【爬虫实战】一起一步步分析亚马逊的反爬虫机制

事情是这样的
亚马逊是全球最大的购物平台
很多商品信息、用户评价等等都是最丰富的。
今天,手把手带大家,越过亚马逊的反爬虫机制
爬取你想要的商品、评论等等有用信息
反爬虫机制
但是,我们想用爬虫来爬取相关的数据信息时
像亚马逊、TBao、JD这些大型的购物商城
他们为了保护自己的数据信息,都是有一套完善的反爬虫机制的
先试试亚马逊的反爬机制
我们用不同的几个python爬虫模块,来一步步试探
最终,成功越过反爬机制。
一、urllib模块
代码如下:
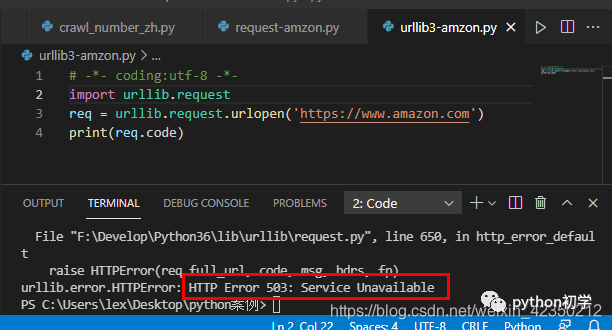
# -*- coding:utf-8 -*-import urllib.requestreq = urllib.request.urlopen('https://www.amazon.com')print(req.code)
返回结果:状态码:503。
分析:亚马逊将你的请求,识别为了爬虫,拒绝提供服务。
本着科学严谨的态度,我们拿万人上的百度试一下。
返回结果:状态码 200
分析:正常访问
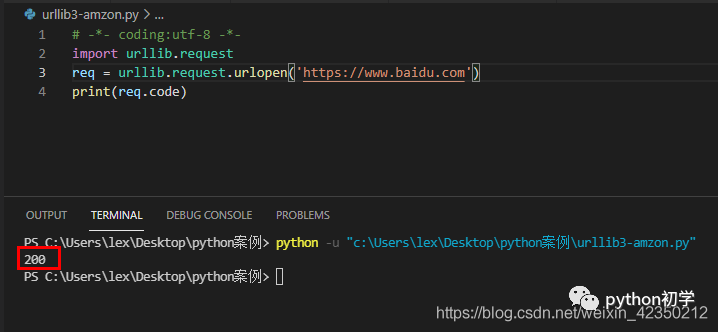
那说明,urllib模块的请求,被亚马逊识别为爬虫,并拒绝提供服务
二、requests模块
1、requests直接爬虫访问
效果如下 ↓ ↓ ↓
代码如下 ↓ ↓ ↓
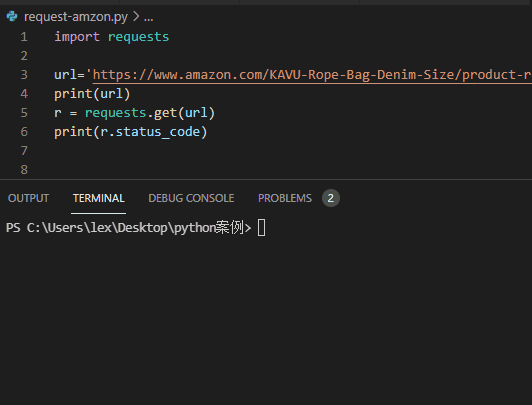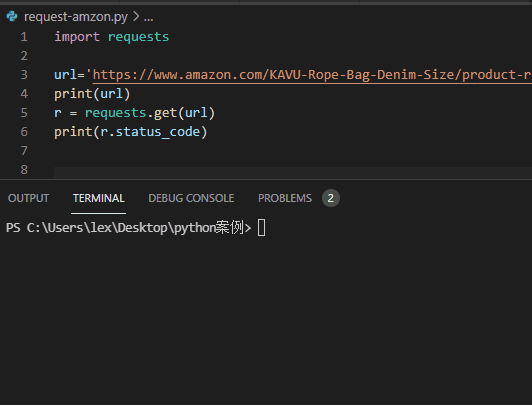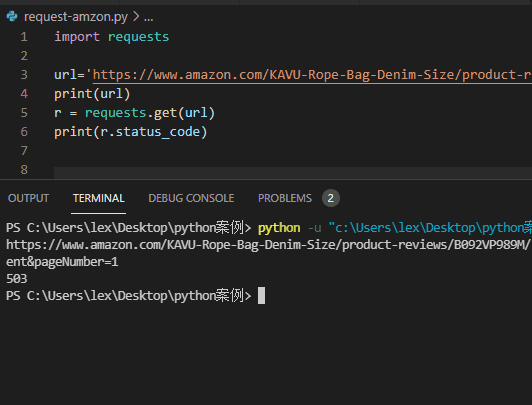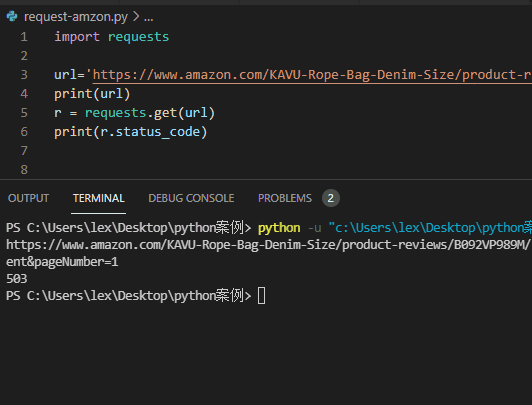
import requestsurl='https://www.amazon.com/KAVU-Rope-Bag-Denim-Size/product-reviews/xxxxxx'r = requests.get(url)print(r.status_code)
返回结果:状态码:503。
分析:亚马逊同样拒绝了requsets模块的请求
将其识别为了爬虫,拒绝提供服务。
