
惊呆了!训练7万小时后,OpenAI的模型竟然学会在「我的世界」里刨木头

新智元报道
新智元报道
编辑:好困 拉燕 袁榭
【新智元导读】2022年6月,OpenAI发表论文称用「视频预训练模型」,让AI学会了在「我的世界」里从头开始造石镐。
最近,似乎早已把GPT抛在脑后的OpenAI又整了个新活。
在经过海量无标注视频以及一点点标注过的数据训练之后,AI终于学会了在「我的世界」(Minecraft)里制作钻石镐。
而整套流程需要一个骨灰级玩家至少20分钟的时间才能完成,总计要操作24000次。
这个东西吧,看似简单,但对AI来说却非常困难。
7岁小孩看10分钟就能学会
对于最简单的木镐,让人类玩家从头开始学过程并不太难。
一个死宅不到3分钟用单个视频就能教会下一个。
演示视频全长2分52秒
然而,钻石镐的制作就复杂多了。
不过即便如此,一个7岁小孩也只需看上十分钟的演示视频,就能学会了。
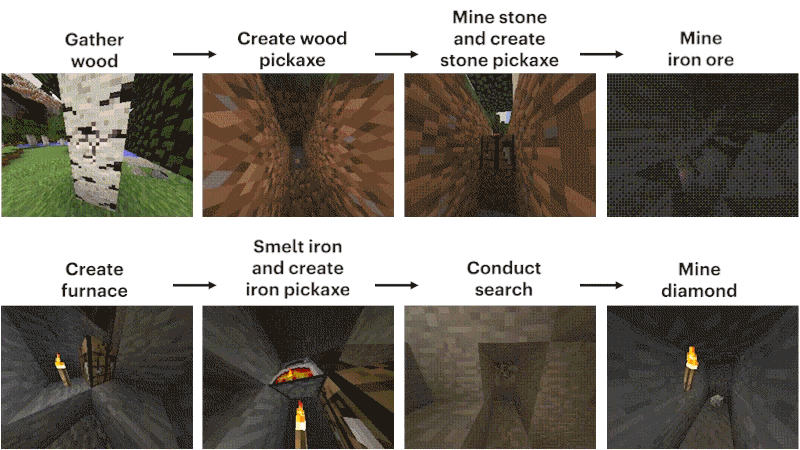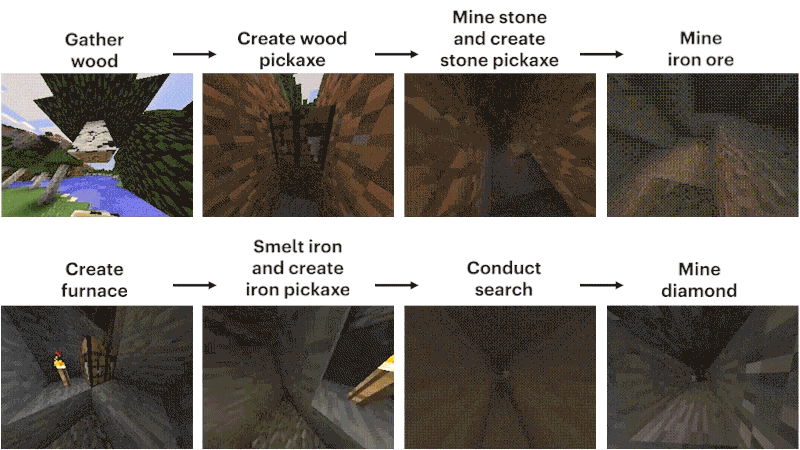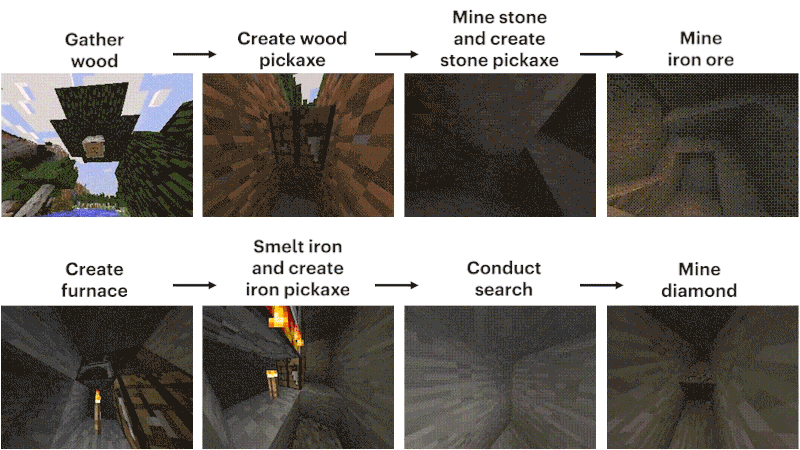