
数学推导+纯Python实现机器学习算法19:CatBoost
Python机器学习算法实现
Author:louwill
Machine Learning Lab
本文介绍GBDT系列的最后一个强大的工程实现模型——CatBoost。CatBoost与XGBoost、LightGBM并称为GBDT框架下三大主流模型。CatBoost是俄罗斯搜索巨头公司Yandex于2017年开源出来的一款GBDT计算框架,因其能够高效处理数据中的类别特征而取名为CatBoost(Categorical+Boosting)。相较于XGBoost和LightGBM,CatBoost的主要创新点在于类别特征处理和排序提升(Ordered Boosting)。

处理类别型特征
对于类别特征的处理是CatBoost的一大特点,这也是其命名的由来。CatBoost通过对常规的目标变量统计方法添加先验项来对其进行改进。除此之外,CatBoost还考虑使用类别特征的不同组合来扩大数据集特征维度。
通用处理方法
类别型特征在结构化数据集中是一个非常普遍的特征。这类特征区别于常见的数值型特征,它是一个离散的集合,比如说性别(男、女),学历(本科、硕士、博士等),地点(杭州、北京、上海等),有些时候我们还会碰到几十上百个取值的类别特征。
对于类别型特征,以往最通用的方法就是one-hot编码,如果类别型特征取值数目较少的话,one-hot编码不失为一种比较高效的方法。但当类别型特征取值数目较多的话,one-hot编码就不划算了,它会产生大量冗余特征,试想一下一个类别数目为100个的类别型特征,one-hot编码会产生100个稀疏特征,茫茫零海中的一个1,这对训练算法本身而言就是个累赘。
所以,对于特征取值数目较多的类别型特征,一种折中的方法是将类别数目进行重新归类,使其类别数目降到较少数目再进行one-hot编码。另一种最常用的方法则是目标变量统计(Target Statisitics,TS),TS计算每个类别对于的目标变量的期望值并将类别特征转换为新的数值特征。CatBoost在常规TS方法上做了改进。
目标变量统计
CatBoost算法设计一个最大的目的就是要更好的处理GBDT特征中的类别特征。常规的TS方法最直接的做法就是将类别对应的标签平均值来进行替换。在GBDT构建决策树的过程中,替换后的类别标签平均值作为节点分裂的标准,这种做法也被称为Greedy Target-based Statistics , 简称Greedy TS,其计算公式可表示为:
Greedy TS一个比较明显的缺陷就是当特征比标签包含更多信息时,统一用标签平均值来代替分类特征表达的话,训练集和测试集可能会因为数据分布不一样而产生条件偏移问题。CatBoost对Greedy TS方法的改进就是添加先验分布项,用以减少噪声和低频类别型数据对于数据分布的影响。改进后的Greedy TS方法数学表达如下:
其中为添加的先验项,为大于的权重系数。
除了上述方法之外,CatBoost还提供了Holdout TS、Leave-one-out TS、Ordered TS等几种改进的TS方法,这里不一一详述。
特征组合
CatBoost另外一种对类别特征处理方法的创新在于可以构建任意几个类别型特征的任意组合为新的特征。比如说用户ID和广告主题之间的联合信息。如果单纯地将二者转换为数值特征,二者之间的联合信息可能就会丢失掉。CatBoost则考虑将这两个分类特征进行组合构成新的分类特征。但组合的数量会随着数据集中类别型特征的数量成指数增长,因此不可能考虑所有的组合。
所以,CatBoost在构建新的分裂节点时,会采用贪心的策略考虑特征之间的组合。CatBoost将当前树的所有组合、类别型特征与数据集中的所有类别型特征相结合,并将新的类别组合型特征动态地转换为数值型特征。
预测偏移与排序提升
CatBoost另一大创新点在于提出使用排序提升(Ordered Boosting)的方法解决预测偏移(Prediction Shift)的问题。
预测偏移
所谓预测偏移,即训练样本的分布与测试样本的分布之间产生的偏移。
CatBoost首次揭示了梯度提升中的预测偏移问题。认为预测偏移就像是TS处理方法一样,是由一种特殊的特征target leakage和梯度偏差造成的,我们来看一下在梯度提升过程中这种预测偏移是这么传递的。
假设前一轮训练得到强学习器为,当前损失函数为,则本轮迭代则要拟合的弱学习器为:
进一步的梯度表达为:
的数据近似表达为:
最终的链式的预测偏移可以描述为:
- 梯度的条件分布和测试数据的分布存在偏移;
- 的数据近似估计与梯度表达式之间存在偏差;
- 预测偏移会影响到的泛化性能。
排序提升
CatBoost采用基于Ordered TS的Ordered Boosting方法来处理预测偏移问题。排序提升算法流程如下图所示。

