态设计来改进Sparse R-CNN。首先,
Sparse R-CNN采用一对一标签分配方案,其中匈牙利算法对每个Ground truth只匹配一个正样本。这种一对一标签分配对于学习到的proposal boxes和Ground truth之间的匹配可能不是最佳的。为了解决这一问题,作者提出了基于最优传输算法的动态标签分配(DLA),在Sparse R-CNN的迭代训练阶段分配递增的正样本。随着后续阶段产生精度更高的精细化proposal boxes,在后续阶段对匹配进行约束,使其逐渐松散。其次,在
Sparse R-CNN的推理过程中,对于不同的图像,学习到的proposal boxes和proposal features保持固定。在动态卷积的驱动下提出了Dynamic Proposal Generation(DPG)来动态组合多个Proposal Experts,为连续的训练阶段提供更好的初始proposal boxes和proposal features。因此,DPG可以导出与样本相关的proposal boxes和proposal features来进行判断。实验表明,
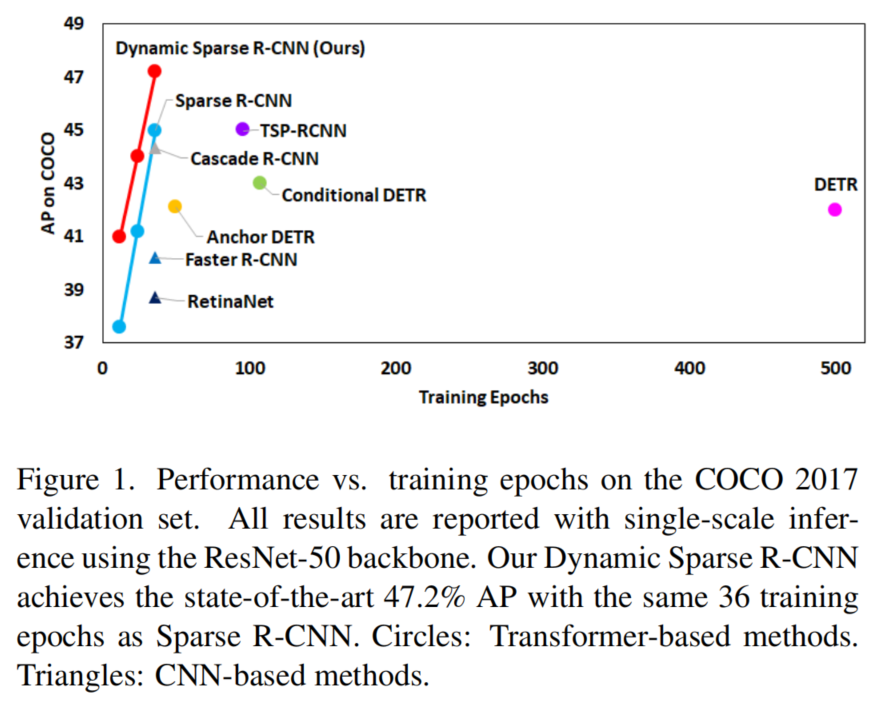
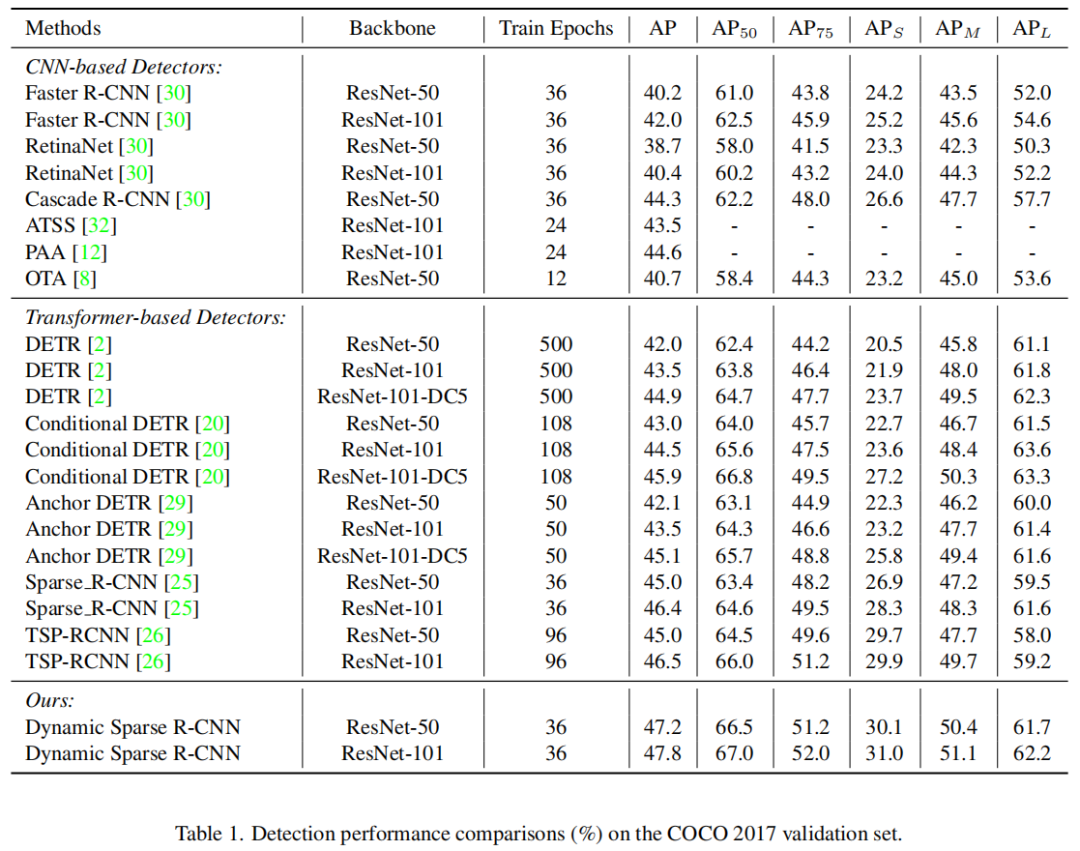
Dynamic Sparse R-CNN可以增强具有不同Backbone的强Sparse R-CNNBaseline。特别是,Dynamic Sparse R-CNN在COCO 2017验证集上达到了最先进的47.2% AP,在相同的ResNet-50Baseline下比Sparse R-CNN高出2.2% AP。
1简介
近年来,目标检测得到了快速的发展,从卷积神经网络(CNN)到Transformer,特征提取的Backbone各不相同,检测Pipeline的设计也各不相同。根据回归次数的不同,检测器主要可分为One-Stage、Two-Stage和Multi-Stage。
One-Stage检测器直接预测给定图像中的回归目标和类别,而不需要进行细化步骤。Two-Stage检测器首先生成有限数量的前景候选proposal(例如,区域建议网络(RPN)),然后将proposal传递到检测网络以细化位置和类别。Multi-Stage检测器可以多次细化位置和类别,从而提高性能,但通常需要大量的计算开销。