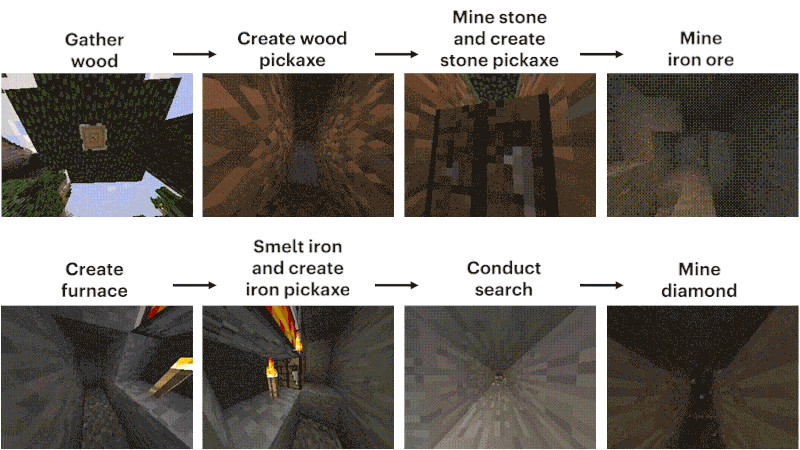
这个任务的难点,主要在如何挖到钻石矿。
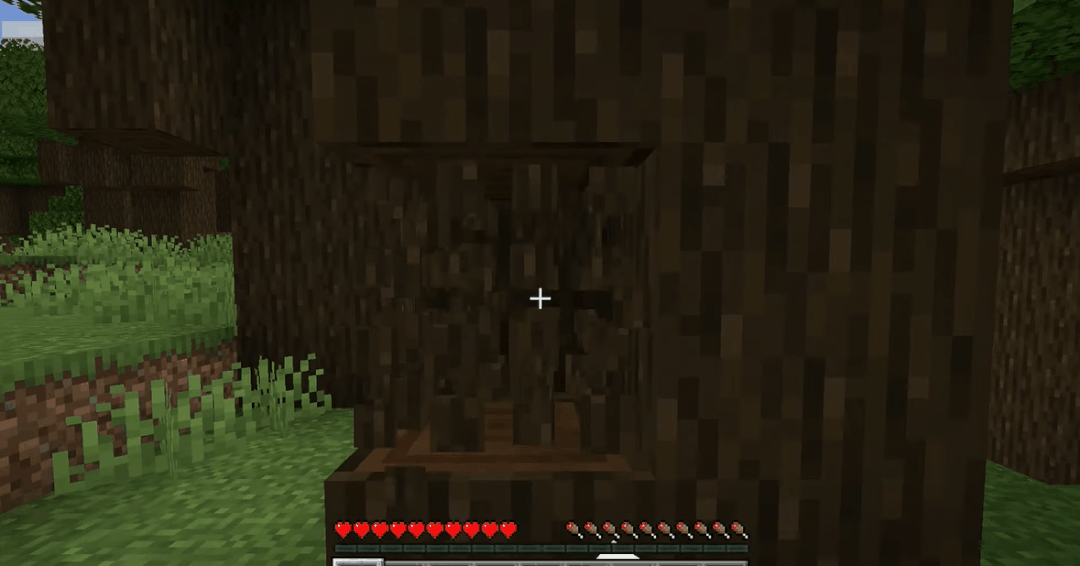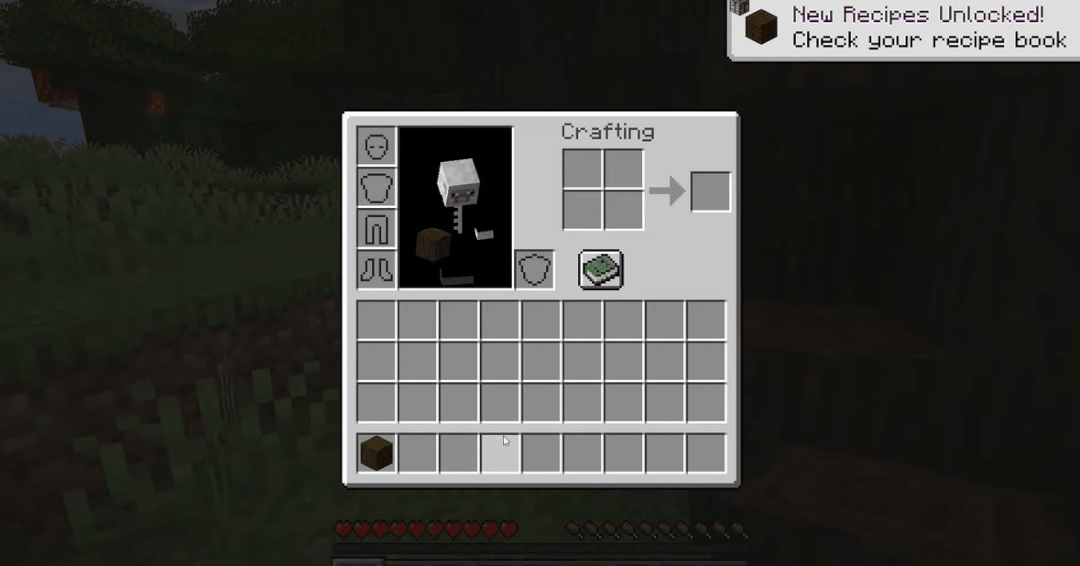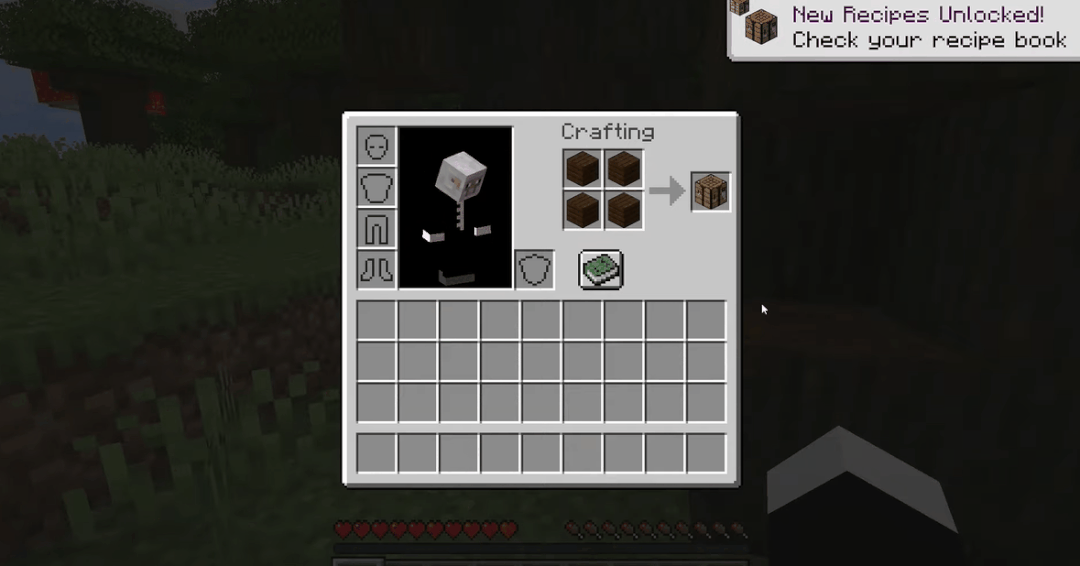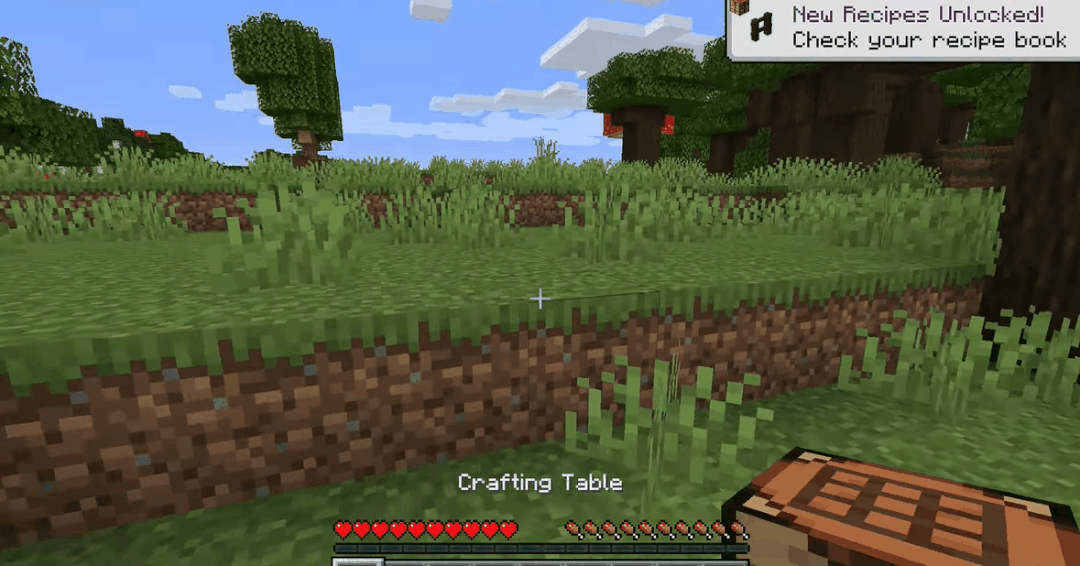
过程大概可以概括为12个步骤:先徒手刨下像素块「木头」,再由原木合成木块,木块制作木棍,木棍制作工坊装具台,工台造木镐,木镐敲石块,石块加木棍做石镐,石镐打造炼炉,炼炉加工铁矿,铁矿熔铸铁锭,铁锭制作铁镐,铁镐去挖钻石。

现在,压力来到了AI这边。
正巧,CMU、OpenAI、DeepMind、Microsoft Research等机构自2019年起,就搞了一个相关的比赛——MineRL。
参赛选手需要自研出一个「自主从零开始打造工具、自动寻找并挖掘钻石矿」的人工智能体,而获胜条件也很简单—最快者胜出。
结果如何?