2、我们给requests加上cookie
加上请求cookie等相关信息
效果如下 ↓ ↓ ↓
代码如下 ↓ ↓ ↓
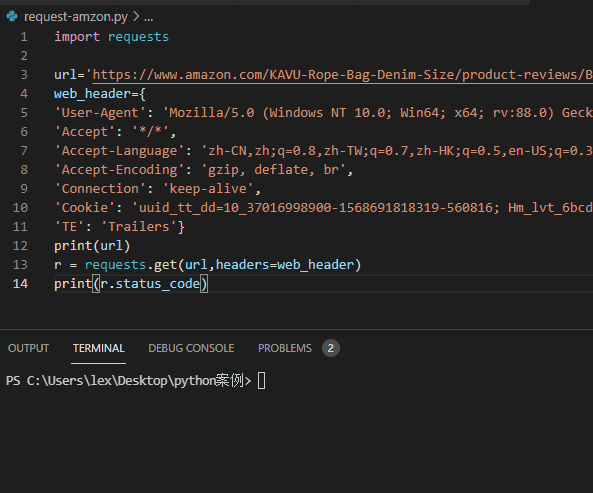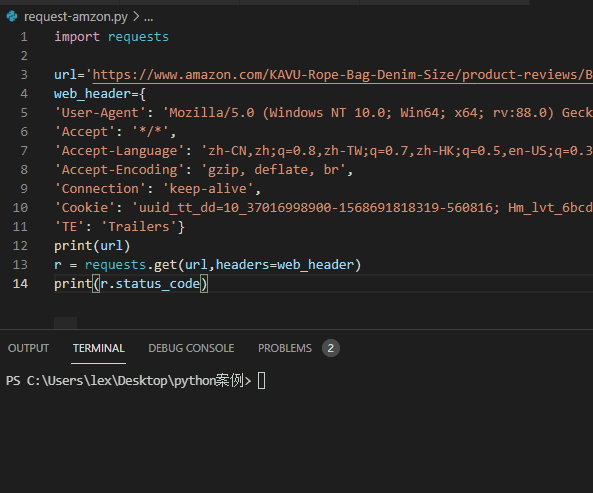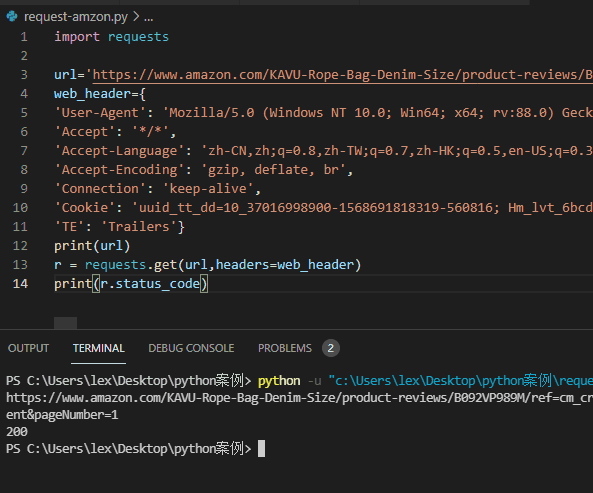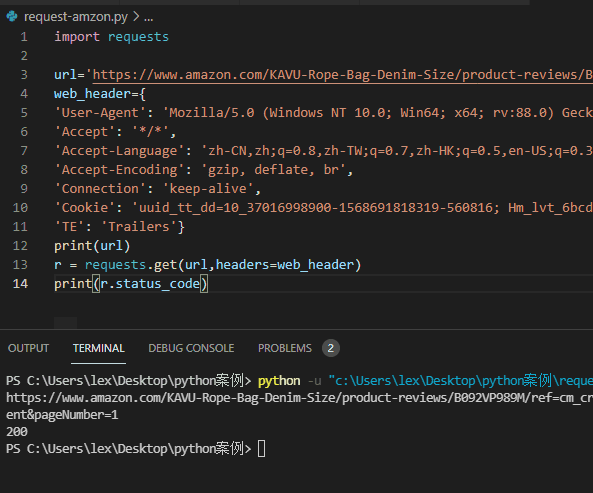
import requestsurl='https://www.amazon.com/KAVU-Rope-Bag-Denim-Size/product-reviews/xxxxxxx'web_header={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:88.0) Gecko/20100101 Firefox/88.0','Accept': '*/*','Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2','Accept-Encoding': 'gzip, deflate, br','Connection': 'keep-alive','Cookie': '你的cookie值','TE': 'Trailers'}r = requests.get(url,headers=web_header)print(r.status_code)
返回结果:状态码:200
分析:返回状态码是200了,正常了,有点爬虫那味了。
3、检查返回页面
我们通过requests+cookie的方法,得到的状态码为200
目前至少被亚马逊的服务器正常提供服务了
我们将爬取的页面写入文本中,通过浏览器打开。
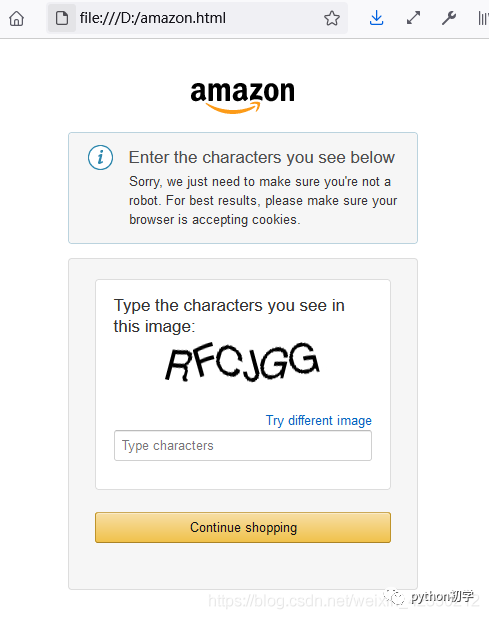
我踏马...返回状态是正常了,但返回的是一个反爬虫的验证码页面。
还是 被亚马逊给挡住了。
三、selenium自动化模块
相关selenium模块的安装
pip install selenium代码中引入selenium,并设置相关参数
