
Python爬虫开发:反爬虫措施以及爬虫编写注意事项
↑ 关注 + 星标 ,每天学Python新技能
后台回复【大礼包】送你Python自学大礼包
反爬虫的几重措施
1.IP限制
如果是个人编写的爬虫,IP可能是固定的,那么发现某个IP请求过于频繁并且短时间内访问大量的页面,有爬虫的嫌疑,作为网站的管理或者运维人员,你可能就得想办法禁止这个IP地址访问你的网页了。那么也就是说这个IP发出的请求在短时间内不能再访问你的网页了,也就暂时挡住了爬虫。
2.User-Agent
User-Agent是用户访问网站时候的浏览器的标识
下面我列出了常见的几种正常的系统的User-Agent大家可以参考一下,
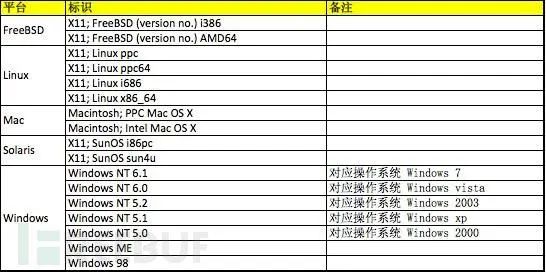
并且在实际发生的时候,根据浏览器的不同,还有各种其他的User-Agent,我举几个例子方便大家理解:
safari 5.1 – MAC
User-Agent:Mozilla/5.0 (Macintosh; U; IntelMac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1Safari/534.50
Firefox 4.0.1 – MAC
User-Agent: Mozilla/5.0 (Macintosh; IntelMac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1
Firefox 4.0.1 – Windows
User-Agent:Mozilla/5.0 (Windows NT 6.1;rv:2.0.1) Gecko/20100101 Firefox/4.0.1
同样的也有很多的合法的User-Agent,只要用户访问不是正常的User-Agent极有可能是爬虫再访问,这样你就可以针对用户的User-Agent进行限制了。
3、 验证码反爬虫
这个办法也是相当古老并且相当的有效果,如果一个爬虫要解释一个验证码中的内容,这在以前通过简单的图像识别是可以完成的,但是就现在来讲,验证码的干扰线,噪点都很多,甚至还出现了人类都难以认识的验证码(某二三零六)。

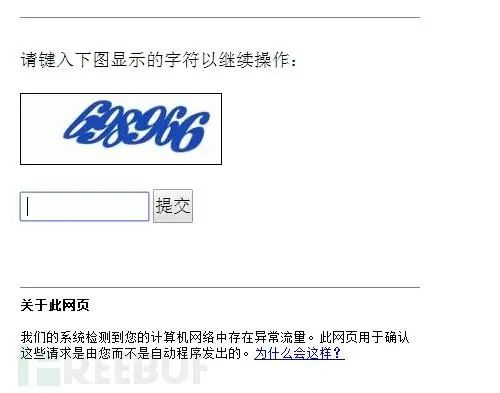
4.Ajax异步加载
5.Noscript标签的使用
<noscript>标签是在浏览器(或者用户浏览标识),没有启动脚本支持的情况下触发的标签,在低级爬虫中,基本都没有配置js引擎,通常这种方式和Ajax异步加载同时使用。用于保护自己不想让爬虫接触的信息。
6.Cookie限制
第一次打开网页会生成一个随机cookie,如果再次打开网页这个cookie不存在,那么再次设置,第三次打开仍然不存在,这就非常有可能是爬虫在工作了。很简单,在三番屡次没有带有该带的cookie,就禁止访问。
爬虫编写注意事项
在这一部分,笔者希望就自己的经验给大家编写爬虫提供比较可行的建议,也为大家提一个醒:
1.道德问题,是否遵守robots协议;
2.小心不要出现卡死在死循环中,尽量使用urlparser去解析分离url决定如何处理,如果简单的想当然的分析url很容易出现死循环的问题;
3.单页面响应超时设置,默认是200秒,建议调短,在网络允许的条件下,找到一个平衡点,避免所有的爬虫线程都在等待200,结果出现效率降低;
4.高效准确的判重模式,如果判重出现问题,就会造成访问大量已经访问过的页面浪费时间;
5.可以采用先下载,后分析的方法,加快爬虫速度;
6.在异步编程的时候要注意资源死锁问题;
7.定位元素要精准(xpath)尽量避免dirty data。
希望大家提出自己的意见,本系列大多数时间都在从微观的角度讲爬虫各个部件的解决方案。
