
Python爬虫:两个爬虫实战教你存储数据
今天是大年三十,先预祝大家新年快乐~文末有红包福利哦~

实战一:中国大学排名
前言
由于上一篇文章中教会了大家如何存储数据,但是由于篇幅过大,就没有加入实战篇。想必大家也等着急了吧,所以今天就为大家带来两篇实战内容,希望可以帮助到各位更好的认识到爬虫与MySQL数据库结合的知识。
每年的6月都是高考的大日子,所有的学子都为自己的目标大学努力着,拼搏着,所以今天的第一篇实战就是为你们带来2020中国大学的排名情况,让各位小伙伴知道你自己的大学排名大概是多少。
需求分析与功能实现
爬取的网址如下:
https://www.shanghairanking.cn/rankings/bcur/202011
打开网站之后,你会看到映入眼帘的就是中国大学的排名情况,让我们看看我们需要的信息有哪些吧。
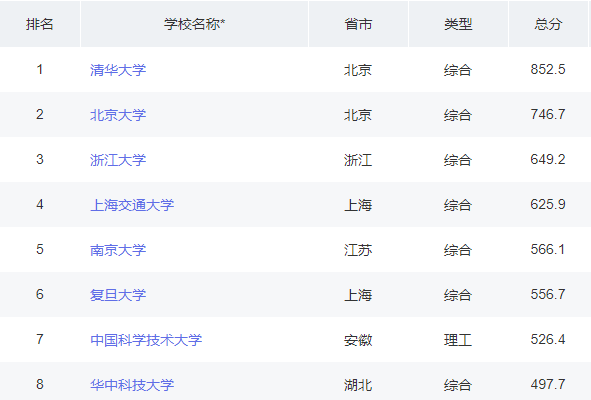
如上图所示,我们需要获取到学校的排名、学校的名称、学校所在的省份、该学校所属的类型以及大学的总分。
这些数据都保存在表格当中,因此我选用xpath提取表格数据。
具体代码如下所示:
# 解析网页提取信息
def parse_html(self, html):
rank_ids = []
university_names = []
provices = []
types = []
all_sorces = []
html = etree.HTML(html)
tr_lists = html.xpath('//table/tbody/tr')
for tr in tr_lists:
# 大学排名
rank_id = tr.xpath('./td[1]/text()')[0].split()[0]
rank_ids.append(rank_id)
# 大学名称
university_name = tr.xpath('./td[2]/a/text()')[0]
university_names.append(university_name)
# 省市
province = tr.xpath('./td[3]/text()')[0].split()[0]
provices.append(province)
# 类型
type = tr.xpath('./td[4]/text()')[0].split()[0]
types.append(type)
# 总分
all_source = tr.xpath('./td[5]/text()')[0].split()[0]
all_sorces.append(all_source)
results = zip(rank_ids, university_names, provices, types, all_sorces)
return results
在上面的代码中,通过xpath语法将所有需要的数据提取出来,最后通过zip函数将对象中对应的元素打包成一个元组,然后返回这些元组组成的列表。
运行结果如下所示:
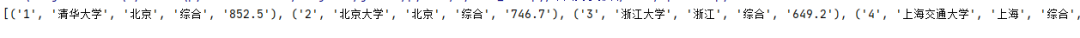
通过上面的代码我们已经成功的将需要的数据解析出来了,那么接下来我们需要完成的事情就是将获取下来的数据保存到数据库中,因此在这里需要创建三个函数。具体代码如下所示:
创建数据库
def create_db(self):
host = 'localhost'
user = 'root'
password = '698350As?'
port = 3306
db = pymysql.connect(host=host, user=user, password=password, port=port)
cursor = db.cursor()
sql = 'create database unversityrank default character set utf8'
cursor.execute(sql)
db.close()
print('创建成功')
在上面的这段代码中可以看到我创建了一个名为unversityrank的数据库。
创建表格
def create_tables(self):
host = 'localhost'
user = 'root'
password = '698350As?'
