
机器学习基础:令你事半功倍的pipeline处理机制
↑↑↑点击上方蓝字,回复资料,10个G的惊喜
why Pipeline?
你有没有遇到过这种情况:在机器学习项目中,对训练集的各种数据预处理操作,比如:特征提取、标准化、主成分分析等,在测试集上要重复使用这些参数。
为了避免重复操作,这里就要用到机器学习中的pipeline机制
按照sklearn官网的解释
pipeline 有以下妙用:
1、便捷性和封装性:直接调用fit和predict方法来对pipeline中的所有算法模型进行训练和预测。
2、联合的参数选择:你可以一次grid search管道中所有评估器的参数。
3、安全性:训练转换器和预测器使用的是相同样本,管道有助于防止来自测试数据的统计数据泄露到交叉验证的训练模型中。
是不是有点云里雾里?下面我们开始这一期的刨根问题~~
Pipeline的原理
pipeline可以将许多算法模型串联起来,形成一个典型的机器学习问题工作流。
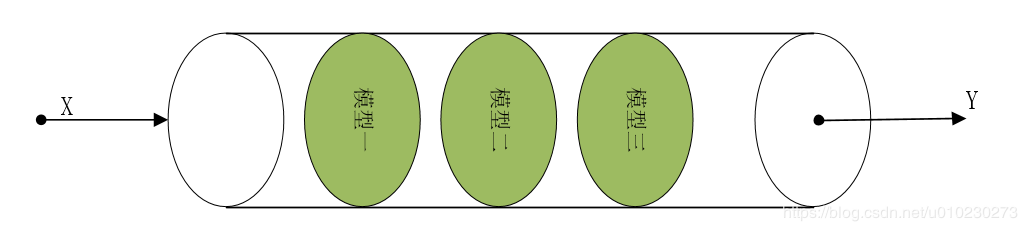
Pipeline处理机制就像是把所有模型塞到一个管子里,然后依次对数据进行处理,得到最终的分类结果,
例如模型1可以是一个数据标准化处理,模型2可以是特征选择模型或者特征提取模型,模型3可以是一个分类器或者预测模型(模型不一定非要三个,根据自己实际需要)。
Pipleline中最后一个之外的所有评估器都必须是变换器,最后一个评估器可以是任意类型(transformer,classifier,regresser),若最后一个评估器是分类器,则整个pipeline就可以作为分类器使用,如果最后一个estimator是个回归器,则整个pipeline就可以作为回归器使用。
注:
Estimator:估计器,所有的机器学习算法模型,都被称为估计器。
Transformer:转换器,比如标准化。转换器的输出可以放入另一个转换器或估计器中作为输入。
一个完整的Pipeline步骤举例:
1.首先对数据进行预处理,比如缺失值的处理
2.数据的标准化
3.降维
4.特征选择算法
5.分类或者预测或者聚类算法(估计器,estimator)
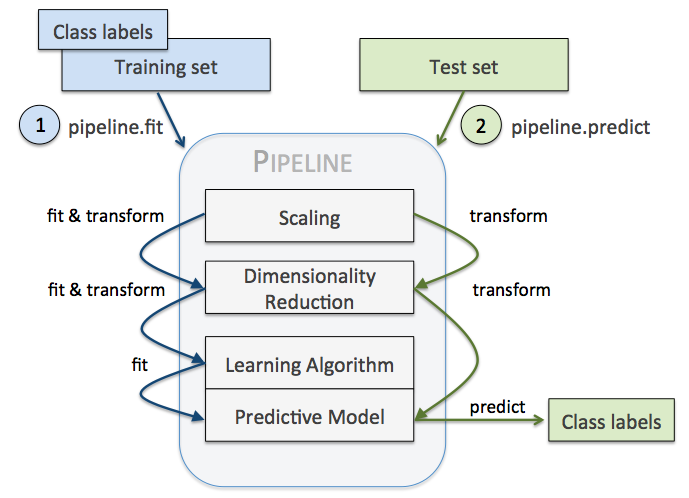
实际上,调用pipeline的fit方法,是用前n-1个变换器处理特征,之后传递给最后的estimator训练。pipeline继承最后一个estimator的所有方法。
Pipeline的用法
调用方法:
sklearn.pipeline.Pipeline(steps, memory=None, verbose=False)
参数详解:
steps : 步骤:使用(key, value)列表来构建,其中 key 是你给这个步骤起的名字, value 是一个评估器对象。
memory:内存参数,默认None
Pipeline的function
Pipline的方法都是执行各个学习器中对应的方法,如果该学习器没有该方法,会报错。假设该Pipline共有n个学习器:
transform:依次执行各个学习器的transform方法
fit:依次对前n-1个学习器执行fit和transform方法,第n个学习器(最后一个学习器)执行fit方法
predict:执行第n个学习器的predict方法
score:执行第n个学习器的score方法
set_params:设置第n个学习器的参数
get_param:获取第n个学习器的参数
Pipeline妙用:模块化Feature Transform
以鸢尾花数据集分类任务为例
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
iris=load_iris()
pipe=Pipeline([('sc', StandardScaler()),('pca',PCA()),('svc',SVC())])
#('sc', StandardScaler()) sc为自定义转换器名称,StandardScaler()为执行标准化任务的转换器
pipe.fit(iris.data,iris.target)
先用 StandardScaler 对数据集每一列做标准化处理(transformer)
再用 PCA 主成分分析进行特征降维(transformer)
最后再用 SVC 模型(Estimator)
输出结果:
Pipeline(memory=None,
steps=[('sc',
StandardScaler(copy=True, with_mean=True, with_std=True)),
('pca',
PCA(copy=True, iterated_power='auto', n_components=None,
random_state=None, svd_solver='auto', tol=0.0,
whiten=False)),
('svc',
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3,
gamma='auto_deprecated', kernel='rbf', max_iter=-1,
probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False))],
verbose=False)
训练得到的是一个模型,可直接用来预测,预测时,数据会从step1开始进行转换,避免了模型用来预测的数据还要额外写代码实现。还可通过pipe.score(X,Y)得到这个模型在X训练集上的正确率。
