
计算机视觉研究新方向:自监督表示学习总结(建议收藏)
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

随着深度模型的兴起,基于监督的图像特征提取方式已经成为主流。然而这种方法需要大量的有标签数据,标注成本过高,在小样本数据集上面临着过拟合等问题。如何减少算法对高质量标签数据集的需求?如何利用大量的无标签图像数据进行特征提取?如何让模型提取的特征具有更加泛化的表达能力?
自监督表示学习算法应运而生。公众号上一篇自监督学习在计算机视觉中的应用为大家介绍了自监督学习的基本概念和一些应用,本篇文章参考Lilian Weng在其博客(lilianweng.github.io)中总结的自监督表示学习在图像,视频和控制领域的进展,将摘选其中图像和视频部分的内容进行分享。内容较多,建议先收藏~
自监督学习在图像任务上的特征表示
Distortion(扭曲,变形)
Exemplar-CNN(Dosovitskiy et al., 2015)《Discriminative Unsupervised Feature Learning with Exemplar Convolutional Neural Networks》用图像中的patch创建数据集:
1.从包含大量梯度的位置选取“exemplary” patch
2.每个补丁都通过应用各种随机转换(即、平移、旋转、缩放等)所有产生的失真补丁都被认为属于同一个代理类
3.pretext任务是区分一组代理类(每一个patch就是一个代理类)。
Rotation《Unsupervised Representation Learning by Predicting Image Rotations》提出了一种简单的图像旋转分类的代理任务。为了用不同的旋转来识别相同的图像,模型必须学会识别高层次的物体部分,如头、鼻子和眼睛,以及这些部分的相对位置,而不是局部模式。这个接口任务驱动模型以这种方式学习对象的语义概念。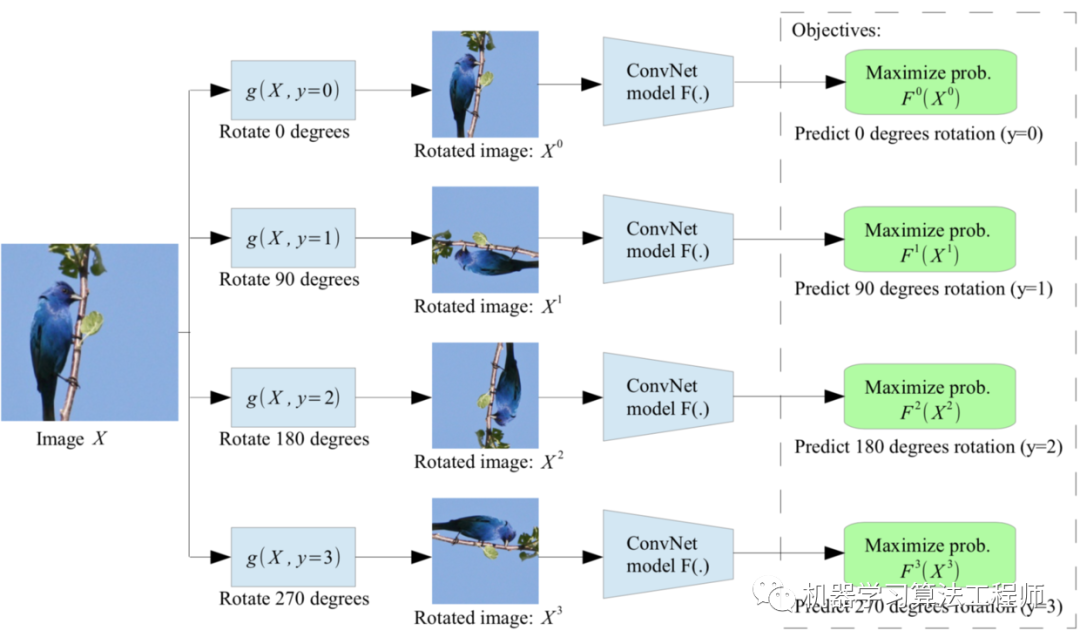
Patches
一幅图像中提取多个patch,并要求模型预测这些patch之间的关系
relative position《Unsupervised Visual Representation Learning by Context Prediction》让模型预测patch的相对位置
1.随机采样patch
2.考虑到第一个patch被放置在一个3x3的网格的中间,第二个patch被采样于它周围的8个相邻的位置