在首届MineRL比赛结束之后,「7岁小孩看10分钟视频就学会,AI用了8百万步还搞不定」,可是上了Nature杂志的。
数据虽多,但我用不上啊
「我的世界」作为沙盒建筑游戏,其玩家策略、游戏内虚拟环境的高开放性,特别适合作为各种AI模型学习、决策能力的测试场和试金石。
而且作为一款「国民级」的游戏,想在网上找到和「我的世界」相关的视频简直易如反掌。
然而,不管是搭建教程,还是炫耀自己的作品,从某种程度上来说都只是在画面上呈现出的结果。
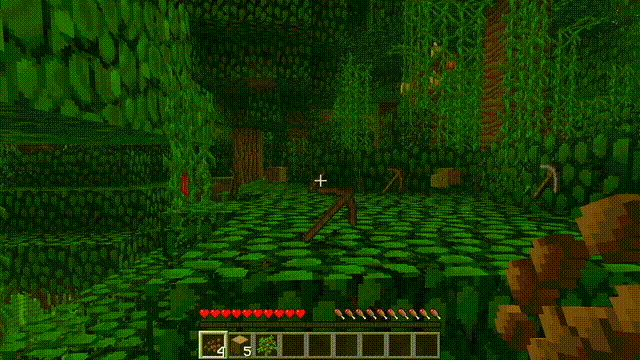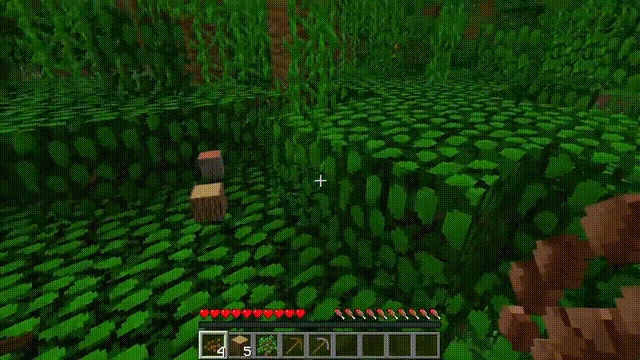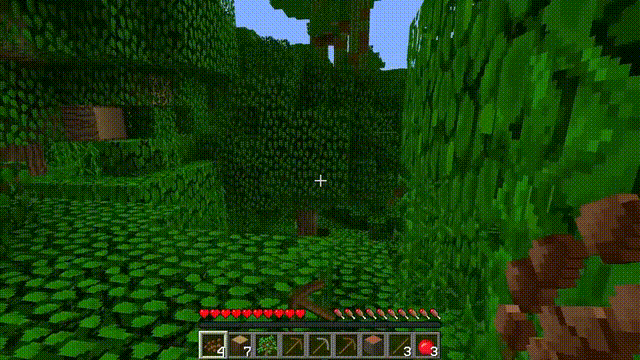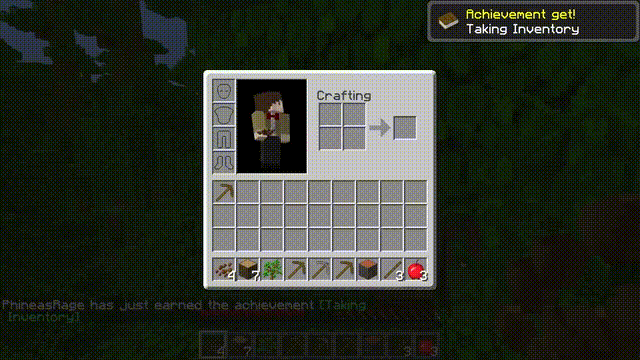
换句话说,看视频的人只能知道up主干了个啥,干的怎么样,但没法知道是怎么干的。
更具体点,电脑屏幕上呈现出来的只是结果,而操作步骤是up主在键盘上的不停点击,以及鼠标的不停移动,这部分是看不到的。
甚至,连这个过程都是经过剪辑的,人看了估计都学不会,更别说AI了。
雪上加霜的是,不少玩家抱怨在游戏里刨木头的枯燥度,太像做作业完成任务。结果一波更新之后,有不少工具可以直接白捡……这下,连数据都不好找了。
