
惊!Rust 代码竟然这么慢的吗?
Rust 性能好,但一定如此吗?!这篇文章也许会让你吃惊!
我最近发表了一篇博客文章[1],正如我所预料的(实际上,希望因为这将吸引人们为这项 “study” 做出贡献),在互联网上引发了相当多的争论!
这篇文章是关于 Lutz Prechelt 以前对 Java 和 C/C++ 进行比较的研究,以及一些后续的文章,这些文章将其他语言加入了比较,包括 Common Lisp 和一些脚本语言。
我决定试着看看这些 21 年前发表的论文的结果是否仍然站得住脚,或者是否从那时起事情发生了彻底的改变。
我找不到一群学生(更不用说专业的程序员)用多种语言为我的 “study” 编写程序,所以我做了多次这件事,可以说是把最常见的解决问题的方法(基于 Peter Norvig 的代码[2])移植到其他语言: Java、 Rust、Dart,以及后来的 Julia。
结果[3]令人震惊:Rust 是最慢的语言之一!它有最低的内存使用量,但也是最多的代码行数(如果只算相同算法的实现)。
今天,我想通过展示为什么我的 Rust 代码如此缓慢,以及通过一些小的修复,它可以在“竞争”中胜过其他语言,至少在性能方面(正如我发现的那样,仅在某些类型的输入方面),以此来安抚愤怒的 Rust 粉丝和其他关注方。
感谢 Rust 粉丝[4],利用他们的大量空闲时间,告诉我为什么我的 Rust 代码是如此缓慢,以及如何修复它!
原始 Common Lisp 转为 Rust
在我们开始研究慢的 Rust 代码之前,让我们先看看原始的 Common Lisp 代码。
下面是 Peter Norvig 解决 Prechelt 手机编码问题的 Lisp 解决方案的精髓(为简洁起见删除了注释):
(defun print-translations (num digits &optional (start 0) (words nil))
(if (>= start (length digits))
(format t "~a:~{ ~a~}~%" num (reverse words))
(let ((found-word nil)
(n 1)) ; leading zero problem
(loop for i from start below (length digits) do
(setf n (+ (* 10 n) (nth-digit digits i)))
(loop for word in (gethash n *dict*) do
(setf found-word t)
(print-translations num digits (+ 1 i) (cons word words))))
(when (and (not found-word) (not (numberp (first words))))
(print-translations num digits (+ start 1)
(cons (nth-digit digits start) words))))))
你可以在这里看到完整的代码[5]。
这是一个有趣而简短的解决方案,而且是我自己想不出来的。我想到的是基于 Trie[6] 数据结构(在本文中称为 Java1,指的是第一个 Java 实现[7],而不是 JDK 1.0),但那是另一回事了。
无论如何,把它移植到其他语言上看起来非常简单和有趣,所以我就这么做了。假设你可以使用相同的算法来解决问题,那么可以检查一种语言到底能带来多大的不同。
我的论点
这个论点是,一旦你忽略了算法的选择(有时这可能是困难的部分),当你考虑程序做很多不同的事情来达到相同的结果时,语言差异就不会像你想象的那样大。最初的研究实际上有令人信服的证据表明程序员倾向于根据语言提出不同的算法:低级语言程序员倾向于使用低级结构,即使他们的语言允许高级结构。我的理论是,正是这个原因使得低级语言拥有更高的代码行数和更好的性能。一旦你控制了这一点,代码行数和性能应该更加接近。只要你能够使用你选择的语言使用正确的抽象级别来解决问题。
Rust 慢,优化它
回到 Rust 代码... ... 我试图使它尽可能接近原始的 Lisp 代码,以便进行苹果对苹果的比较。所以我认为使用大数字作为现有单词的 key 是非常重要的。
很多人批评这个决定,因为他们“知道” BigInt 在很多语言中速度很慢,而 Lisp 就是很擅长这一点。
不过,我们很快就会看到,这不是 Rust 代码慢的原因。
下面是我写的 Rust 代码的一部分,包括我使用的从 word 到 BigUInt 的转换:
use lazy_static::lazy_static;
use num_bigint::{BigUint, ToBigUint};
type Dictionary = HashMap<BigUint, Vec<String>>;
lazy_static! {
static ref ONE: BigUint = 1.to_biguint().unwrap();
static ref TEN: BigUint = 10.to_biguint().unwrap();
}
fn word_to_number(word: &str) -> BigUint {
let mut n = ONE.clone();
for ch in word.chars() {
if ch.is_alphabetic() {
n = &n * (&*TEN) + &char_to_digit(ch);
}
}
n
}
我使用 lazy_static,因为我需要一个 ONE 和 TEN 的全局常量,以避免为 word_to_number 中所示的循环的每一次迭代分配一个 BigUint 实例。
这不仅是可怕的丑陋,而且是完全没有必要和徒劳的。当然,当时我并不知道这一点。根据我之前在 Rust 中的经验(即需要非常量的全局状态,使用 lazy_static),这似乎是解决这个问题的方法。
好吧,但是这里有一个正确的方法,感谢@philipc:
fn word_to_number(word: &str) -> BigUint {
let mut n = 1u8.into();
for digit in word.chars().filter_map(char_to_digit) {
n *= 10u8;
n += digit;
}
n
}
看到这个,我感到很震惊。注意,上面所有的操作仍然使用 BigUint,作为原始的!