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
Pipeline妙用:自动化 Grid Search
Pipeline可以结合GridSearch来对参数进行选择:
from sklearn.datasets import fetch_20newsgroups
import numpy as np
news = fetch_20newsgroups(subset='all')
from sklearn.cross_validation import train_test_split
X_train,X_test,y_train,y_test = train_test_split(news.data[:3000],news.target[:3000],test_size=0.25,random_state=33)
from sklearn.feature_extraction.text import TfidfVectorizer
vec = TfidfVectorizer()
X_count_train = vec.fit_transform(X_train)
X_count_test = vec.transform(X_test)
from sklearn.svm import SVC
from sklearn.pipeline import Pipeline
#使用pipeline简化系统搭建流程,将文本抽取与分类器模型串联起来
clf = Pipeline([
('vect',TfidfVectorizer(stop_words='english')),('svc',SVC())
])
# 注意,这里经pipeline进行特征处理、SVC模型训练之后,得到的直接就是训练好的分类器clf
parameters = {
'svc__gamma':np.logspace(-2,1,4),
'svc__C':np.logspace(-1,1,3),
'vect__analyzer':['word']
}
#n_jobs=-1代表使用计算机的全部CPU
from sklearn.grid_search import GridSearchCV
gs = GridSearchCV(clf,parameters,verbose=2,refit=True,cv=3,n_jobs=-1)
gs.fit(X_train,y_train)
print (gs.best_params_,gs.best_score_)
print (gs.score(X_test,y_test))
输出
{'svc__C': 10.0, 'svc__gamma': 0.1, 'vect__analyzer': 'word'} 0.7906666666666666
0.8226666666666667
Pipeline其他用法
Pipeline 还有一些其他用法,这里只简单介绍最最常用的两个make_pipeline
pipeline.make_pipeline(\*steps, \*\*kwargs)
make_pipeline函数是Pipeline类的简单实现,只需传入每个step的类实例即可,不需自己命名,自动将类的小写设为该step的名。
make_pipeline(StandardScaler(),GaussianNB())
输出
Pipeline(steps=[('standardscaler', StandardScaler(copy=True, with_mean=
True, with_std=True)), ('gaussiannb', GaussianNB(priors=None))])
p=make_pipeline(StandardScaler(),GaussianNB())
p.steps
输出
[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True)),
('gaussiannb', GaussianNB(priors=None))]
FeatureUnion
pipeline.FeatureUnion(transformer_list[, …])
FeatureUnion,同样通过(key,value)对来设置,通过set_params设置参数。不同的是,每一个step分开计算,FeatureUnion最后将它们计算得到的结果合并到一块,返回的是一个数组,不具备最后一个estimator的方法。有些数据需要标准化,或者取对数,或onehot编码最后形成多个特征项,再选择重要特征,这时候FeatureUnion非常管用。
from sklearn.pipeline import FeatureUnion
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import FunctionTransformer
from numpy import log1p
step1=('Standar',StandardScaler())
step2=('ToLog',FunctionTransformer(log1p))
steps=FeatureUnion(transformer_list=[step1,step2])
steps.fit_transform(iris.data)
data=steps.fit_transform(iris.data)
大家可以运行看看结果
—END— 欢迎添加我的微信,更多精彩,尽在我的朋友圈。 ↓扫描二维码添加好友↓ 推荐阅读
(点击标题可跳转阅读)