One-Stage检测方法一般可分为Anchor-Base检测器和Anchor-Free检测器。Anchor-Base检测器在图像中设计密集的预定义Anchor,然后直接预测类别并细化Anchor的坐标。然而,手动Anchor配置可能不是最终性能的最佳选择。为了克服这一问题,提出了Anchor-Free检测器。Anchor-Free检测器通常使用中心点或区域内的Ground truth来定义正样本的proposal和预测偏移,以获得最终的边界框。
最近,基于Transformer的检测器被提出,通过使用Transformer编码器和解码器架构将目标检测定义为一个集合预测问题。这些方法用少量可学习的目标查询代替Anchor机制,可以对目标和全局图像上下文之间的关系建模,输出最终的预测结果。匈牙利算法是一种基于分类和回归的组合损失,用于寻找Ground truth和预测之间的匹配。但是这些检测器中的标签分配是一对一的方式,在训练期间只有一个单一的检测器匹配一个Ground truth。
现有的基于CNN的方法,使用多对一的标签分配方案,假设分配多个阳性的Ground truth可以更有效地优化proposal,可以促进检测器得到更好的性能。
因此,针对Sparse R-CNN的强Baseline,提出了基于最优传输算法的多对一的动态标签分配(DLA)。在Sparse R-CNN的迭代阶段,也采用了逐渐增加的正样本分配给GTs。由于每个阶段都会为下一个阶段产生精细化的proposal boxes和proposal features,作者希望限制Ground truth和预测框之间的匹配,在前期阶段更严格,在后期阶段更宽松,因为在后续阶段的预测精度越来越高。
此外,在Sparse R-CNN中,目标查询(即proposal boxes和proposal features)在训练过程中是可学习的,但在推理过程中对不同的图像保持固定。在动态卷积的驱动下提出了动态proposal生成(DPG),以在第一个迭代阶段提供更好的初始proposal boxes和proposal features。与固定proposal相比,DPG可以聚合多个与样本相关的并行Proposal Experts,输出动态proposal进行推理。作者将该方法命名为Dynamic Sparse R-CNN,Dynamic Sparse R-CNN在COCO 2017验证集上达到了最先进的47.2% AP,在相同的ResNet-50 Backbone下相对Sparse R-CNN提升了2.2% AP。
主要贡献:
指出在基于 Transformer的检测中,多对一标签分配比一对一标签分配更合理有效。将最优输运分配方法应用到Sparse R-CNN中,并在迭代阶段将逐渐增加的正样本分配给GTs。设计了一个动态 proposal生成机制来学习多个Proposal Experts,并将他们组合起来生成动态proposal和特征进行推理。将这两种动态设计集成到 Sparse R-CNN中,得到的Dynamic Sparse R-CNN检测器,获得了2.2%的AP增益,使用ResNet-50 Backbone在COCO验证集上达到了最先进的47.2% AP。
2相关工作
2.1 General Object Detection
基于CNN的检测器由于各种特征提取Backbone和Pipeline设计的发展而取得了很大的进展。
One-Stage检测器可以直接预测给定图像中物体的位置和相关类别,而不需要区域建议和细化组件,包括Anchor-Base检测器和Anchor-Free检测器。
Two-Stage检测器首先用区域建议网络(RPN)生成固定数量的前景proposal,然后将proposal传递给检测网络,以细化目标的位置和类别。
最近,基于Transformer的检测器利用Transformer编码器和解码器的体系结构,将目标检测重新表述为一个集合预测问题。他们设计了少量的可学习的目标查询来建模目标和全局图像上下文之间的关系,并得到了很好的性能。解码器中的目标查询是DETR的必需组件。条件DETR提出了一种快速训练收敛的条件空间查询方法。AnchorDETR提出了一种基于Anchor的查询设计,并以较少的训练时间实现了接近于DETR的性能。Sparse R-CNN提出R-CNN中可学习的建议框和建议特征,并将特征图上提取的RoI特征和相关的建议特征传递到迭代结构(即动态头)进行预测。
2.2 Label Assignment
标签分配在目标检测器中占有重要地位。Anchor检测器通常采用一定阈值的IoU作为赋值标准。例如,RetinaNet将IoU得分高于0.5的Anchor定义为正样本,其他定义为负样本。YOLO只采用与Ground truth相关联的最大IoU得分的Anchor作为正样本,这种标签分配是一种一对一匹配的方法。
Anchor-Free检测器将Ground truth中心点或缩小的中心区域定义为正的,将其他区域定义为负的。ATSS表明,Anchor-base检测器与菲Anchor-base检测器的本质区别在于标签分配,于是提出了一种自适应训练样本选择方法,根据目标的统计特征划分正样本和负样本。PAA提出了一种基于正、负样本联合损失分布为高斯分布的概率Anchor分配方法。OTA通过定义Ground truth和background为供应者,定义Anchor为需求者,将标签分配定义为一个最优运输问题,然后利用Sinkhorn-Knopp迭代对问题进行高效优化。