类似的,在 print translations 函数中,我写了这样的东西:
let mut n = ONE.clone();
let mut found_word = false;
for i in start..digits.len() {
n = &n * (&*TEN) + &nth_digit(digits, i);
...
下面才是我应该写的:
let mut n = 1u8.into();
let mut found_word = false;
for i in start..digits.len() {
n *= 10u8;
n += nth_digit(digits, i);
...
这还需要对 char_to_digit 进行一个小的更改,如果感兴趣,请检查完整的 diff[8]。
通过这种可读性的改进,代码实际上已经运行得更快了(但是没有 CL 快) ! !
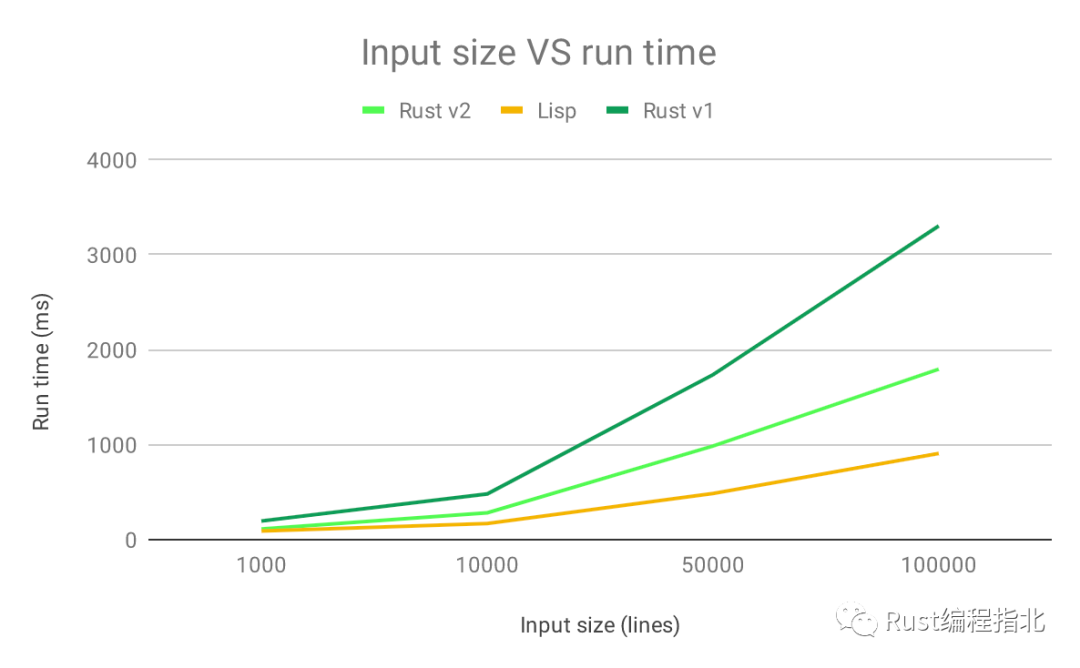
这表明,有时候,更好的代码也是更高效的代码。
下一步是为每个部分解决方案避免低效的列表副本(或 Rust Vec) ,我这样做是为了让代码保持简单。
每次算法为一个潜在的解决方案找到一个新词时,它需要用该词汇的累积递归到当前的部分解决方案中。它需要在潜在的几个单词在同一水平,所以我们不能只是改变列表,忘记它。这就是为什么我使用 Common Lisp 的方法,大致如下:
(cons word words)
这将返回一个新列表,其中包含单词的所有元素,加上单词,没有可变的单词。
正如你可能知道的,Lisp 是围绕 list 构建的,因此在 Lisp 中这样做是非常高效的。但是等价的 Rust 不是。
这就是我所做的:
let mut partial_solution = words.clone();
partial_solution.push(word);
// recurse passing the current `partial_solution`
这将复制列表,然后在递归之前追加新单词。这意味着我们可以在保留原始部分解的情况下对每个单词重复此操作。此外,文字可以保持不变,正如函数式程序员所知,不变性是好的!