port = 3306
db = 'unversityrank'
db = pymysql.connect(host=host, user=user, password=password, port=port, db=db)
cursor = db.cursor()
sql = 'create table if not exists rank4 (id int auto_increment primary key,rankid varchar(255) not null, name varchar(255) not null, province varchar(255) not null, type varchar(255) not null, source varchar(255) not null)'
cursor.execute(sql)
db.close()
print('创建成功')
在上面的这段代码中我成功在数据库unversityrank中创建了表格ranks,并为其创建了字段。
在这里需要注意的是,在这个表格中不能使用排名这个字段作为主键,因为不同的学校可能出现相同的排名。
插入数据
def save_data(self, results):
host = 'localhost'
user = 'root'
password = '698350As?'
port = 3306
db = 'unversityrank'
db = pymysql.connect(host=host, user=user, password=password, port=port, db=db)
cursor = db.cursor()
sql = 'insert into rank4(rankid, name, province, type, source) values(%s,%s,%s,%s,%s)'
for result in results:
print(result)
try:
cursor.execute(sql, result)
db.commit()
print('插入成功')
except:
db.rollback()
print('插入失败')
db.close()
至此,便完成了数据的获取及存储。
结果展示
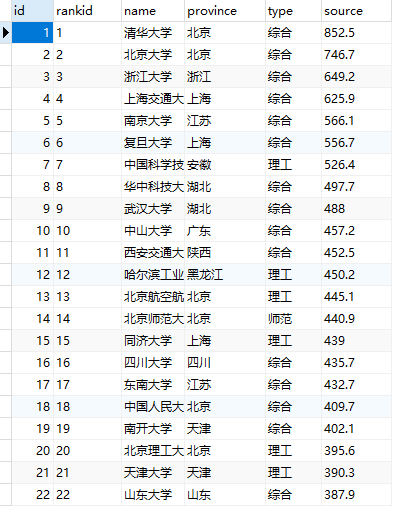
数据处理
爬取下来的数据,我们需要利用Python数据分析工具对爬取下来的数据进行简单的统计,我们先简单的看一下数据长什么样子。
