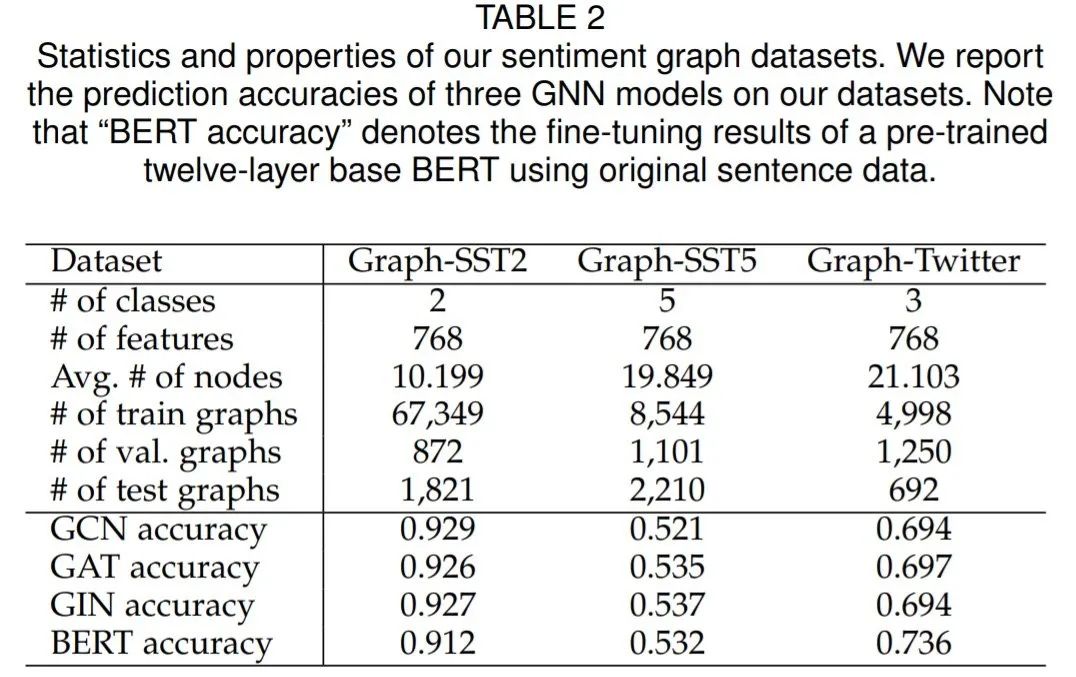
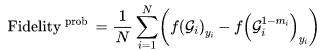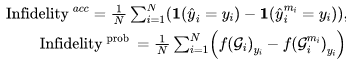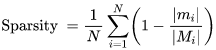[10] K. Simonyan, A. Vedaldi, and A. Zisserman, “Deep inside convolutional networks: Visualising image classification models and saliency maps,” arXiv preprint arXiv:1312.6034, 2013.[11] D. Smilkov, N. Thorat, B. Kim, F. Viegas, and M. Wattenberg, ´ “Smoothgrad: removing noise by adding noise,” arXiv preprint arXiv:1706.03825, 2017.[12] B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, and A. Torralba, “Learning deep features for discriminative localization,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 2921–2929.[13] R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra, “Grad-cam: Visual explanations from deep networks via gradient-based localization,” in 2017 IEEE International Conference on Computer Vision (ICCV). IEEE, 2017, pp. 618–626.[14] P. Dabkowski and Y. Gal, “Real time image saliency for black box classifiers,” in Advances in Neural Information Processing Systems, 2017, pp. 6967–6976.[15] H. Yuan, L. Cai, X. Hu, J. Wang, and S. Ji, “Interpreting image classifiers by generating discrete masks,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020.[17] C. Olah, A. Satyanarayan, I. Johnson, S. Carter, L. Schubert, K. Ye, and A. Mordvintsev, “The building blocks of interpretability,” Distill, 2018, https://distill.pub/2018/building-blocks.[18] F. Yang, S. K. Pentyala, S. Mohseni, M. Du, H. Yuan, R. Linder, E. D. Ragan, S. Ji, and X. Hu, “Xfake: explainable fake news detector with visualizations,” in The World Wide Web Conference, 2019, pp. 3600–3604.[19] M. Du, N. Liu, Q. Song, and X. Hu, “Towards explanation of dnnbased prediction with guided feature inversion,” in Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2018, pp. 1358–1367.[22] H. Yuan, Y. Chen, X. Hu, and S. Ji, “Interpreting deep models for text analysis via optimization and regularization methods,” in AAAI-19: Thirty-Third AAAI Conference on Artificial Intelligence. Association for the Advancement of Artificial Intelligence, 2019.[23] M. Du, N. Liu, and X. Hu, “Techniques for interpretable machine learning,” Communications of the ACM, vol. 63, no. 1, pp. 68–77, 2019.[24] A. Rai, “Explainable ai: From black box to glass box,” Journal of the Academy of Marketing Science, vol. 48, no. 1, pp. 137–141, 2020.[25] F. K. Dosilovi ˇ c, M. Br ´ ciˇ c, and N. Hlupi ´ c, “Explainable artificial ´ intelligence: A survey,” in 2018 41st International convention on information and communication technology, electronics and microelectronics (MIPRO). IEEE, 2018, pp. 0210–0215. [26] C. Molnar, Interpretable Machine Learning, 2019, https:// christophm.github.io/interpretable-ml-book/.[41] H. Yuan, J. Tang, X. Hu, and S. Ji, “XGNN: Towards model-level explanations of graph neural networks,” ser. KDD ’20. New York, NY, USA: Association for Computing Machinery, 2020, p. 430–438. [Online]. Available: https://doi.org/10.1145/3394486.3403085[42] Z. Ying, D. Bourgeois, J. You, M. Zitnik, and J. Leskovec, “Gnnexplainer: Generating explanations for graph neural networks,” in Advances in neural information processing systems, 2019, pp. 9244– 9255.[43] D. Luo, W. Cheng, D. Xu, W. Yu, B. Zong, H. Chen, and X. Zhang, “Parameterized explainer for graph neural network,” in Advances in neural information processing systems, 2020.