正如许多评论者指出的那样,从性能的角度来看,这是愚蠢的。你知道,一旦递归,同样的代码将再次运行(或不再运行) ,而且在任何情况下,一旦递归完成,我们可以从原始列表中弹出这个单词以获得完全相同的结果!
具有不可变结构的函数式编程可能很棒,但是它需要不可变数据结构的“智能”实现,而仅仅克隆一个 Vec 是不够的!
在这种情况下,我们可以这样做:
words.push(word);
// recurse passing the current `partial_solution`
words.pop();
搞定了,对吧?错... 我们现在必须处理 borrow 检查程序,它告诉我们不能获得一个全新的 String 实例并将其放入 Vec<&String> 中,因为 Vec 不是它的任何字符串的所有者。
我在 Rust 中已经见过很多次了:我写了大量的代码,但是对生命周期有点粗心,只是为了在我的程序中随处改变变量和函数的类型,以避免到处复制使它工作。
这意味着,在 Rust 中编写高效的代码需要很多事先考虑。在这种情况下,使用可变 Vec 的微小修改实际上要求我们只处理生命周期与 Vec 匹配或超过的字符串。
要做到这一点,我们需要做两件事。
首先,为 Vec 上运行的函数添加一个显式的生存期,从:
fn print_translations(
num: &str,
digits: &Vec<char>,
start: usize,
words: Vec<&String>,
dict: &Dictionary,
) -> io::Result<()>
到:
fn print_translations<'dict>(
num: &str,
digits: &Vec<char>,
start: usize,
words: &mut Vec<&'dict str>,
dict: &'dict Dictionary,
) -> io::Result<()>
现在,我们有一个问题,不是所有我们插入的词都来自 dict:一个词找不到时,表明它将是替换数字。
现在,以下代码编译不通过:
let digit = nth_digit(digits, start).to_string();
words.push(&digit);
这里的数字有错误的生命周期。
...
62 | words.push(&digit);
| -----------^^^^^^-
| | |
| | borrowed value does not live long enough
| argument requires that `digit` is borrowed for `'dict`
为了解决这个问题,我们必须改变 nth_digit 来给我们一个足够长的 String!
但是我们怎么才能做到呢?在这种情况下,实际上非常简单:只有 10 个可能的数字,所以我们可以有一个包含所有数字的静态列表!nth_digit 将总是返回一些静态生命周期的数据,这应该可行,因为这肯定会比 dict 存活更长。
nth_digit 的实现来自这个怪物:
fn nth_digit(digits: &Vec<char>, i: usize) -> BigUint {
let ch = digits.get(i).expect("index out of bounds");
((*ch as usize) - ('0' as usize)).to_biguint().unwrap()
}
改为:
fn nth_digit(digits: &[char], i: usize) -> u8 {
digits[i] as u8 - b'0'
}
这仍然有效,因为当我们做 n += nth_digit(digits, i);,它甚至可以在 n 是 BigUint 的情况下工作!
当我们需要在 words 插入一个新数字的时候:
static DIGITS: [&str; 10] = ["0", "1", "2", "3", "4", "5", "6", "7", "8", "9"];
...
let digit = nth_digit(digits, start);
words.push(DIGITS[usize::from(digit)]);
在这里,像我这样的 Rust 新手(我已经断断续续地使用 Rust 两年多了,但要摆脱新手确实需要一些时间或很多投入)可能会说,与 Java 或 Lisp 相比,这有点太复杂了。生命周期可能会变得非常棘手。然而,在这种情况下,似乎有人具有良好的 Rust 专业知识自己从头开始。
我很乐意和很多 Rust 程序员一起进行一项研究,看看实际操作情况如何。
你可能会问,我们在性能方面做得怎么样!
检查一下(从 v2 到 v3 的完整差异[9])):

没错!Rust 代码现在在性能上几乎与 Common Lisp 代码完全匹配!
Rust 风格的罪恶
显然,除了糟糕的性能,我的原始代码还有很多风格上的缺陷。
例如,不应该这样做:
fn print_solution(num: &str, words: &Vec<&str>)
如果你想避免被羞辱,就这么做吧:
fn print_solution(num: &str, words: &[&str])
有时使用 if let Ok() 可能很诱人,但是不要这样做:
let words = read_lines(words_file)?;
for line in words {
if let Ok(word) = line {
...