3.引入一些噪音
4.该模型被训练来预测第二个patch是从8个相邻位置中的哪一个中选择出来的,这是一个超过8类的分类问题(就是说看第二个patch的相对于第一个patch 的位置是1,还是2,3….8)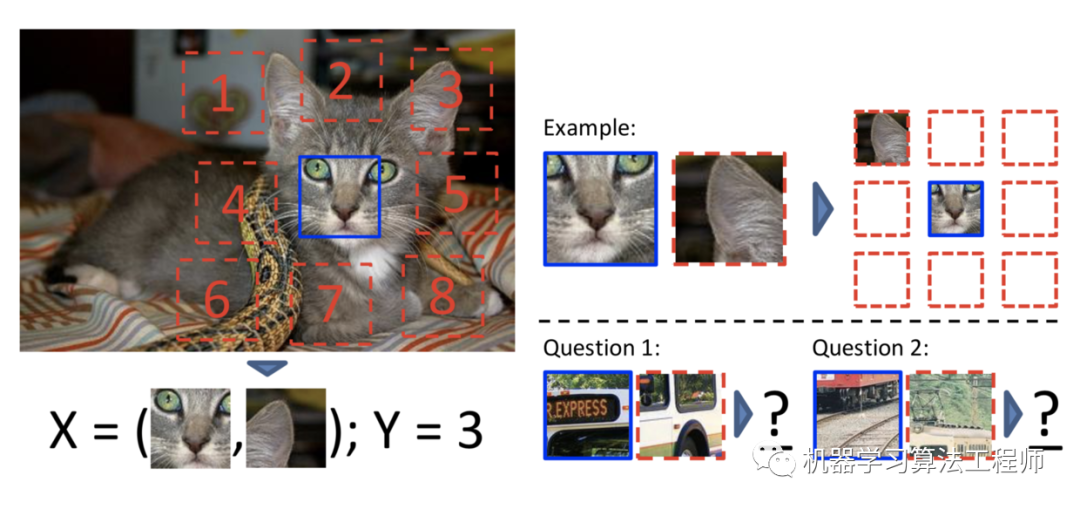
在《Unsupervised Learning of Visual Representations by Solving Jigsaw Puzzles》是将9个patch打乱然后让模型将其放回,实际实现时让模型预测其属于每个位置的概率,当然可以用GCN来加速训练。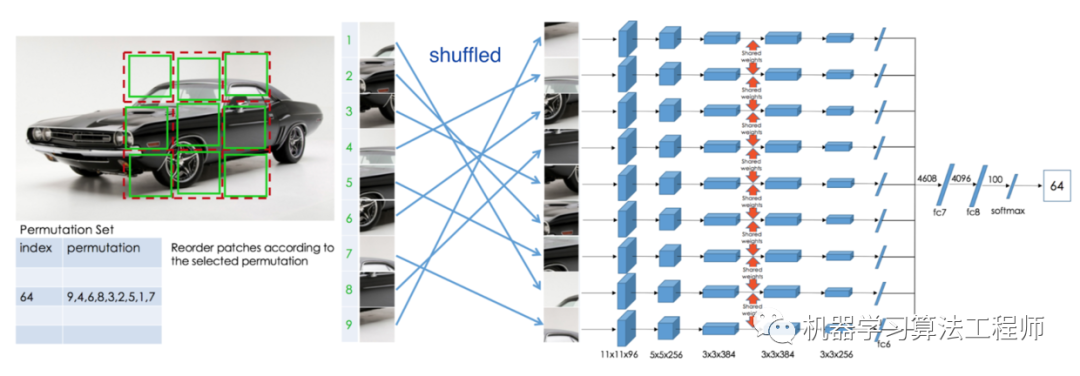
另一种想法是在论文《Representation Learning by Learning to Count》中提出的,将“feature”或“visual primitives”看作一个标量值属性,它可以在多个patch上求和,并在不同的patch之间进行比较。然后通过计数特征和简单的算法来定义patch之间的关系。
具体操作如下:
简单来说,就是对原始图像进行上采样和分块操作(2*2分块,得到4块),希望上采样后计算出的数目和原图计算出的数目一致,希望地砖分块操作后计算出的数目是原图计算出的数目的4倍。
Colorization
《Colorful Image Colorization》这篇论文为灰度图着色为彩色(在CIE LAB color space)思想也很简单。Momentum Contrast
《Momentum Contrast for Unsupervised Visual Representation Learning》提出一种新的无监督学习框架:动态字典查找。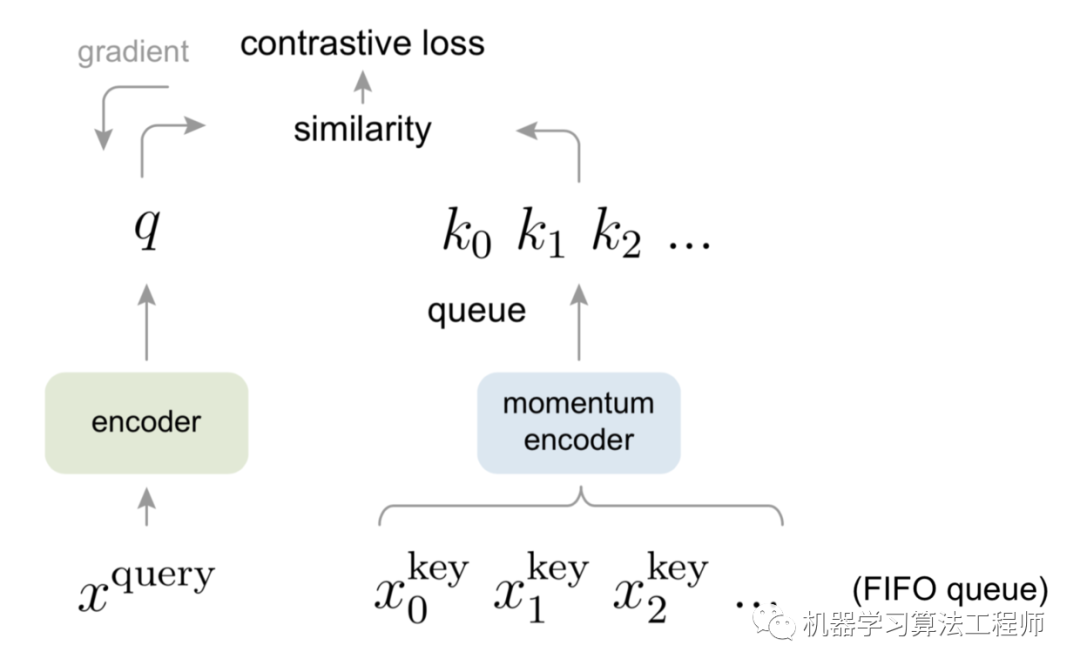
对quuery(x_q)通过encoder有一个对应的表达q,对于key(x_k)通过momentum encoder有一个对应的表达k,这些k构成一个list字典。假设字典中有一个k和q匹配。在论文中k是通过x的数据增强得来的。使用了InfoNEC contrastive loss 学习 1个positive和K个negative样本: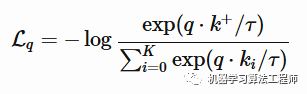

训练伪代码:
同样《A Simple Framework for Contrastive Learning of Visual Representations》中也提出了一个简单的框架用于对比学习。它通过潜在空间的对比损失,最大限度地提高相同样本的不同增强视图之间的一致性,从而学习视觉输入的表示。
训练伪代码:
《CURL: Contrastive Unsupervised Representations for Reinforcement Learning》借鉴了SimCLR的想法用于强化学习。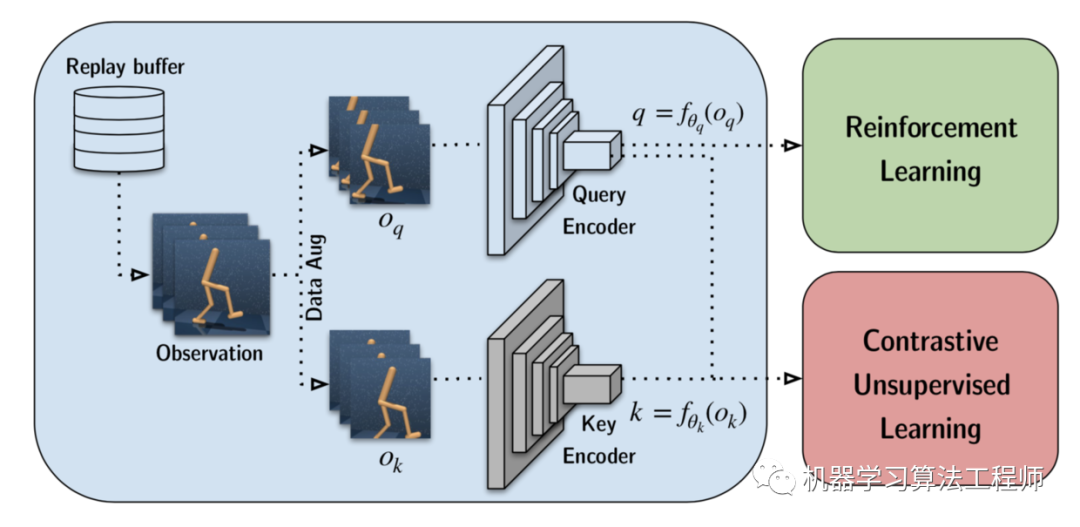
自监督学习在视频任务上的特征表示
Video-Based
视频中包含连续的,语义相近的帧,且框架的顺序描述了一定的推理规则和物理逻辑;例如,物体的运动应该是平稳的,重力是向下的。
一个常见的工作流程是,用无标签的视频对一个模型进行一个或多个pretext任务的训练,然后将该模型的一个中间特征层输入对动作分类、分割或目标跟踪等下游任务进行finetune。Tracking
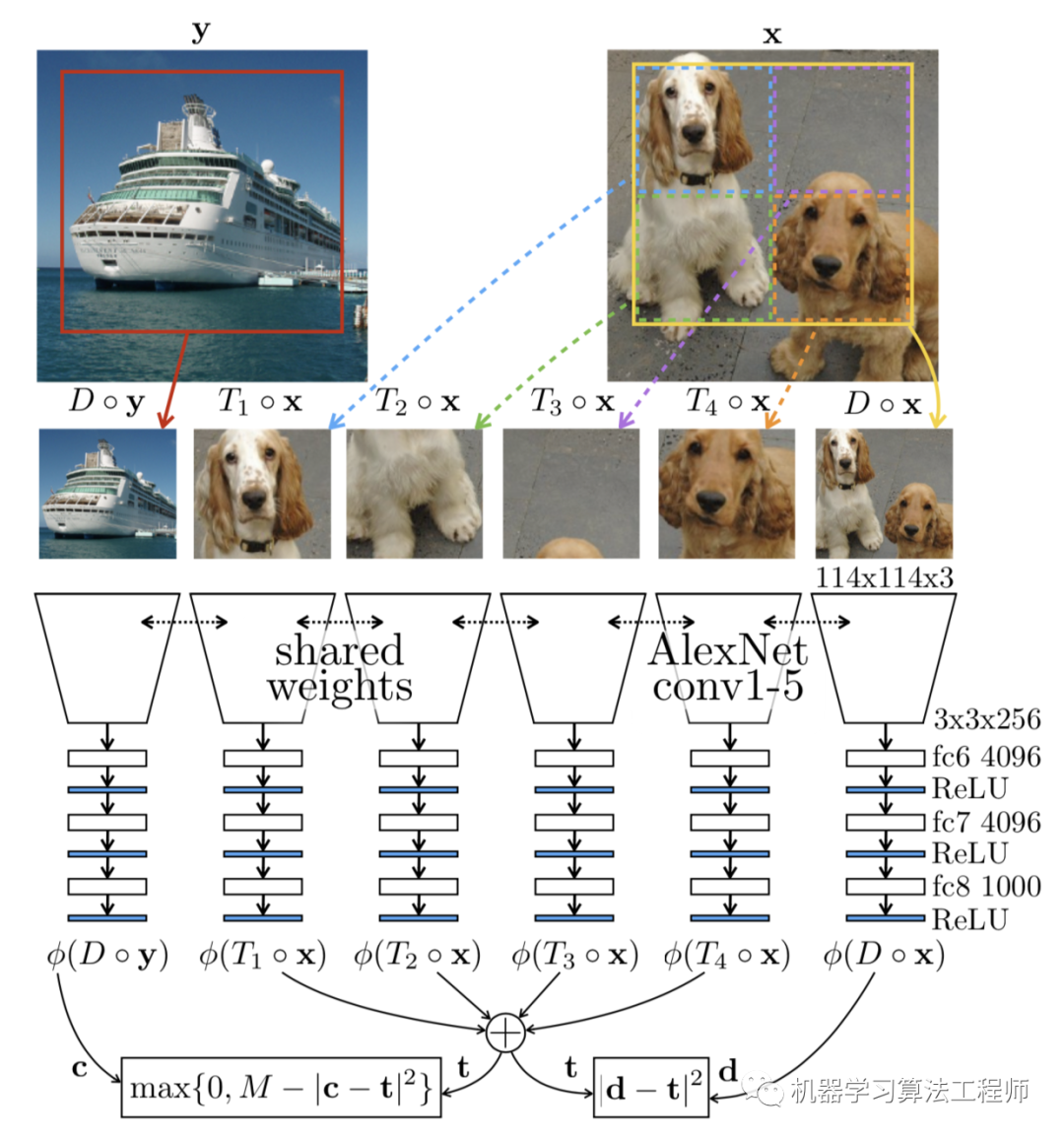