基于Transformer的检测器将目标检测视为集合预测问题,并将Ground truth和目标查询之间的标签分配视为双边匹配。匈牙利算法通过最小化全局损失来优化Ground truth与目标查询之间的一对一匹配。在本文中,假设了基于Transformer的检测器中一对一的标签分配是次优的,并探索了一种基于OTA的Sparse R-CNN的多对一匹配的动态标签分配。
2.3 Dynamic Convolution
动态卷积是一种动态结合多个卷积核与可学习的样本相关权值的技术,以增强模型表示能力的技术。Softmax中的Temperature annealing有助于提高训练效率和最终性能。CondConv提出了有条件的参数化卷积,它为每个输入图像学习专门的卷积核。它将多个卷积核与子网生成的权值相结合,构造了一个图像指定的卷积核。DyNet设计了几种基于动态卷积的动态卷积神经网络,包括Dy-MobileNet、Dy-ShuffleNet和Dy-ResNet网络等。
在本工作中,分析了Sparse R-CNN中对推理过程中不同输入的固定建议框和特征是次优的和不灵活的。基于动态卷积,通过在推理过程中生成动态样本相关的建议来改进Sparse R-CNN。
3Dynamic Sparse R-CNN
3.1 回顾Sparse R-CNN
Sparse R-CNN是一个比较强的目标检测Baseline,通过对稀疏可学习目标建议进行预测,然后再使用一个迭代结构(即dynamic head)来逐步完善预测。每个迭代阶段的输入由3个部分组成:
Backbone提取的FPN特征 Proposal Boxes和Proposal Features输出包括预测的box、相应的类以及目标特征
将一个阶段输出的预测框和目标特征分别用作下一阶段的改进Proposal Boxes和Proposal Features。Proposal Boxes是一组固定的区域建议(Np×4),指定目标的潜在位置。Proposal Features是潜在向量(Np×C),以编码实例特征(例如,姿态和形状)。
在Sparse R-CNN中,Proposal Boxes在训练期间学习并固定用于推理。Proposal Boxes应用基于Set的损失对预测和Ground truth进行双边匹配,与匈牙利算法的一对一匹配。图2(a)说明了Sparse R-CNN的设计。