[44] C. Rudin, “Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead,” Nature Machine Intelligence, vol. 1, no. 5, pp. 206–215, 2019.[45] J. Chen, L. Song, M. J. Wainwright, and M. I. Jordan, “Learning to explain: An information-theoretic perspective on model interpretation,” in International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 80. PMLR, 2018, pp. 882–891.[46] U. Alon, “Network motifs: theory and experimental approaches,” Nature Reviews Genetics, vol. 8, no. 6, pp. 450–461, 2007.[47] R. Milo, S. Shen-Orr, S. Itzkovitz, N. Kashtan, D. Chklovskii, and U. Alon, “Network motifs: simple building blocks of complex networks,” Science, vol. 298, no. 5594, pp. 824–827, 2002.[48] U. Alon, An introduction to systems biology: design principles of biological circuits. CRC press, 2019.[49] F. Baldassarre and H. Azizpour, “Explainability techniques for graph convolutional networks,” in International Conference on Machine Learning (ICML) Workshops, 2019 Workshop on Learning and Reasoning with Graph-Structured Representations, 2019.[50] P. E. Pope, S. Kolouri, M. Rostami, C. E. Martin, and H. Hoffmann, “Explainability methods for graph convolutional neural networks,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 10 772–10 781.[51] Anonymous, “Hard masking for explaining graph neural networks,” in Submitted to International Conference on Learning Representations, 2021, under review. [Online]. Available: https: //openreview.net/forum?id=uDN8pRAdsoC[52] M. S. Schlichtkrull, N. De Cao, and I. Titov, “Interpreting graph neural networks for nlp with differentiable edge masking,” arXiv preprint arXiv:2010.00577, 2020.[53] Anonymous, “Causal screening to interpret graph neural networks,” in Submitted to International Conference on Learning Representations, 2021, under review. [Online]. Available: https: //openreview.net/forum?id=nzKv5vxZfge[54] R. Schwarzenberg, M. Hubner, D. Harbecke, C. Alt, and L. Hennig, ¨ “Layerwise relevance visualization in convolutional text graph classifiers,” arXiv preprint arXiv:1909.10911, 2019.[55] T. Schnake, O. Eberle, J. Lederer, S. Nakajima, K. T. Schutt, K.-R. ¨ Muller, and G. Montavon, “Higher-order explanations of graph ¨ neural networks via relevant walks,” 2020.[56] Q. Huang, M. Yamada, Y. Tian, D. Singh, D. Yin, and Y. Chang, “Graphlime: Local interpretable model explanations for graph neural networks,” arXiv preprint arXiv:2001.06216, 2020.[57] Y. Zhang, D. Defazio, and A. Ramesh, “Relex: A model-agnostic relational model explainer,” arXiv preprint arXiv:2006.00305, 2020.[58] M. N. Vu and M. T. Thai, “Pgm-explainer: Probabilistic graphical model explanations for graph neural networks,” in Advances in neural information processing systems, 2020.[59] A. Shrikumar, P. Greenside, and A. Kundaje, “Learning important features through propagating activation differences,” in International Conference on Machine Learning, 2017, pp. 3145–3153.[60] J. Chen, L. Song, M. Wainwright, and M. Jordan, “Learning to explain: An information-theoretic perspective on model interpretation,” in Proceedings of the 35th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, J. Dy and A. Krause, Eds., vol. 80. Stockholmsmassan, Stockholm ¨ Sweden: PMLR, 10–15 Jul 2018, pp. 883–892. [Online]. Available: http://proceedings.mlr.press/v80/chen18j.html[61] R. S. Sutton, D. McAllester, S. Singh, and Y. Mansour, “Policy gradient methods for reinforcement learning with function approximation,” Advances in neural information processing systems, vol. 12, pp. 1057–1063, 1999.