而OpenAI想要让AI学会玩儿「我的世界」,就必须找到一个办法,能够让这些海量的未标注的视频数据派上用场。
视频预训练模型——VPT
于是,VPT应运而出。

论文地址:https://cdn.openai.com/vpt/Paper.pdf
这东西说新也新,但是却并不复杂,是一种半监督式的模仿学习方法。
首先,收集一波数据标注外包们玩游戏的数据,其中包含视频和键鼠操作的记录。
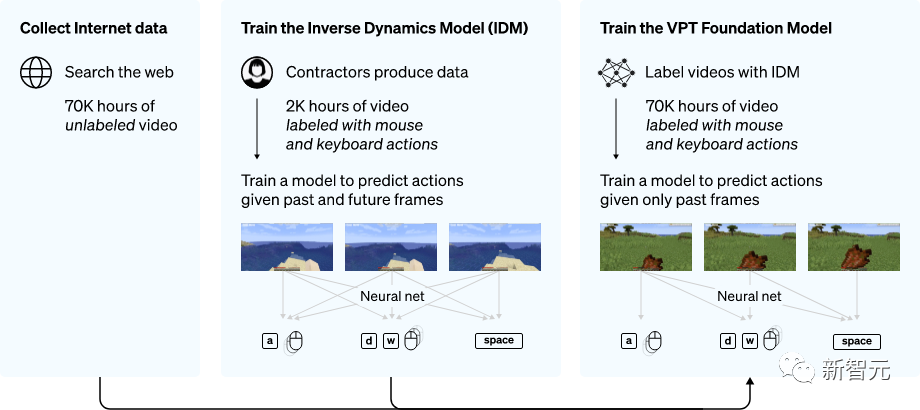
VPT方法概述
然后,研究人员用这些数据搞了个逆动力学模型(inverse dynamics model,IDM),可以推测出视频中每一步进行的时候,键鼠都是怎么动的。
这样一来,整个任务就变得简单多了,只需要比原来少很多的数据就可以实现目的。
用一小撮外包数据搞完IDM之后,就可以用IDM接下来标注更大规模的无标记数据集了。
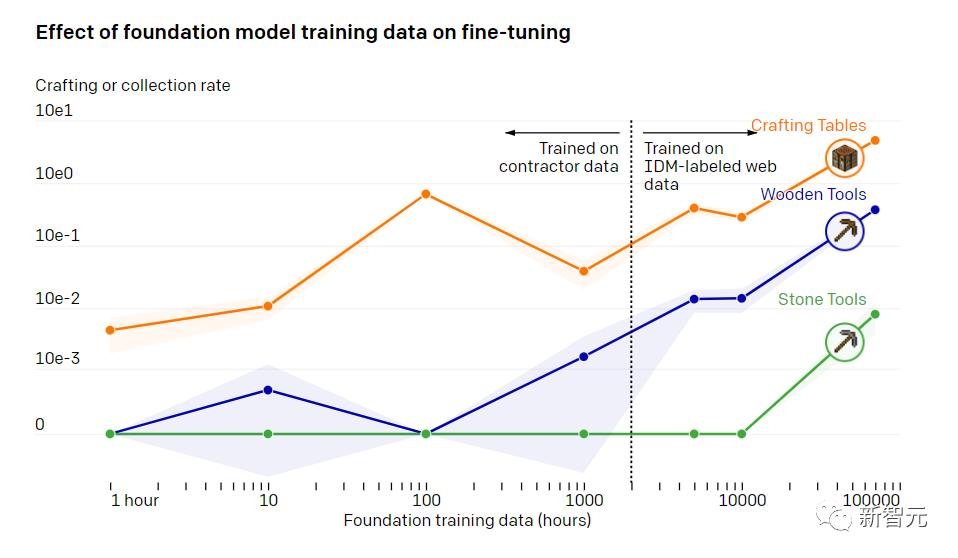
基础模型训练数据对微调的影响
在训练了70000个小时以后,OpenAI的行为克隆模型就能实现各种别的模型做不到的工作了。
模型学会了怎么砍树收集木头,怎么用木头做木条,怎么用木条做桌子。而这一套事儿需要一个比较熟练的玩家操作小50秒的时间。