你可能忘记了这实际上会忽略 IO 错误!
正确的方法:
for word in read_lines(words_file)?.flatten() {
...
}
很棒吧? !如果你还不知道这些习惯用法,你会觉得自己像个白痴,因为你以前写过那些糟糕的代码。
Rust 有很多这样的东西。
这里还有一个:按顺序读取命令行参数,允许默认值。
我糟糕的方法(实际上我花了半个小时来决定如何做) :
let mut args: Vec<_> = args().skip(1).collect();
let words_file: String = if !args.is_empty() { args.remove(0) } else { "tests/words.txt".into() };
let input_file: String = if !args.is_empty() { args.remove(0) } else { "tests/numbers.txt".into() };
以上是新手代码。
下面才是专业人士会做的:
let mut args = args().skip(1);
let words_file = args.next().unwrap_or_else(|| "tests/words.txt".into());
let input_file = args.next().unwrap_or_else(|| "tests/numbers.txt".into());
显然,你不需要将这些方块收集到一个 Vec 中,然后移除它们来获得所有权!在迭代器上使用 next() 实际上是在消费项。
因为 std::env::Args[10] 实现了 Iterator<String> ,而不是 Iterator<&str> 或其他什么,消费它会让你拥有 Args 的所有权(它克隆了 Args 吗?魔法般地背后的字符串,它返回一个单一的 &'static str,会莫名其妙?)。
不幸的是,这些样式上的改进并没有给我们带来多少额外的性能,前面的图表仍然很好地反映了当前代码的性能。
无论如何,这里是风格改进的完整差异[11]。
更进一步
Rust 开发者们有更多优化的方法:
@bugaevc 想出了一个摆脱 BigUint并使用 Vec<u8> 的实现[12],完整 diff。
作为他实现的一个小例子,这里有一个 word_to_number 函数,它看起来还是很整洁的。
fn word_to_number(word: &str) -> Vec<u8> {
word.chars()
.filter(char::is_ascii_alphabetic)
.map(char_to_digit)
.map(|d| d + b'0')
.collect()
}
这里有一个 Java 版本:https://github.com/renatoathaydes/prechelt-phone-number-encoding/commit/5cd7d794291c60509cb73ed38f4a76b312a59f5d。
现在看对比:
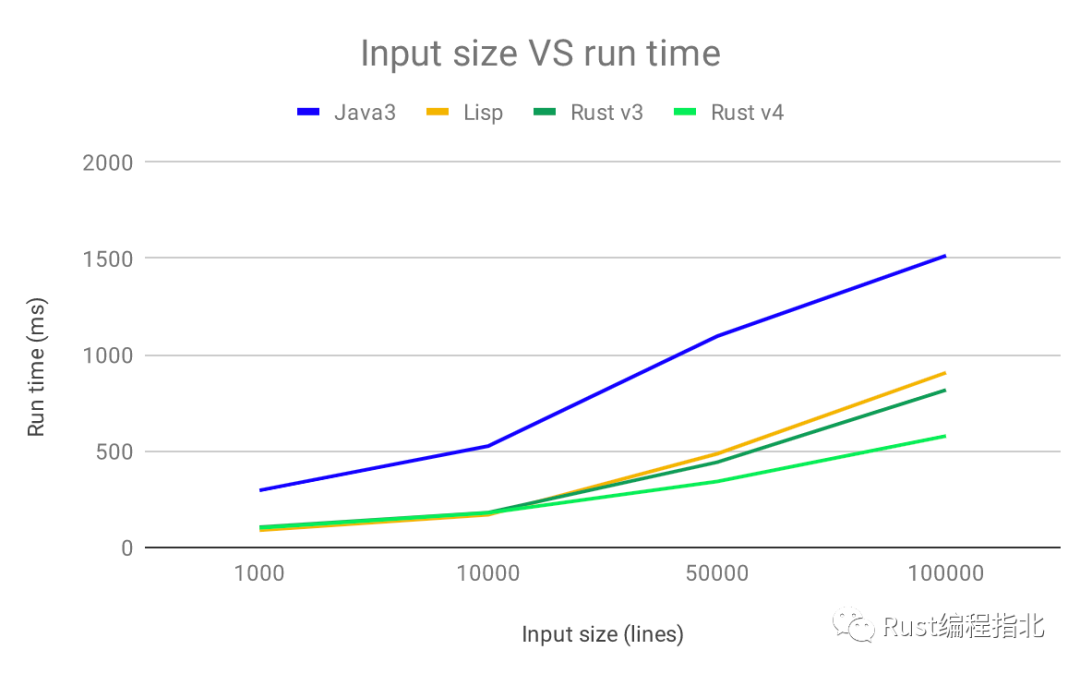
正如您所看到的,如果你真的需要最后一毫秒的性能,Rust 可以满足你!
