
OpenSitUp开源项目:零基础开发姿态估计APP

1.项目开源地址
https://github.com/DL-Practise/OpenSitUp
OpenSitUp qq讨论群:965762751
2.项目简介
计算机视觉中有一个应用分支叫做姿态估计,通过人体关键点的方式来估计出一个/多个人的姿态信息。如下图所示:

OpenSitUp是一个基于姿态估计的开源项目,旨在帮助对姿态估计感兴趣的朋友,能够从零开始搭建一个在android手机上运行的仰卧起坐计数APP。主要的技术难点为如何让计算量较大的人体姿态估计网络流畅的运行在手机端,并且实现仰卧起坐的计数功能。掌握了这个项目的原理之后,可以很方便的迁移到类似的运动,健身APP当中。
3.项目成果展示
如下展示的是这个项目最后的APP效果,在人潮涌动的西湖景区,我当众躺下做仰卧起坐,羞煞老夫也!
4.项目目录
由于需要从零开始开发仰卧起坐计数APP,因此整个项目需要包含多个工程,包括数据采集,标注,训练,部署,app开发等,整体目录结构如下图所示:
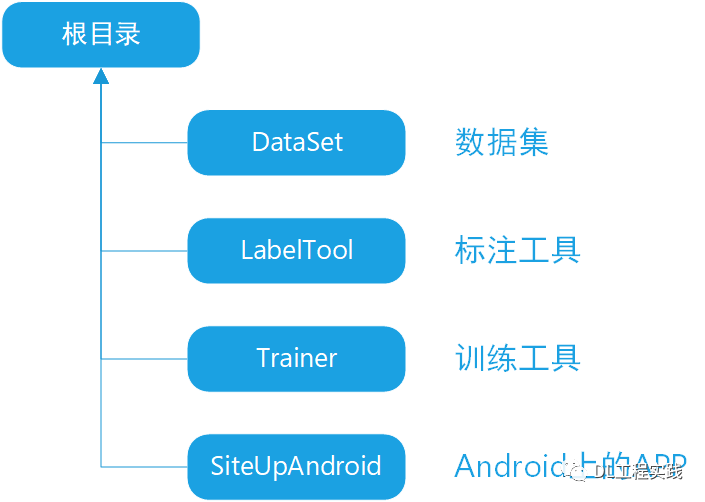
4.1 DataSet
数据集存放目录,这里我预先放置了300多张标注好的图片,用这些图片已经可以训练出“项目成果展示”中展示的效果。但是为了获得更好的性能,您可以采集更多的仰卧起坐图片。
4.2 LabelTool
这里为您准备了一个适用于该项目的标注工具,主要是标注人体的一些关键点。当您采集了很多仰卧起坐的图片之后,可以使用该工具进行标注,生成相应的标签。