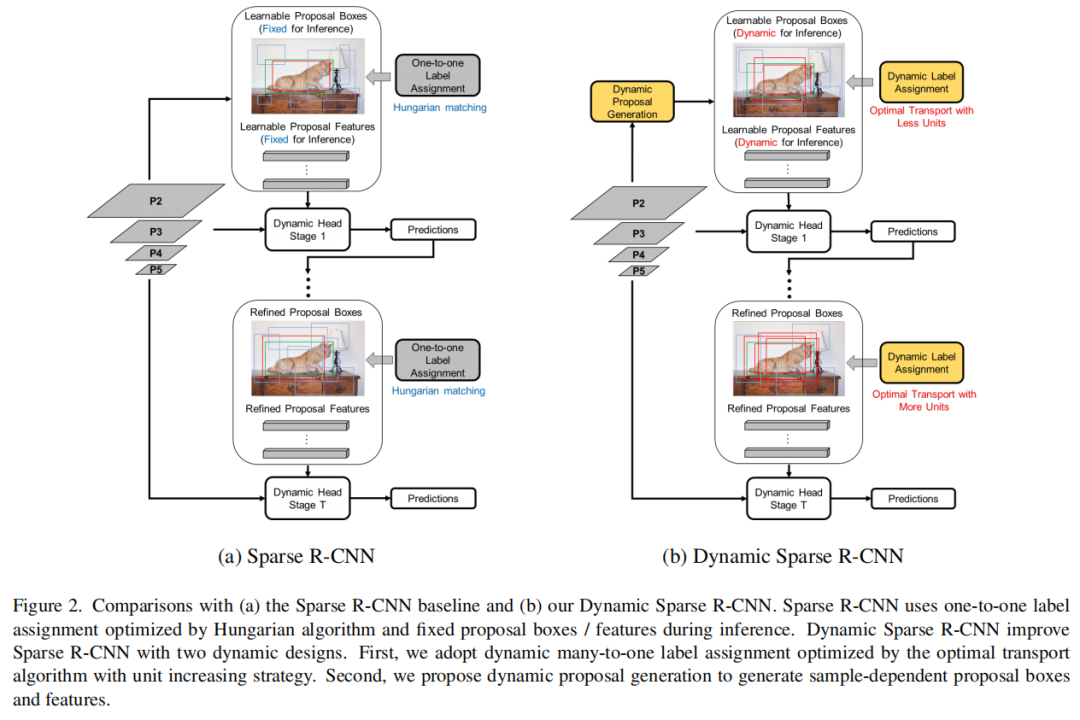
作者分析了Sparse R-CNN的2个主要局限性:
首先,
Sparse R-CNN采用检测预测与Ground truth一对一匹配的方法,这种方法容易出现次优,训练效率低。其次,
Ground truth中学习到的Proposal Boxes和Proposal Features代表了训练集的统计量,它们对特定的测试图像不具有自适应性。
在本文的工作中,设计了2个方案来改进Sparse R-CNN。分别是:
Dynamic Label Assignment Dynamic Proposal Generation
3.2 Dynamic Label Assignment
在Sparse R-CNN中,使用匈牙利算法进行一对一匹配,即每个Ground truth与一个预测框匹配。假设这种一对一匹配可能不是最优的。给Ground truth分配多个预测框可以更有效地优化Proposal,促进检测器的训练。
为了实现多对一匹配,遵循基于CNN的方法,并将最优传输分配(OTA)应用于Transformer。具体来说,OTA是一个探索如何将检测框与Ground truth相匹配的公式。该公式将Ground truth作为供应者提供分配配额,将检测框作为需求方寻求分配。背景类也被定义为提供默认赋值的供应者。
数学上,假设在一幅图像中有m个Ground truth,每个Ground truth都提供了的赋值,这些赋值称为units。n个检测框中的每一个尝试得到一个units,成功的匹配称为positive assignment。背景提供了 units来满足没有分配任何Ground truth的检测框,这称为negative assignments。优化目标可定义为:
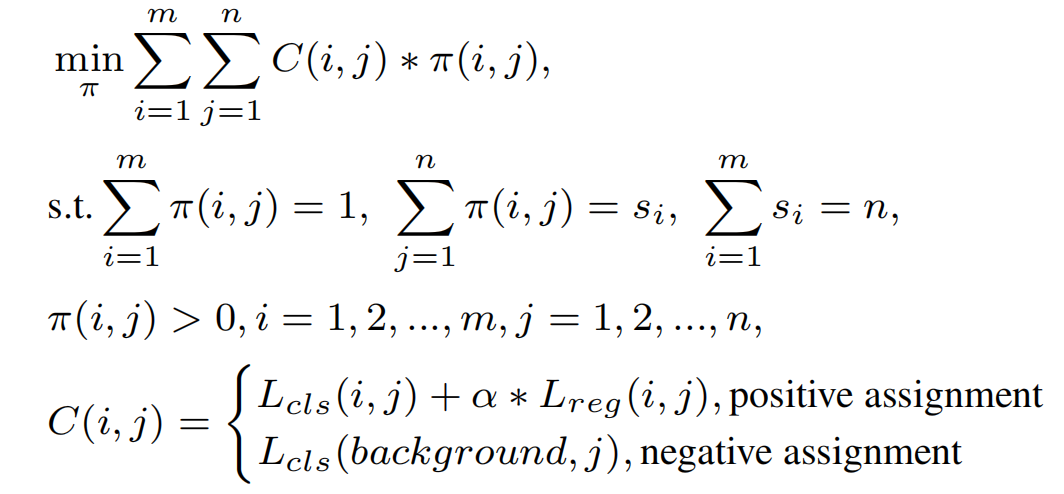
其中,i是Ground truth的指数,j是检测框的指数(j=1,…n),α是一个平衡分类和回归损失的系数。每个positive assignment的代价是分类损失和回归损失的总和,而每个negative assignments的代价只是分类损失。表示Ground truth i和检测框 j之间需要优化的匹配结果。
每个供应者提供的units数量k可以是固定的或动态的。根据OTA中的动态k估计方法,本文的工作基于预测和Ground truth之间的IoU动态估计k值。在该策略中,选择每个Ground truth的Top-q IoU值,并将其求和作为k值的估计。