物体的运动由一系列视频帧来跟踪。在近距离的画面中,同一个物体在屏幕上被捕捉的方式通常差别不大,通常是由物体或相机的微小运动触发的。因此,对同一物体学习的任何跨越近帧的视觉表征都应该在潜在特征空间中是接近的。在这个想法的启发下,Wang & Gupta, 201《Unsupervised Learning of Visual Representations using Videos》)提出了一种通过跟踪视频中移动的物体来实现视觉表征的无监督学习的方法。
具体做法:在一个小的window中(30帧)追踪一个patchX,有个和X接近的patchX+,还有一个随机选取的patchX-。这个loss像triple loss
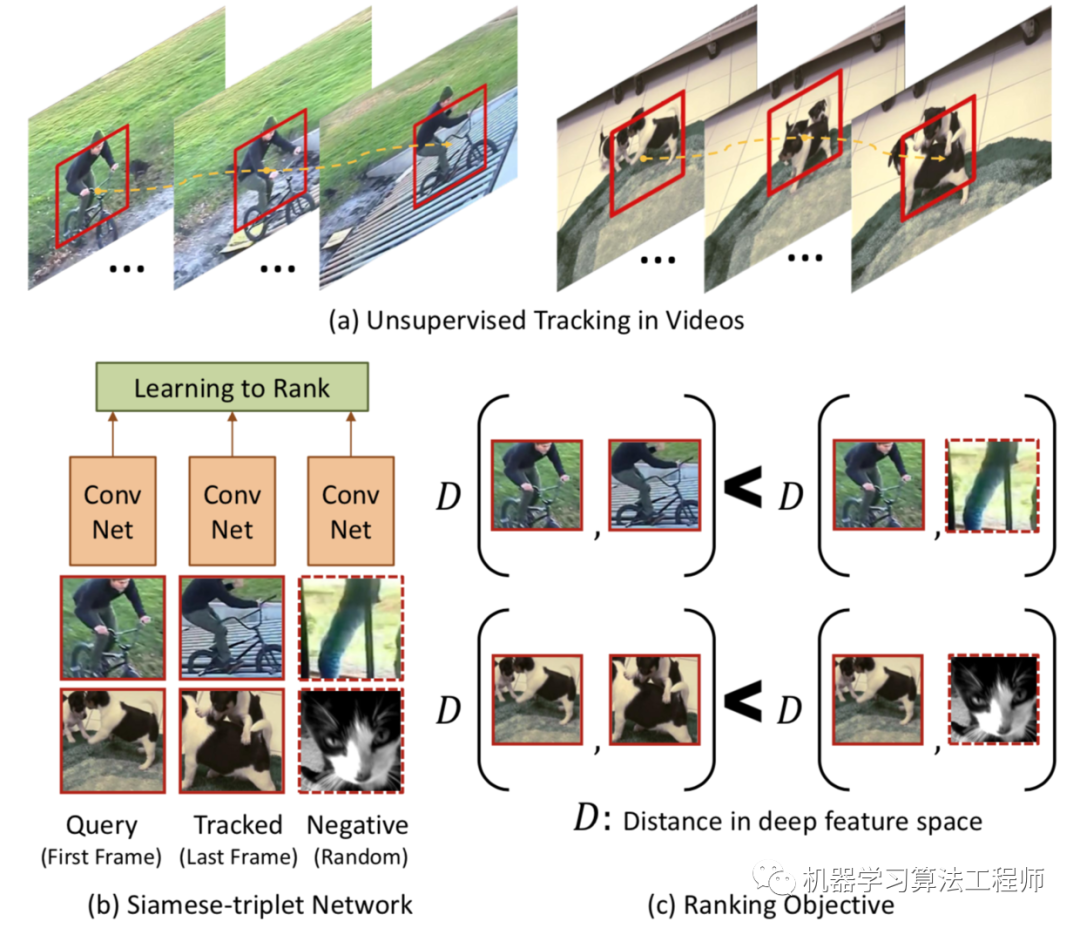
patch的获取:
Frame Sequence(帧序列)
视频帧是按时间顺序自然放置的。研究人员提出了几个自我监督的任务,他们期望良好的表现应该学习帧的正确顺序。《Shuffle and Learn: Unsupervised Learning using Temporal Order Verification》中提出的pretext任务为:判断一段视频序列的顺序是否正确,这样模型可以获得追踪物体和推理的能力。
具体做法为:
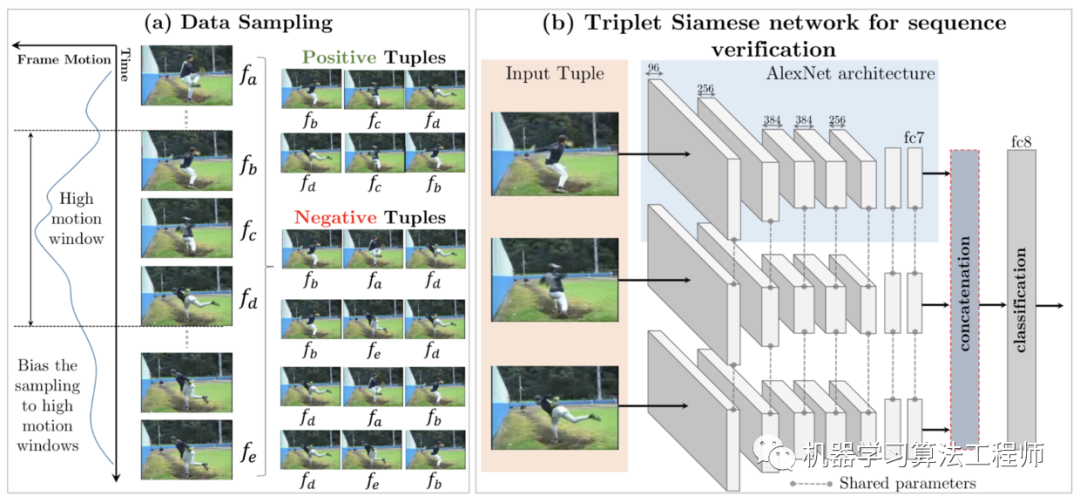