4.3 Trainer
这是一个基于pytorch的关键点训练工具,里面包含针对手机设计的轻量级关键点检测网络。
4.4 SiteUpAndroid
Android上的仰卧起坐计数APP。
5.项目流程:
5.1 采集图片
由于没有现成的仰卧起坐数据集,只能自己动手,丰衣足食。好在对于仰卧起坐这样常规的运动,网上还是有很多相关资源的。这里我采用下载视频和图片两种方式。先从网上搜索“仰卧起坐”的视频,下载了10个左右的视频片段,然后通过抽帧的方式,从每个视频中抽取一部分帧作为训练用的数据。如下图所示为从视频中抽取的关键帧。
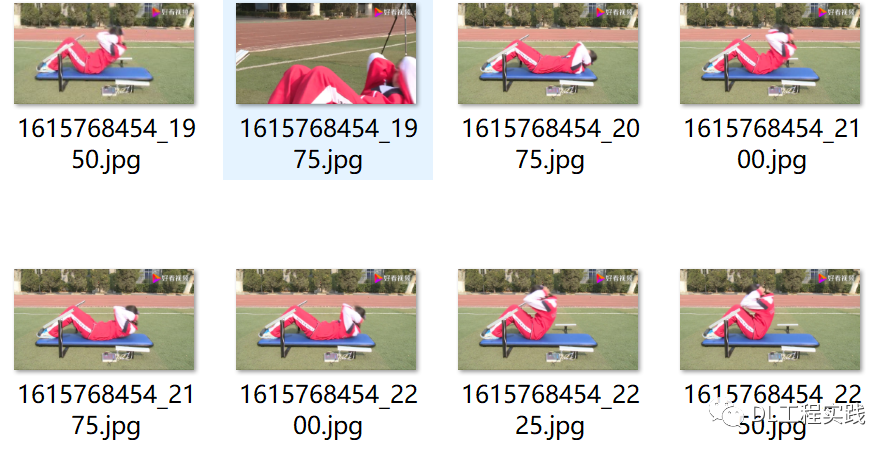
仅仅使用视频中抽取的帧会有一个比较严重的问题,就是背景过于单一,很容易造成过拟合。于是我从网上进行图片搜索,得到一分部背景较为丰富的图片,如下图所示:

5.2 标注图片
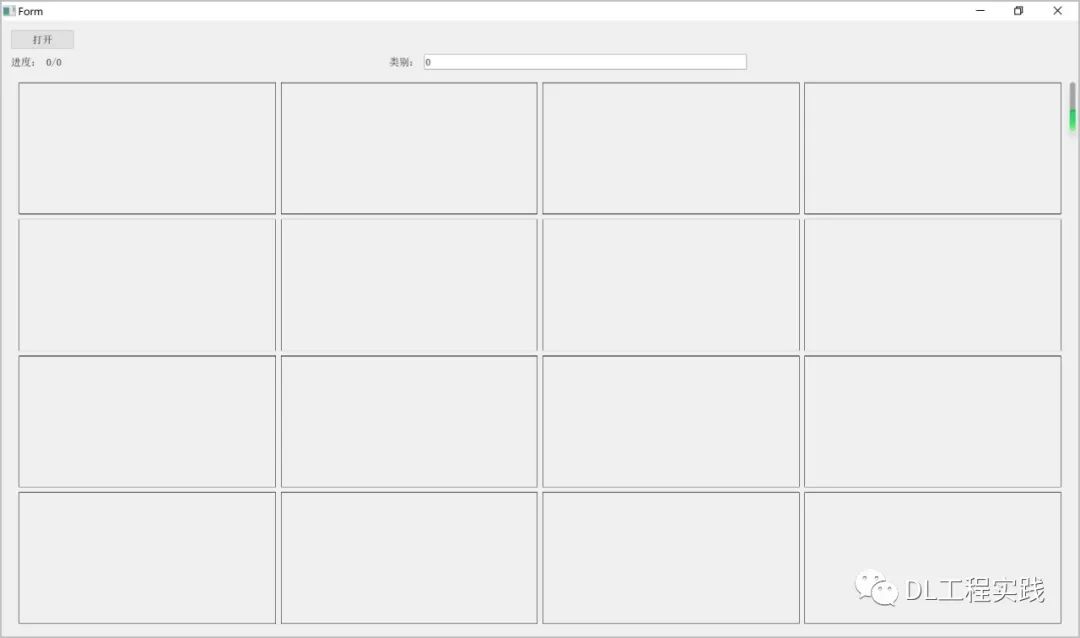
收集完数据,就是进行标注了,虽然已经有一些现成的开源标注工具,但是我用的不顺手,因此自己开发了一款关键点标注工具,就是上面开源的LabelTool,毕竟自己开发的,用着顺手。注意该工具在win10/python 3.6环境下做过测试,其他环境暂时没有测试。使用命令python main_widget.py打开界面。初始界面非常简洁,通过“打开”按钮来打开收集好的仰卧起坐图片。
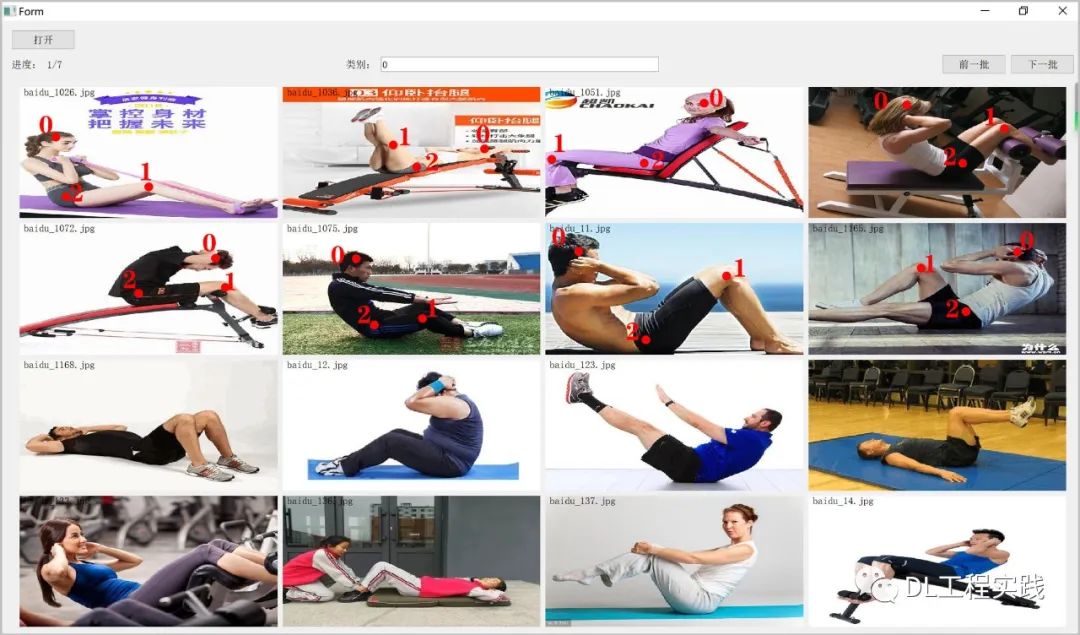