[62] E. Jang, S. Gu, and B. Poole, “Categorical reparameterization with gumbel-softmax,” in International Conference on Learning Representations, 2016.[63] C. Louizos, M. Welling, and D. P. Kingma, “Learning sparse neural networks through l 0 regularization,” arXiv preprint arXiv:1712.01312, 2017.[64] M. T. Ribeiro, S. Singh, and C. Guestrin, “” why should i trust you?” explaining the predictions of any classifier,” in Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining, 2016, pp. 1135–1144.[65] M. Yamada, W. Jitkrittum, L. Sigal, E. P. Xing, and M. Sugiyama, “High-dimensional feature selection by feature-wise kernelized lasso,” Neural computation, vol. 26, no. 1, pp. 185–207, 2014.[66] D. Margaritis and S. Thrun, “Bayesian network induction via local neighborhoods,” Advances in neural information processing systems, vol. 12, pp. 505–511, 1999.[67] S. Bach, A. Binder, G. Montavon, F. Klauschen, K. Muller, and ¨ W. Samek, “On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation,” PLoS ONE, vol. 10, no. 7, p. e0130140, 2015.[68] R. Albert and A.-L. Barabasi, “Statistical mechanics of complex ´ networks,” Reviews of modern physics, vol. 74, no. 1, p. 47, 2002.[69] R. Socher, A. Perelygin, J. Wu, J. Chuang, C. D. Manning, A. Y. Ng, and C. Potts, “Recursive deep models for semantic compositionality over a sentiment treebank,” in Proceedings of the 2013 conference on empirical methods in natural language processing, 2013, pp. 1631–1642.[70] L. Dong, F. Wei, C. Tan, D. Tang, M. Zhou, and K. Xu, “Adaptive recursive neural network for target-dependent twitter sentiment classification,” in Proceedings of the 52nd annual meeting of the association for computational linguistics (volume 2: Short papers), 2014, pp. 49–54.[71] M. Gardner, J. Grus, M. Neumann, O. Tafjord, P. Dasigi, N. Liu, M. Peters, M. Schmitz, and L. Zettlemoyer, “Allennlp: A deep semantic natural language processing platform,” arXiv preprint arXiv:1803.07640, 2018.[72] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pretraining of deep bidirectional transformers for language understanding,” arXiv preprint arXiv:1810.04805, 2018.[73] A. K. Debnath, R. L. Lopez de Compadre, G. Debnath, A. J. Shusterman, and C. Hansch, “Structure-activity relationship of mutagenic aromatic and heteroaromatic nitro compounds. correlation with molecular orbital energies and hydrophobicity,” Journal of medicinal chemistry, vol. 34, no. 2, pp. 786–797, 1991.[74] Z. Wu, B. Ramsundar, E. N. Feinberg, J. Gomes, C. Geniesse, A. S. Pappu, K. Leswing, and V. Pande, “Moleculenet: a benchmark for molecular machine learning,” Chemical science, vol. 9, no. 2, pp. 513–530, 2018.[75] A. Jacovi and Y. Goldberg, “Towards faithfully interpretable nlp systems: How should we define and evaluate faithfulness?” arXiv preprint arXiv:2004.03685, 2020.[76] S. Wiegreffe and Y. Pinter, “Attention is not not explanation,” arXiv preprint arXiv:1908.04626, 2019.[77] S. Hooker, D. Erhan, P.-J. Kindermans, and B. Kim, “A benchmark for interpretability methods in deep neural networks,” in Advances in Neural Information Processing Systems, 2019, pp. 9737–9748.[78] B. Sanchez-Lengeling, J. Wei, B. Lee, E. Reif, P. Wang, W. W. Qian, K. McCloskey, L. Colwell, and A. Wiltschko, “Evaluating attribution for graph neural networks,” Advances in Neural Information Processing Systems, vol. 33, 2020.