
字节最新文本生成图像AI,训练集里居然没有一张带文字描述的图片?!
点击上方“视学算法”,选择加"星标"或“置顶”
重磅干货,第一时间送达
丰色 发自 凹非寺
量子位 | 公众号 QbitAI
一个文本-图像对数据都不用,也能让AI学会看文作图?
来自字节的最新text2image模型,就做到了。
实验数据显示,它的效果比VQGAN-CLIP要真实,尤其是泛化能力还比不少用大量文本-图像数据对训练出来的模型要好很多。
嗯?不给文字注释AI怎么知道每一张图片代表什么?
这个模型到底咋训练出来的?

不用文字训练也能根据文本生成图像
首先,之所以选择这样一种方式,作者表示,是因为收集大量带文字的图像数据集的成本太高了。
而一旦摆脱对文本-图像对数据的需求,我们就可以直接用大型无文本图像数据集 (比如ImageNet)来训练强大且通用的text2image生成器。
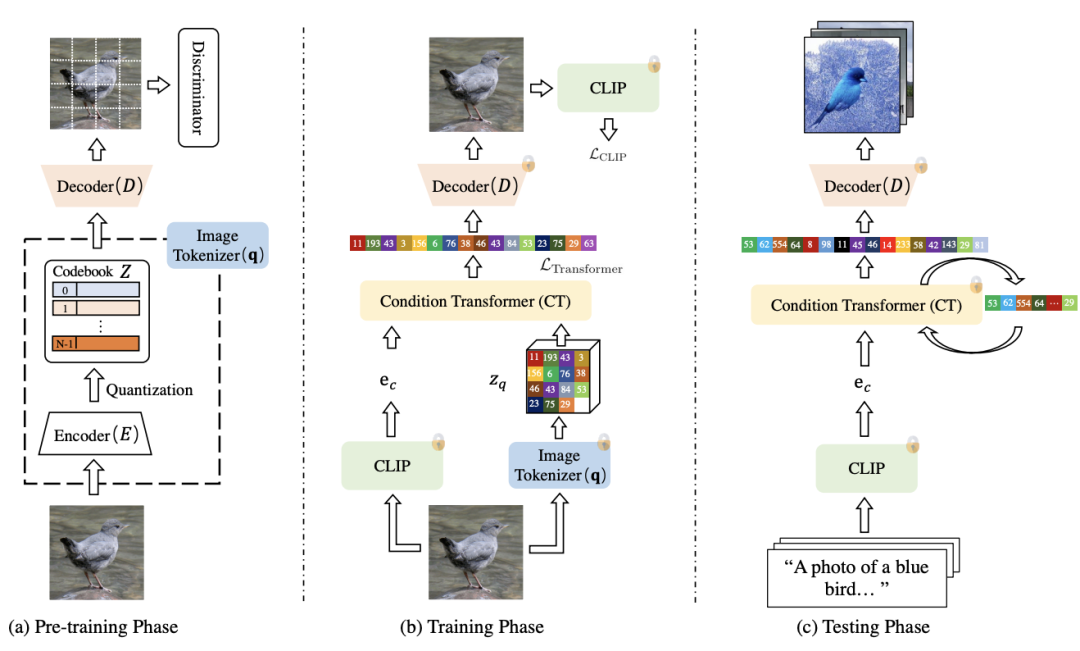
字节实现的这个模型叫做CLIP-GEN,它具体是怎么操作的?
一共分三大步。
首先,对于一幅没有文本标签的图像,使用CLIP的图像编码器,在语言-视觉(language-vision)联合嵌入空间(embedding space)中提取图像的embedding。
接着,将图像转换为VQGAN码本空间(codebook space)中的一系列离散标记(token)。
也就是将图像以与自然语言相同的方式进行表示,方便后续使用Transformer进行处理。
其中,充当image tokenizer角色的VQGAN模型,可以使用手里的无标记图像数据集进行训练。
最后,再训练一个自回归Transformer,用它来将图像标记从Transformer的语言-视觉统一表示中映射出对应图像。
经过这样的训练后,面对一串文本描述,Transformer就可以根据从CLIP的文本编码器中提取的文本嵌入(text embedding)生成对应的图像标记(image tokens)了。
那这样全程没有文本数据参与训练的文本-图像生成器,效果到底行不行?
性能与清华CogView相当
作者分别在ImageNe和MSCOCO数据集上对CLIP-GEN进行训练和评估。
首先,用MS-COCO验证集中的六个文本描述生成样本。
CLIP-GEN和其他通过大量文本-图像对训练的text2image生成模型的效果对比如下:

其中,VQGAN-CLIP的结果比较不真实,并且伴随严重的形状扭曲。
来自清华的CogView号称比DALL-E更优秀,在这里的实验中,它确实可以生成良好的图像结构,但在纹理细节上差点儿事儿。
DF-GAN可以生成具有丰富细节的合理图像,但也容易产生局部伪影。
作者认为,与这些对比模型相比,CLIP-GEN的图像细节更丰富,质量更高一些,比如它就很好地诠释了第二组文字中要求的“水中倒影”(不过不太能理解“三只毛绒熊“中的数字概念)。
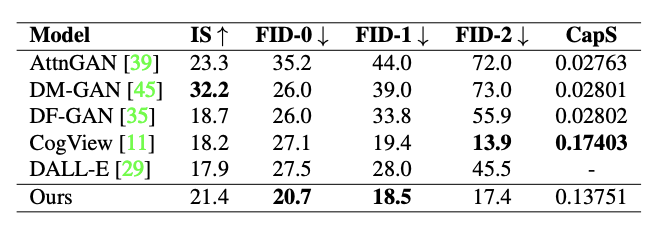
定量实验结果基本证明了这一结论:
CLIP-GEN拿到了最高的FID-0、FID-1分数;CapS得分(衡量输入文本和生成图像之间的语义相似性)除了比CogView低4%,比其他模型都高很多。
此外,作者还发现,CLIP-GEN的泛化能力似乎也不错。
在下面这组非常规的文字描述中,比如生成“一只会飞的企鹅”,“叼雪茄的狗”、“有脸和头发的柠檬”……CLIP-GEN基本都可以实现,别的模型却不太能理解。

作者介绍
本模型的五位作者全部来自字节。

一作Wang Zihao本科毕业于北京理工大学,博士毕业于UC伯克利,曾在谷歌担任3年软件开发工程师,现就职于TikTok。
通讯作者名叫易子立,本科毕业于南京大学,博士毕业于加拿大纽芬兰纪念大学,目前在字节担任人工智能专家(主要研究多模态、超分辨率、人脸特效),在此之前,他曾在华为工作。
论文地址:
https://arxiv.org/abs/2203.00386
— 完 —

点个在看 paper不断!