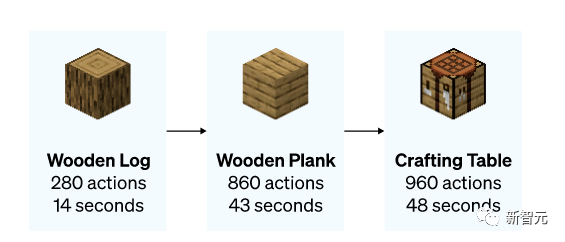
除了做桌子,模型还能游泳,打猎,吃东西。
甚至还有「跑跳搭」的骚操作,也就是起跳的时候脚下放个砖块或者木块,跳着跳着就能搭个柱子。这属于是骨灰级玩家的必修课了。
制作桌子(0 shot)

打猎(0 shot)

「跑跳搭」简陋版(0 shot)
而为了让模型能完成一些更精细的任务,一般还会把数据集微调成更小的规模,区分细小的方向。
OpenAI做了一项研究,展示了用VPT训练过的模型,再经过了微调之后,有多适应下游的数据集。
研究人员邀请人玩儿了10分钟的「我的世界」,用基础材料搭了个房子。他们希望通过这种方式可以加强模型执行一些游戏初期的任务的能力,比如说搭一个工作台。
当对该数据集进行完微调以后,研究人员不仅发现模型在执行初期任务时更加得心应手,还发现模型自个儿研究明白了怎么分别做出一张木制的工作台,和一张石制的工具台。
有时候,研究人员还能看到模型自己搭建简陋的避难所,搜查村子,还有抢箱子。
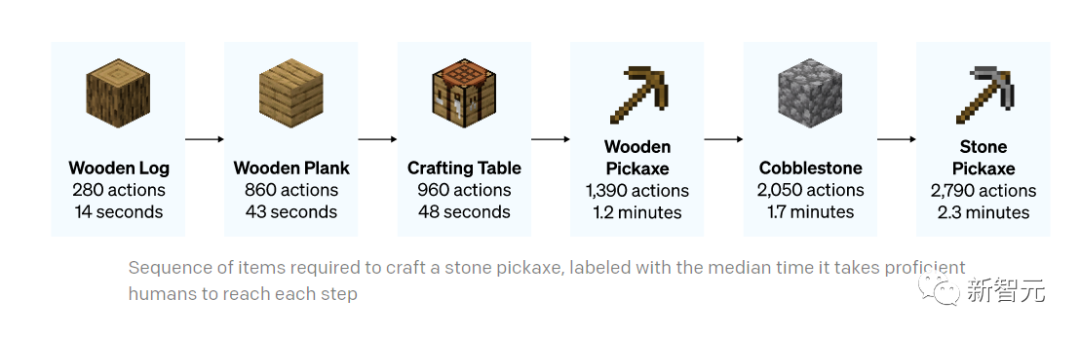
制作一把石镐的全过程(下方标注的时间是一名熟练玩家执行同样的任务的耗时)
