字节最新文本生成图像AI,训练集里居然没有一张带文字描述的图片?!

来源:本文经AI新媒体量子位(公众号 ID: QbitAI)授权转载,转载请联系出处 本文约1300字,建议阅读9分钟
本文介绍了字节的最新text2image模型,实现了文本-图像都不使用,也可以让AI学会看文作图。

不用文字训练也能根据文本生成图像
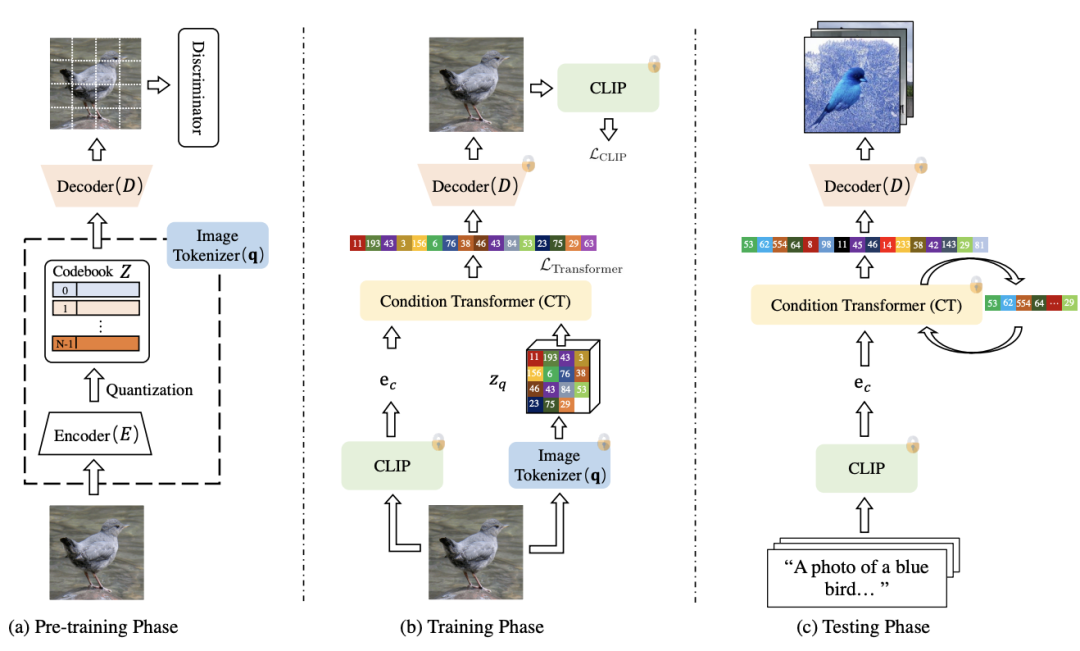
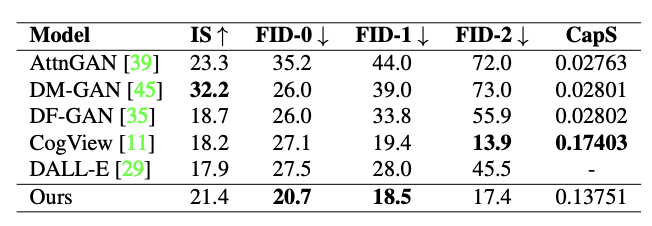
性能与清华CogView相当


作者介绍

论文地址:
https://arxiv.org/abs/2203.00386
编辑:王菁
评论
 下载APP
下载APP来源:本文经AI新媒体量子位(公众号 ID: QbitAI)授权转载,转载请联系出处 本文约1300字,建议阅读9分钟
本文介绍了字节的最新text2image模型,实现了文本-图像都不使用,也可以让AI学会看文作图。
论文地址:
https://arxiv.org/abs/2203.00386
编辑:王菁