host='localhost'
user='root'
password='密码?'
db = 'unversityrank'
sql = 'select * from rank4'
conn = pymysql.connect(host=host, user=user, password=password, db=db)
df = pd.read_sql(sql, conn)
df.head(10)
结果如下:

数据可视化操作
俗话说:“字不如表,表不如图”。爬取到的数据最终做可视化的呈现,才能够让大家对数据背后的规律有一个清晰的认识。接下来我从以下两个方面对数据进行分析。
1、全国各个省份大学数量的统计
2、全国所有大学的类型统计
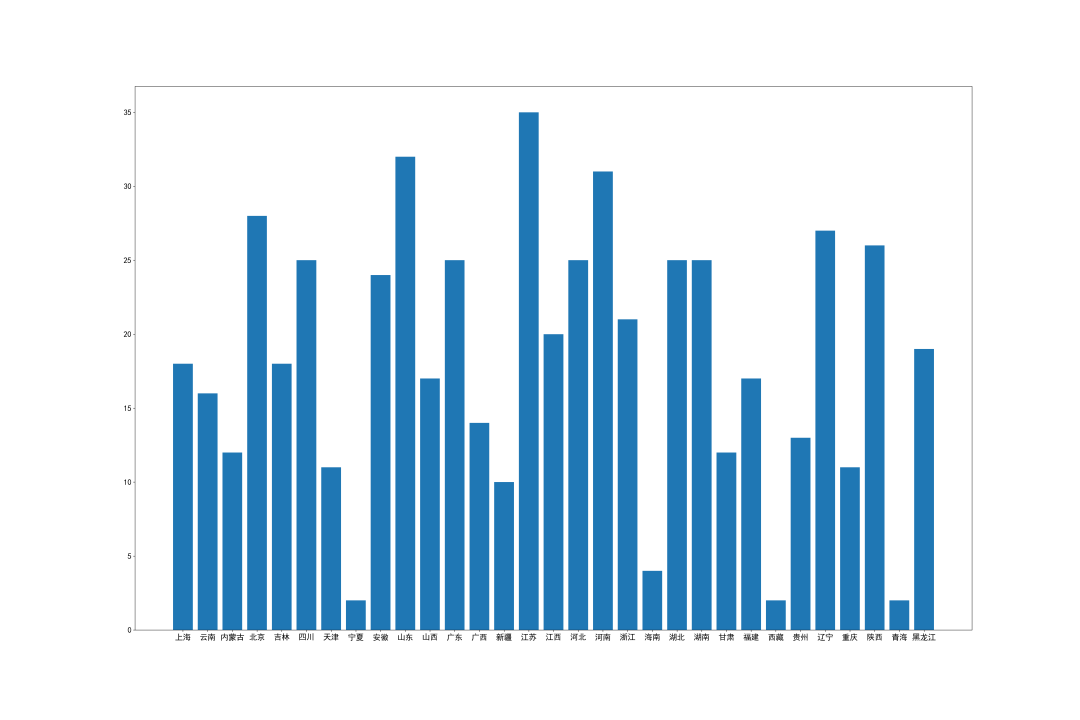
全国各个省份大学数量统计
从图中可以看到,宁夏、海南、青海和西藏这四个省区的大学数量是最少的,相反北京、江苏、山东河南的大学数量是最多的。
大学的建设最重要的还是要看当地的经济情况和交通情况,如果没有这两者作为基础的话,很难让一所大学举办起来。因此,从大学数量来看是可以看出每个省市的经济状况的。
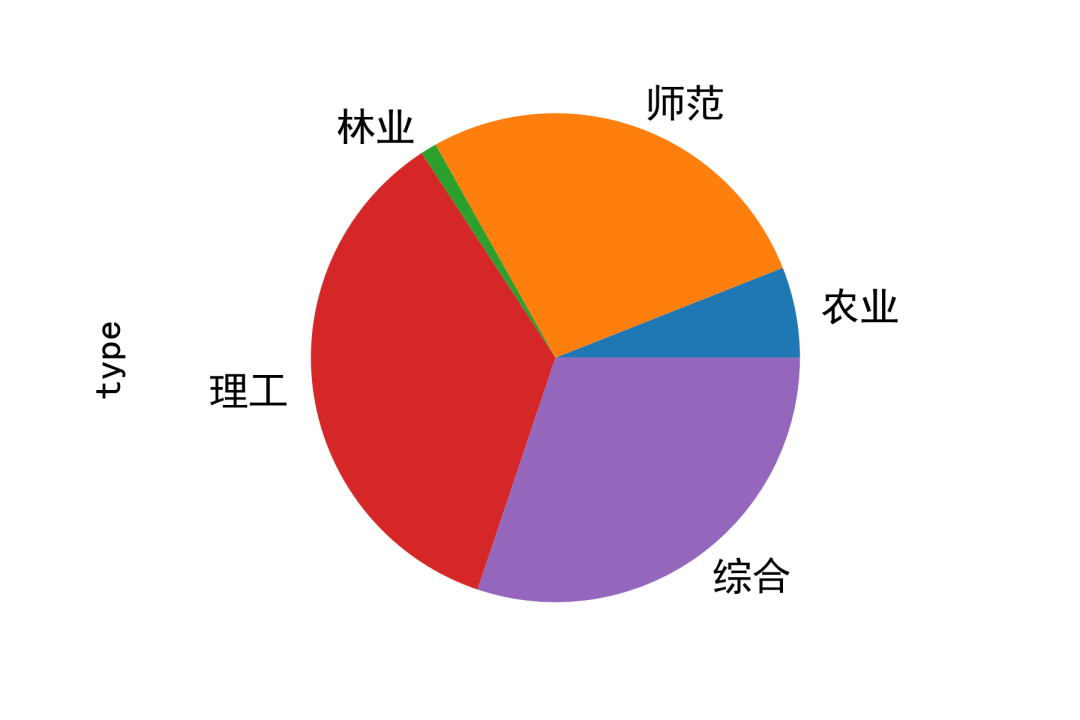
全国大学的类型统计
在我国的大学一共有5种类型:农业、师范、林业、理工、综合。
从图上大致可以看出理工类占比是最多的,紧接着就是综合类院校和师范类院校。
一个国家需要发展必须加强理工类学校的建设,培养更多的工科人才。
实战二:糗事百科
前言
现在娱乐类的视频充斥着我们的生活,大家也越来越喜欢在地铁、公交以及茶余饭后的时间刷视频了,那么今天我就拿糗事百科作为例子,提取里面段子的标题、好笑数和作者昵称并保存在csv文件当中。
需求分析与功能实现
网址如下:
https://www.qiushibaike.com/
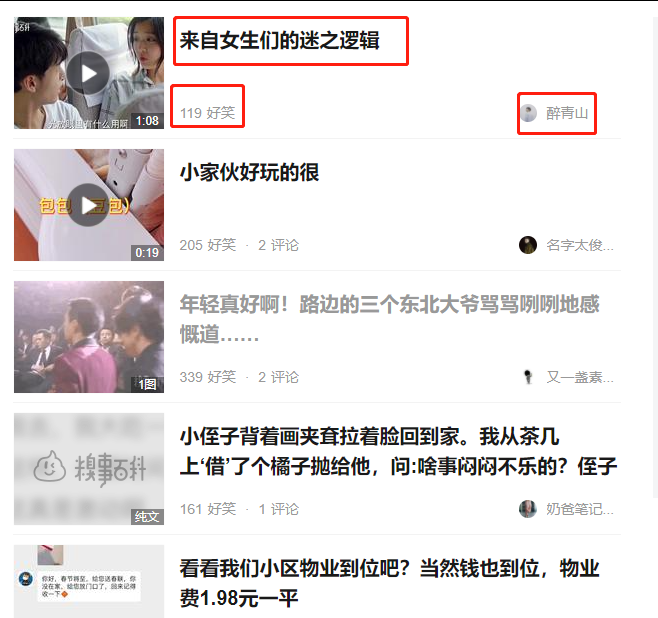
打开网站之后所呈现的页面如上图所示,需要提取的信息已经框起来了。
看到这样的网页布局相信很多小伙伴都知道,每一个段子都放在相同的类的div里面,因此在这里我选用正则表达式来提取数据。
提取数据
核心代码如下所示:
def parse_html(self,html):
pattern_title = re.compile('.*?(.*?).*? title = re.findall(pattern_title, html)