在类别中使用0表示标注的是头部,1表示标注的是膝盖,2表示标注的是胯部(由于我们需要在手机上识别仰卧起坐,需要尽可能的减少计算量,姿态估计一般会预测全身很多的关键点,但是对于仰卧起坐,只要能准确的预测头部,膝盖和胯部,就能较好的进行仰卧起坐的动作识别,因此这里只需要标注三个点)。单击鼠标左键进行标注,右键取消上一次标注。不得不说,用python+qt开发一些基于UI的工具非常方便!与C++相比,解放了太多的生产力!
标注完图片之后,会在图片目录下面生成一个标签文件label.txt,里面的内容如下:

5.3 算法原理
我先简单的介绍一下仰卧起坐的算法原理。在姿态估计(关键点检测)领域,一般很少采用回归的方式来预测关键点位置,取而代之的是采用heatmap输出关键点的位置。这和anchor free的目标检测中的centness之类的做法差不多,即通过查找heatmap中响应值最大的点来确定关键点的坐标。如下图所示(只显示部分heatmap):
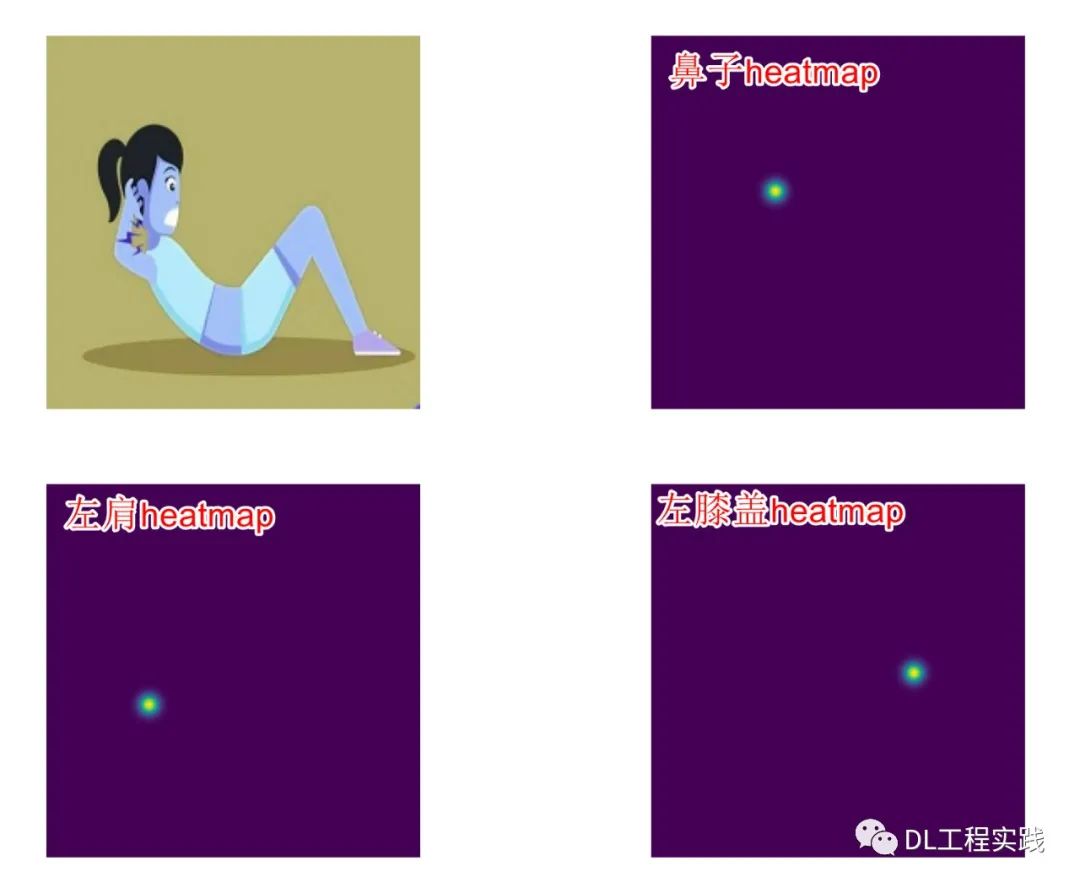
思考了一下原因,直接回归坐标,通常会将最后的featuremap下采样到很小,这样才能够实现全局的回归,但是关键点预测这种任务对位置信息非常敏感,过小的特征会极大的丢失空间信息,因而导致预测位置非常不准。而heatmap方式一般要求最后的特征图比较大,通常是输入图片的1/2或者1/4,那么就非常适合做一些空间相关的任务。其实如果人为的将特征图压缩的很小,heatmap的方式也一样不太准。