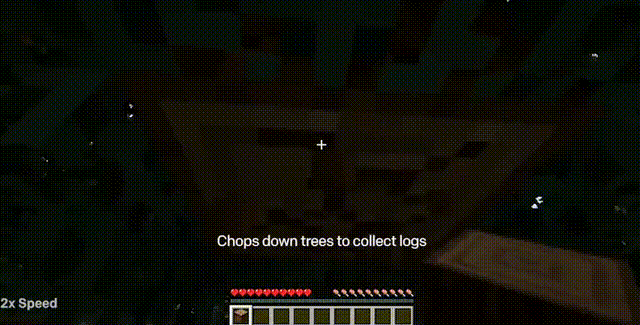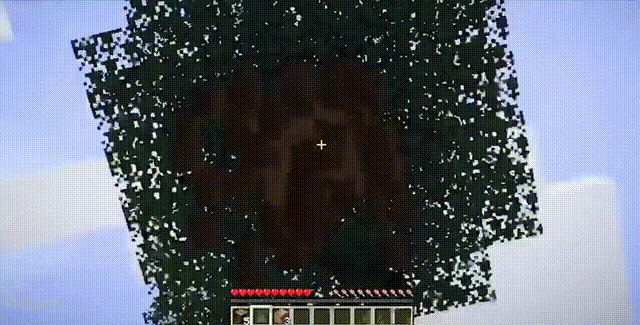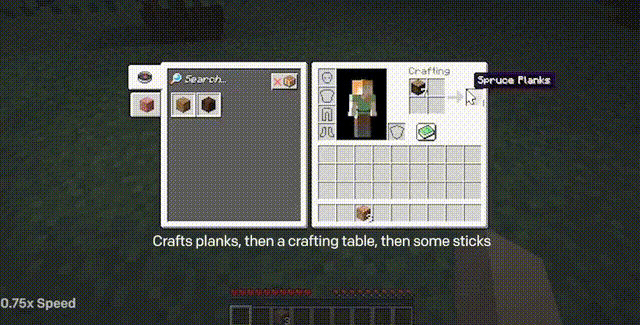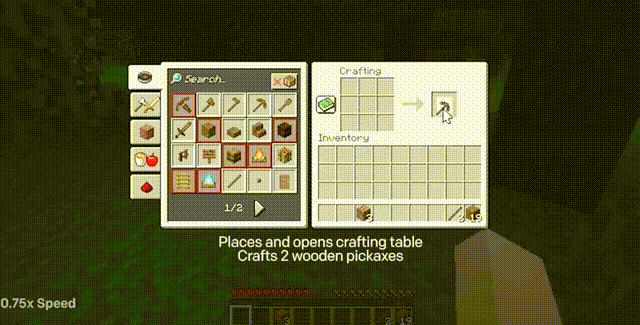
制作石镐
然后我们来看看,OpenAI的专家们是怎么进行的微调。
他们使用的办法是,强化学习(RL)。
大多数RL方法通过随机探索先验来解决这些挑战,例如模型通常被激励通过熵奖励随机行动。VPT 模型应该是RL更好的先验模型,因为模拟人类行为可能比采取随机行动更有帮助。
研究人员将模型设置为收集钻石镐这类艰巨任务,这是「我的世界」中前所未有的功能,因为执行整个任务时使用本机人机界面时会变得更加困难。
制作钻石镐需要一系列漫长而复杂的子任务。为了使这项任务易于处理,研究人员为序列中的每个项目奖励智能体。
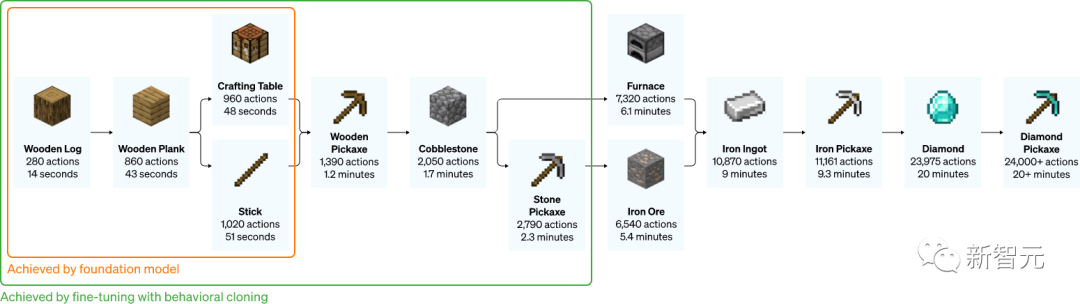
他们发现,从随机初始化(标准RL方法)训练的RL策略几乎没有获得任何奖励,从不学习收集日志,而且很少收集木棍。
与之形成鲜明对比的是,VPT模型的微调不仅可以学习如何制作钻石镐,而且在收集所有物品方面的成功率,甚至达到人类水平。
而这是第一次有人展示能够在「我的世界」中制作钻石工具的计算机模型。
参考资料:
https://openai.com/blog/vpt/