基于标签分配的最优传输理论(),每个Proposal(即需求方)只需要Ground truth(即供应方)提供的一个units标签单元。
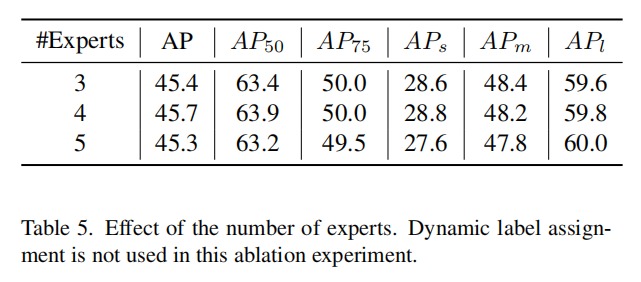
因此,一个 简单的 在本文中使用默认的迭代阶段数(T=6)。 在 在图3(a), 其中为输出的 作者还构造了一个 最后,将连接的数据插值到一个4C×30×30特征图(每个金字塔层的C=256)中。然后,将4C通道通过求和进行融合,得到的30×30特征图被Flatten到2个FC层。第1个FC的尺寸是900×1500,第2个的尺寸是1500×()。这里作者构建了( 如表3所示,具有固定k值(k=2,3)的 此外,具有q=8和 如表4所示,在Dynamic k Estimation中尝试了q的不同选择,发现q=8效果最好。值得注意的是,表4中的所有结果都优于一对一匹配(45.0%),这验证了动态多对一匹配方案的有效性。 如表5所示尝试了不同数量的Experts,并在该方法中使用4个Experts作为默认值可以得到最好的性能。 图4可视化了通过 [1].Dynamic Sparse R-CNN 推荐阅读 辅助模块加速收敛,精度大幅提升!移动端实时的NanoDet-Plus来了! 机器学习算法工程师 一个用心的公众号Proposal将不会被分配给不同的Ground truth。动态<估计方法一般适用于$kProposal的数量,如果,将为每个Ground truth减少k个相同的比例因子,以确保至少有20%的positive assignment。units增加策略Sparse R-CNN采用了迭代架构,逐步提高预测精度。作者提出了一种简单的units递增策略来促进迭代结构的训练。当前期Dynamic head的预测不够准确时,希望供应方(Ground truth)提供少量的units,这使得匹配更加严格。当后期Dynamic head的预测越来越准确时,逐渐放松约束,让供应方(Ground truth)提供更多的units进行匹配。units增加策略可以定义如下:
3.3 Dynamic Proposal Generation
Sparse R-CNN中,将一组Proposal Boxes和Proposal Features连同从FPN Backbone(到)所提取的特征一起送入Dynamic head。这些Proposal在训练期间是可学习的,但在推断期间是固定的。在动态卷积的驱动下,针对输入图像生成Proposal Boxes和Proposal Features可以提高检测的性能。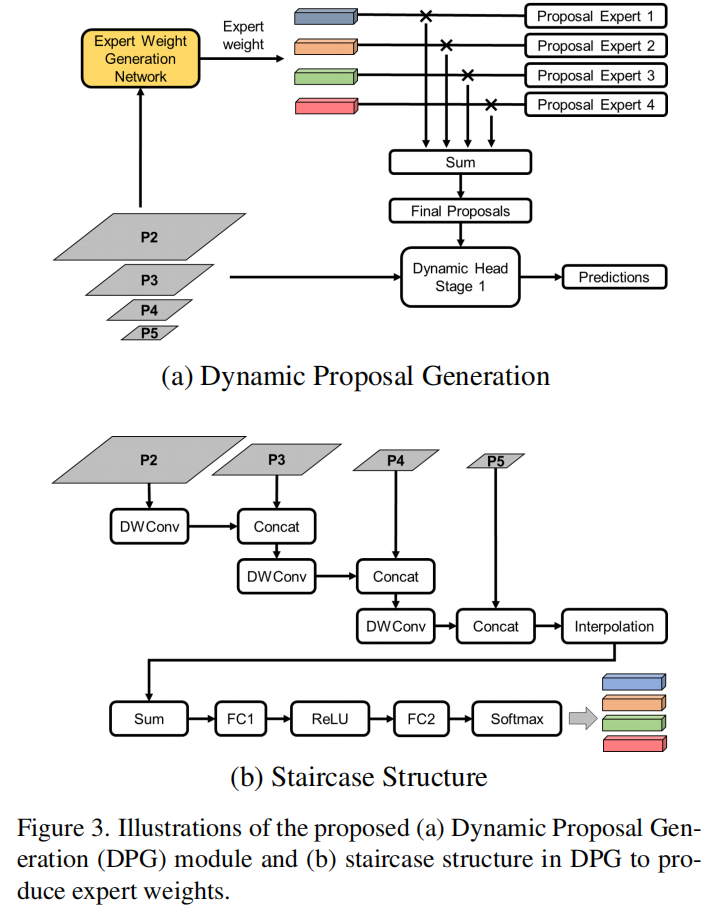