有了上面的思考,便有了最终的方案,就是将shufflenet最后输出的7*7的特征图进行上采样到3*56*56大小(考虑到最终的应用以及场景,56*56足够实现仰卧起坐动作的识别),3表示的是3个关键点。然后输出的特征经过sigmoid激活之后便得到了3*56*56的heatmaps。这里多提两点,就是heatmap标签的设计和loss的平衡问题。先说说标签的设计,如果只是简单的将标签转化成一个one_hot的heatmap,效果不会太好。因为标签点附件的点实际上对于网络来说提取的特征是类似的,那么如果强行把不是标签附近的点设置为0,表现不会很好,一般会用高斯分布来制作标签heatmap,如下图所示:
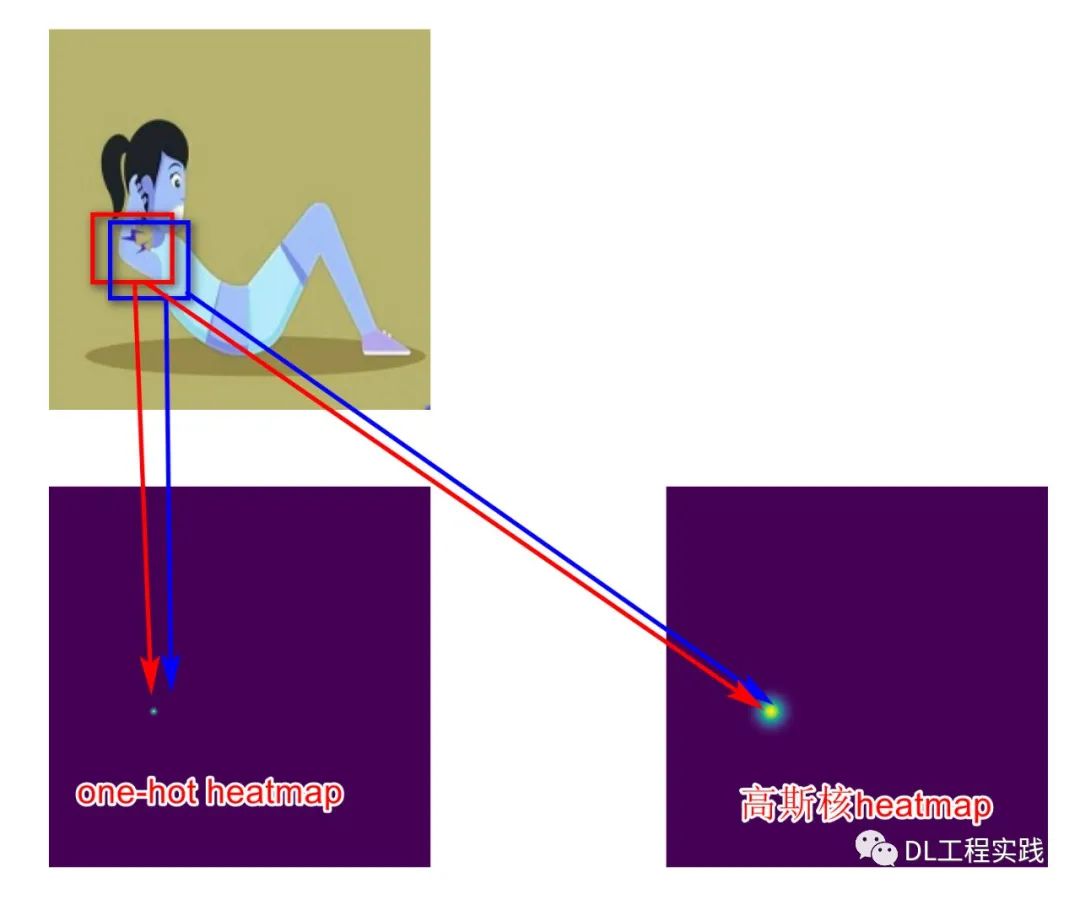
另外要说的就是loss的平衡了,上面的标签heatmap大家也看到了,无论是one-hot的heatmap还是高斯分布的heatmap,大部分的点都是负样本点,直接使用MSE而不加以区分,网络基本上会训练出一个输出全是0的heatmap。主要原因就是训练的梯度被负样本压制,正样本的梯度实在太小。因此需要做一个分区。我这里把正负样本的比重设置为10:1。
5.3 Trainer训练工具
Trainer工具主要包括四个部分:
cfg:配置文件目录
data:数据读取目录
DLEngine:训练引擎
models:网络模型目录