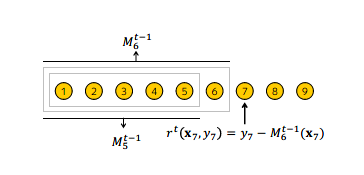
对于训练数据,排序提升先生成一个随机排列,随机配列用于之后的模型训练,即在训练第个模型时,使用排列中前个样本进行训练。在迭代过程中,为得到第个样本的残差估计值,使用第个模型进行估计。
但这种训练个模型的做法会大大增加内存消耗和时间复杂度,实际上可操作性不强。因此,CatBoost在以决策树为基学习器的梯度提升算法的基础上,对这种排序提升算法进行了改进。
CatBoost提供了两种Boosting模式,Ordered和Plain。Plain就是在标准的GBDT算法上内置了排序TS操作。而Ordered模式则是则排序提升算法上做出了改进。
完整的Ordered模式描述如下:CatBoost对训练集产生个独立随机序列用来定义和评估树结构的分裂,用来计算分裂所得到叶子节点的值。CatBoost采用对称树作为基学习器,对称意味着在树的同一层,其分裂标准都是相同的。对称树具有平衡、不易过拟合并能够大大减少测试时间的特点。CatBoost构建树的算法流程如下图所示。
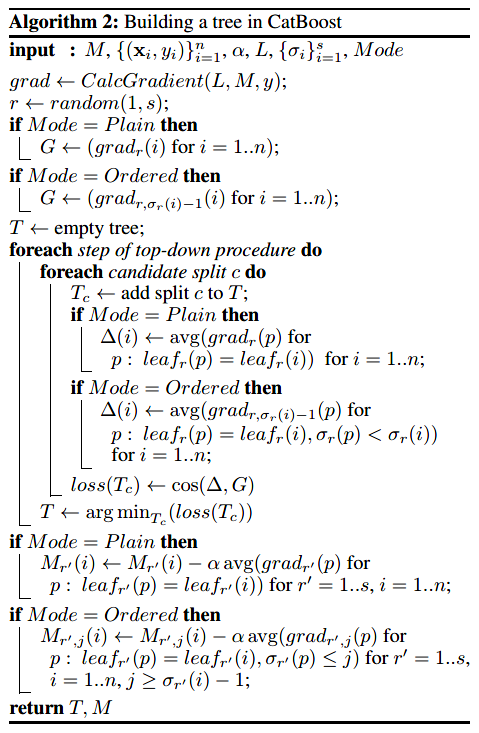
在Ordered模式学习过程中:
- 我们训练了一个模型,其中表示在序列中前个样本学习得到的模型对于第个样本的预测。
- 在每一次迭代中,算法从中抽样一个序列,并基于此构建第步的学习树。
- 基于计算对应梯度。
- 使用余弦相似度来近似梯度,对于每个样本,取梯度。
- 在评估候选分裂节点过程中,第个样本的叶子节点值由与同属一个叶子的的所有样本的前个样本的梯度值求平均得到。
- 当第步迭代的树结构确定以后,便可用其来提升所有模型。
注:这一段比较晦涩难懂,笔者也没有完全深入理解,建议各位读者一定去读一下CatBoost论文原文。
基于构建树算法的完整CatBoost算法流程如下图所示。

除了类别特征处理和排序提升以外,CatBoost还有许多其他亮点。比如说基于对称树(Oblivious Trees)的基学习器,提供多GPU训练加速支持等。
CatBoost与XGBoost、LightGBM对比
CatBoost与LightGBM开源前后时间相差不到3个月,二者都是在XGBoost基础上做出的改进和优化。除了算法整体性能上的差异之外,基于CatBoost最主要的类别型特征处理特色,三者的主要差异如下:
- CatBoost支持最全面的类别型特征处理,可直接传入类别型特征所在列标识然后进行自动化处理。
- LightGBM同样也支持对类别型特征的快速处理,训练时传入类别型特征列所在标识符即可。但LightGBM对于类别特征只是采用直接的硬编码处理,虽然速度较快但不如CatBoost的处理方法细致。
- XGBoost作为最早的GBDT工程实现,其本身并不支持处理类别型特征,只能传入数值型数据。所以一般都需要手动对类别型特征进行one-hot等预处理。
CatBoost论文也给出了在多个开源数据集上与XGBoost和LightGBM性能对比。如下图所示。
CatBoost算法实现
手动实现一个CatBoost系统过于复杂,限于时间精力这里笔者选择放弃。CatBoost源 码可参考:
https://github.com/catboost/catboost
CatBoost官方为我们提供相关的开源实现库catboost,直接pip安装即可。
下面以catboost一个分类例子作为演示。完整的catboost用法文档参考:
https://catboost.ai/docs/concepts/tutorials.html
import numpy as npimport pandas as pdfrom sklearn.model_selection import train_test_splitimport catboost as cbfrom sklearn.metrics import f1_score# 读取数据data = pd.read_csv('./adult.data', header=None)# 变量重命名data.columns = ['age', 'workclass', 'fnlwgt', 'education', 'education-num','marital-status', 'occupation', 'relationship', 'race', 'sex','capital-gain', 'capital-loss', 'hours-per-week', 'native-country', 'income']# 标签转换data['income'] = data['income'].astype("category").cat.codes# 划分数据集X_train, X_test, y_train, y_test = train_test_split(data.drop(['income'], axis=1), data['income'],random_state=10, test_size=0.3)# 配置训练参数clf = cb.CatBoostClassifier(eval_metric="AUC", depth=4, iterations=500, l2_leaf_reg=1,learning_rate=0.1)# 类别特征索引cat_features_index = [1, 3, 5, 6, 7, 8, 9, 13]# 训练clf.fit(X_train, y_train, cat_features=cat_features_index)# 预测y_pred = clf.predict(X_test)# 测试集f1得分print(f1_score(y_test, y_pred))
参考资料:
https://catboost.ai/
CatBoost: unbiased boosting with categorical features
往期精彩:
数学推导+纯Python实现机器学习算法18:LightGBM
数学推导+纯Python实现机器学习算法27:LDA线性判别分析
一个算法工程师的成长之路

长按二维码.关注机器学习实验室