Proposal Boxes和Proposal Features是不同的Proposal Boxes和Proposal Features集的线性组合,每个集合被称为一个Experts。由Experts权重生成网络生成组合Experts的系数(称为expert weight)(图3(b))。DPG模块可以制定如下。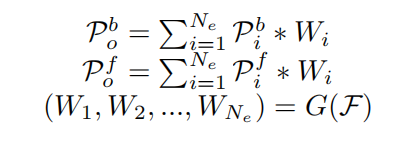
Dynamic Proposal Boxes,为输出的Dynamic Proposal Features,为expert weight生成网络学习到的Proposal expert weight,为从FPN Backbone(到)所提取的特征。Staircase Structure
expert weight生成网络遵循动态卷积结构的基本设计,如图3(b)所示还使用了softmax中的temperature annealing operation (tao)来控制expert weight,使训练过程更加有效。Staircase Structure来聚集来自不同金字塔层的特征。到的特征在尺度上是依次下降的:的宽和高是的1/2。expert数量),(Proposal Boxes和Proposal Features数量)。4实验
4.1 消融实验
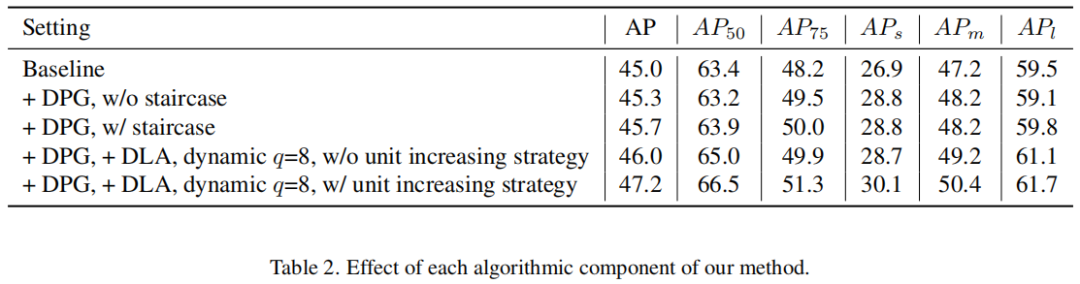
1、不同匹配器的影响
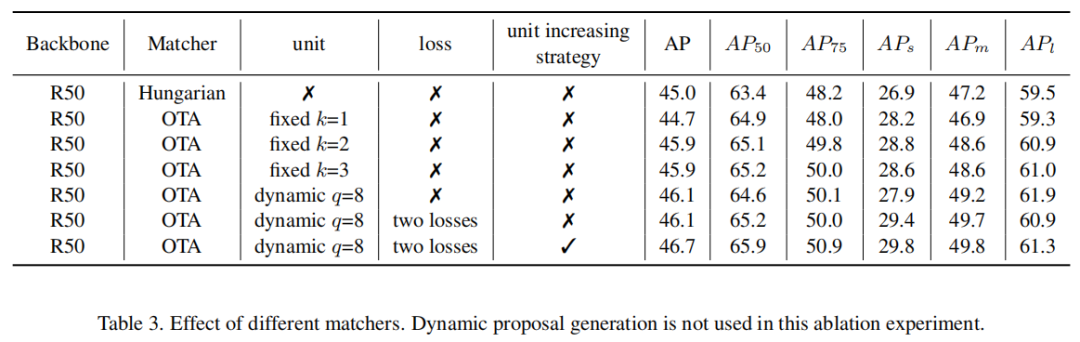
OTA匹配器与Baseline相比,AP的提升率为0.9% AP。在动态k估计中使用q=8的OTA匹配器增加了1.1% AP,这证明了使用动态k的有效性。units增加策略进一步将AP提高到46.7% AP,说明这种简单的设计是有效的。units增加策略的OTA匹配器 AP75和APs都增加了近3个百分点。可见动态多对一匹配方案产生了更多样化的预测框选项,以匹配Ground truth。该方案特别适用于对小物体的检测。2、q的影响
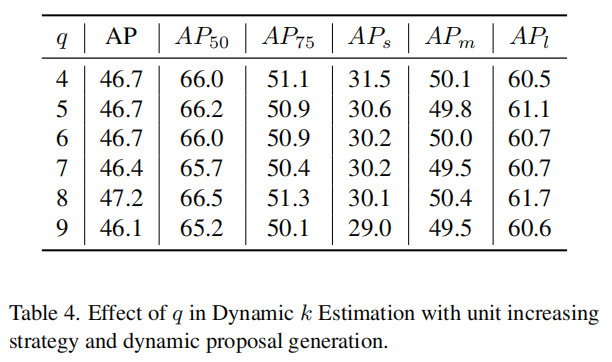
3、Experts数量的影响
4、可视化

Dynamic Sparse R-CNN进行的采样检测结果。Dynamic Sparse R-CNN可以正确地检测不同尺度、外观等的目标。4.2 SOTA对比
5参考