首先在models下的keypoint目录下,我实现了上述讨论的基于shufflenet的关键点检测网络,ShuffleNetV2HeatMap,然后在data目录下实现了读取LabelTool标注的标签文件的数据集读取工具:person_keypoint_txt.py。最后在配置文件夹cfgs下的key_point目录下实现了针对该项目的配置文件:keypoint_shufflenetv2_heatmap_224_1.0_3kps.py,里面包含的主要字段如下:




启动训练前,将train.py文件中的CFG_FILE修改成上述配置文件即可:
CFG_FILE='cfgs/key_point/keypoint_shufflenetv2_heatmap_224_1.0_3kps.py'。使用命令 python train.py 启动训练。
5.4 转换模型
在Trainer中完成训练之后,会在save目录下面生成相应的模型文件。但是这些pytorch的模型无法直接部署到手机中运行,需要使用相应的推理库。目前开源的推理库有很多,例如mnn,ncnn,tnn等。这里我选择使用ncnn,因为ncnn开源的早,使用的人多,网络支持,硬件支持都还不错,关键是很多问题都能搜索到别人的经验,可以少走很多弯路。但是遗憾的是ncnn并不支持直接将pytorch模型导入,需要先转换成onnx格式,然后再将onnx格式导入到ncnn中。另外注意一点,将pytroch的模型到onnx之后有许多胶水op,这在ncnn中是不支持的,需要使用另外一个开源工具:onnx-simplifier对onnx模型进行剪裁,然后再导入到ncnn中。