Java 现在似乎已经远远落后了(至少它比最初的、性能错误缠身的 Rust 实现要好得多)。
总结
在 Rust 中编写代码并不意味着你的代码会非常快,可能很容易犯错误,并且性能很慢。正如这篇博客文章所展示的,你甚至可能需要流很多汗才能打败 Common Lisp 和 Java。
这篇博客文章陷入了 Java 和 Rust 之间的疯狂比拼,看谁能跑得更快... ... 这从来不是我的本意,我想要的只是展示如何修复我糟糕的 Rust 代码,但是为了知道性能已经足够好,我不得不使用其他语言进行比较,事情很快就陷入了一场无意义的比较,去解决一个没有人关心的问题,这样我们就可以找出哪种语言真的是最快的。
最好的事情是,最后,受到最多关注的语言---- Java 和 Rust---- 的性能是如此接近,以至于我认为语言的选择并不像人们认为的那么重要,我认为已经得到了显著的加强。
有时候,无论你使用哪种语言,或者你的程序员有多聪明,你的代码都会运行得非常快,以至于你甚至不会考虑其他语言。
其他时候,我几乎总是会说,你需要注意你正在使用的算法,但仍然可以使用你最喜欢的语言。
最后,有时候每个周期都很重要。在这种情况下,你可能会认为选择一种通常被认为是某个领域中最快的特定语言是安全的,但是除非你实际测量它,否则几乎不可能知道。
是不是像大家都知道的那样,Rust 是最快的? 对于这个特定的问题,JVM 在真正重要的时候却侥幸成功了?
或者你是否认为对于吞吐量比延迟更重要的长时间运行的进程来说,像 Java (以及 Kotlin、 Scala、 Groovy 和 Clojure)这样的语言在运行时有一个 JIT 编译器来修复所有那些糟糕的程序员引入到代码中的低效问题,这是必不可少的?
我不知道... 我所知道的是,如果我需要编写一个 CLI,我会用 Rust,因为它是一个可爱的语言,一旦你跨过最初的障碍。但如果我需要一个永远运行的服务器,我可能只是坚持使用 Java,并知道我的坏代码也能运行的挺快!
原文:https://renato.athaydes.com/posts/how-to-write-slow-rust-code.html,有删减!
参考资料
一篇博客文章: https://renato.athaydes.com/posts/revisiting-prechelt-paper-comparing-languages.html
[2]Peter Norvig 的代码: https://norvig.com/
[3]结果: https://docs.google.com/spreadsheets/d/14MFvpFaJ49XIA8K1coFLvsnIkpEQBbkOZbtTYujvatA/edit#gid=1209911081
[4]Rust 粉丝: https://github.com/renatoathaydes/prechelt-phone-number-encoding/pull/1
[5]代码: http://www.norvig.com/java-lisp.html
[6]Trie: https://en.wikipedia.org/wiki/Trie
[7]Java 实现: https://github.com/renatoathaydes/prechelt-phone-number-encoding/blob/master/src/java/Main.java
[8]diff: https://github.com/renatoathaydes/prechelt-phone-number-encoding/commit/97bf6346aa1599afed007217b7630e7d0c719214
[9]v2 到 v3 的完整差异: https://github.com/renatoathaydes/prechelt-phone-number-encoding/commit/a9126a4b662e830bcb7f20d5169b9a733870c652
[10]std::env::Args: https://doc.rust-lang.org/std/env/struct.Args.html
完整差异: https://github.com/renatoathaydes/prechelt-phone-number-encoding/commit/297d861d85b75a6bf3e1670125216d644affa834
[12]实现: https://github.com/bugaevc/prechelt-phone-number-encoding/blob/speed-up-rust/src/rust/phone_encoder/src/main.rs
我是 polarisxu,北大硕士毕业,曾在 360 等知名互联网公司工作,10多年技术研发与架构经验!2012 年接触 Go 语言并创建了 Go 语言中文网!著有《Go语言编程之旅》、开源图书《Go语言标准库》等。
坚持输出技术(包括 Go、Rust 等技术)、职场心得和创业感悟!欢迎关注「polarisxu」一起成长!也欢迎加我微信好友交流:gopherstudio