import osfrom requests.api import optionsfrom selenium import webdriverfrom selenium.webdriver.chrome.options import Options#selenium配置参数options = Options()#配置无头参数,即不打开浏览器options.add_argument('--headless')#配置Chrome浏览器的selenium驱动chromedriver="C:/Users/pacer/AppData/Local/Google/Chrome/Application/chromedriver.exe"os.environ["webdriver.chrome.driver"] = chromedriver#将参数设置+浏览器驱动组合browser = webdriver.Chrome(chromedriver,chrome_options=options)
测试访问
url = "https://www.amazon.com"print(url)#通过selenium来访问亚马逊browser.get(url)
返回结果:状态码:200
分析:返回状态码是200了,访问状态正常,我们再看看爬到的网页信息。
将网页源码保存到本地
#将爬取到的网页信息,写入到本地文件fw=open('E:/amzon.html','w',encoding='utf-8')fw.write(str(browser.page_source))browser.close()fw.close()
打开我们爬取的本地文件,查看 ,
我们已经成功越过了反爬虫机制,进入到了Amazon的首页

结局
通过selenium模块,我们可以成功的越过
亚马逊的反爬虫机制。
来源:https://juejin.cn/post/6974300157126901790
声明:文章著作权归作者所有,如有侵权,请联系小编删除
搜索下方加老师微信
老师微信号:XTUOL1988【切记备注:学习Python】
领取Python web开发,Python爬虫,Python数据分析,人工智能等精品学习课程。带你从零基础系统性的学好Python!
*声明:本文于网络整理,版权归原作者所有,如来源信息有误或侵犯权益,请联系我们删除或授权