因此整个过程还有些许繁琐,为此,我在Trainer工程中,编写了export_ncnn.py 脚本,可以一键将训练出来的pytorch模型转换成ncnn模型。转换成功后,会在save目录下的pytorch模型文件夹下生成三个ncnn相关的文件:model.param; model.bin以及 ncnn.cfg。
5.5 APP开发
android的APP开发主要Activity类,两个SurfaceView类,一个Alg类,一个Camera类组成。Alg类主要负责调用算法进行推理,并返回结果。这里实际上是调用的NCNN库的推理功能。Camera类主要负责摄像头的打开和关闭,以及进行预览回调。第一个SurfaceView(DisplayView)主要用于摄像头预览的展示。第二个SurfaceView(CustomView)主要用于绘制一些关键点信息,计数统计信息等。Activity就是最上层的一个管理类,负责管理整个APP,包括创建按钮,创建SurfaceView,创建Alg类,创建Camera类等。
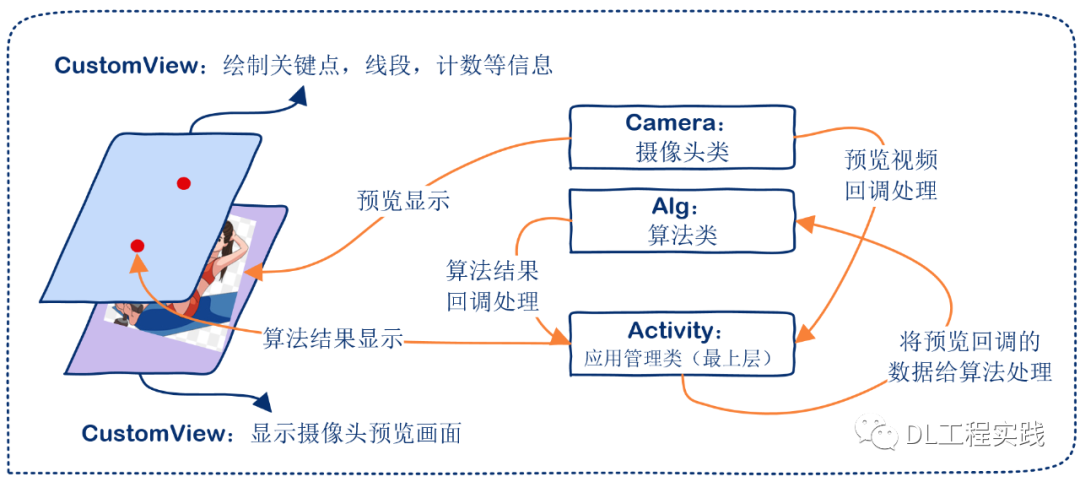
具体的代码逻辑可以查看SiteUpAndroid源码。
项目开源地址 https://github.com/DL-Practise/OpenSitUp
@end
长按扫描下方二维码添加小助手。
可以一起讨论遇到的问题
声明:转载请说明出处
扫描下方二维码关注【集智书童】公众号,获取更多实践项目源码和论文解读,非常期待你我的相遇,让我们以梦为马,砥砺前行!