pattern_funny = re.compile('
funny = [funny + '好笑' for funny in re.findall(pattern_funny, html)]
pattern_author = re.compile( '
author = re.findall(pattern_author, html)
datas = [list(data) for data in zip(title, funny, author)]
return datas
在这里需要要求各位小伙伴具有正则表达式的基础,如果看不懂的话可以参考我前面写的文章。
关于翻页
# 第二页
https://www.qiushibaike.com/8hr/page/2/
# 第三页
https://www.qiushibaike.com/8hr/page/3/
看到上面的内容,想必大家已经非常明白,翻页之后URL的变化规律了吧。
保存数据
这次我们是将提取到的数据保存到csv文件里面,因此在开始之前先要导入csv模块.
import csv
保存数据的核心代码如下所示:
for page in range(1, 14):
url = f'https://www.qiushibaike.com/8hr/page/{page}/'
html = qiushi.get_html(url)
datas = qiushi.parse_html(html)
with open('data.csv', 'a', encoding='utf-8-sig') as f:
writer = csv.writer(f)
writer.writerow(['标题', '好笑', '作者'])
for data in datas:
writer.writerow(data)
通过上面的代码,可以看到我要获取的是1至13页的数据,并通过writerow()函数将每一行数据依次写入表格当中。
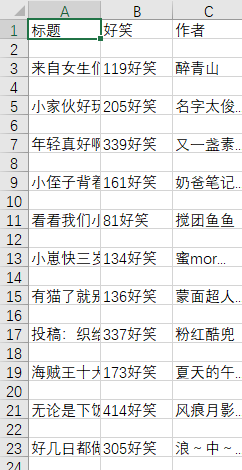
结果展示
最后
啃书君说:
文章的每一个字都是我用心敲出来的,只希望对得起每一位关注我的人。点个[在看]与【点赞】,让我知道,你们也在为自己的学习拼搏和努力。
路漫漫其修远兮,吾将上下而求索。
我是啃书君,一个专注于学习的人,你懂的越多,你不懂的越多。更多精彩内容,我们下期再见!
扫一扫下面的二维码,我会在今天发出100个金额随机的红包和若干python自选书籍,欢迎大家新的一年一起学习进步~
“扫一扫加我”