类似的,《Self-Supervised Video Representation Learning With Odd-One-Out Networks》中也提出了一种基于视频序列的无监督学习方法“odd-one-out learning”。要从N+1个序列帧中挑选出某一个古怪的帧。
还有研究给模型播放正序或者倒序的视频,让其预测时间的方向 arrow of time(正或负)为了预测时间箭头,分类器应该同时捕获低级物理和高级语义。提出的T- cam(时间类激活映射)网络接受T组,每个T组包含若干个光流帧。每个组的conv层输出被连接起来并输入到二元逻辑回归中以预测时间箭头。这个pretext任务可以提高动作分类下游任务的性能。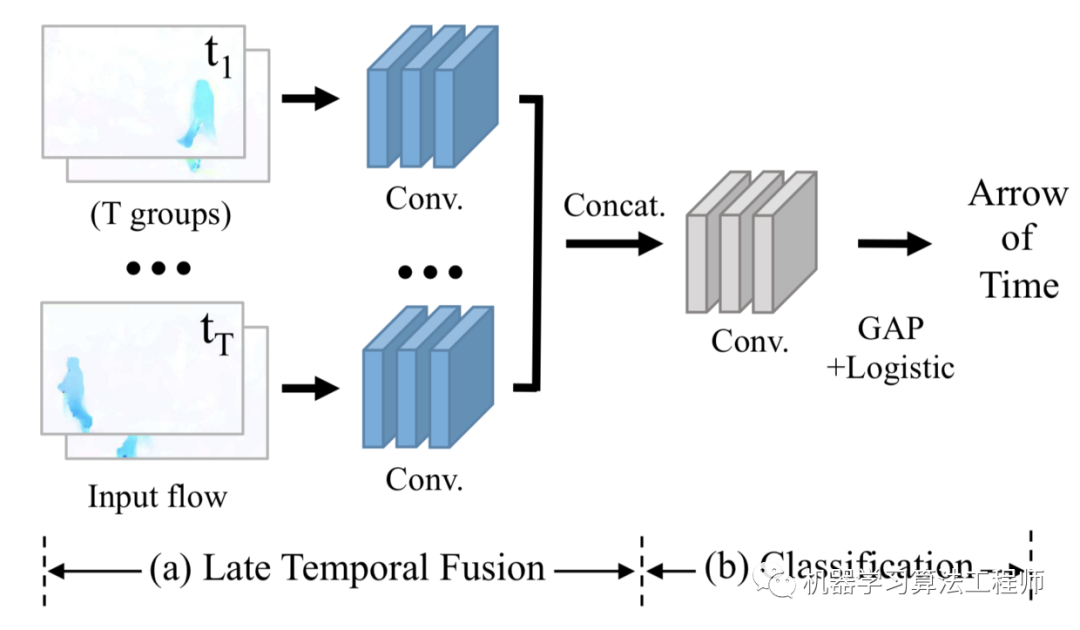
Video Colorization
《Tracking Emerges by Colorizing Videos》提出视频着色可以作为一个自监督问题,在此基础上得到丰富的特征表达且对视频分割和无标签的区域追踪很有效果。
和图片的照射着色的自监督问题不同,视频着色是将基于一张已知的帧对另外一张帧着色。由于帧相近,具有时间相干性,因此他们之间的像素距离也相近,模型被设计用来跟踪不同帧中相关的像素。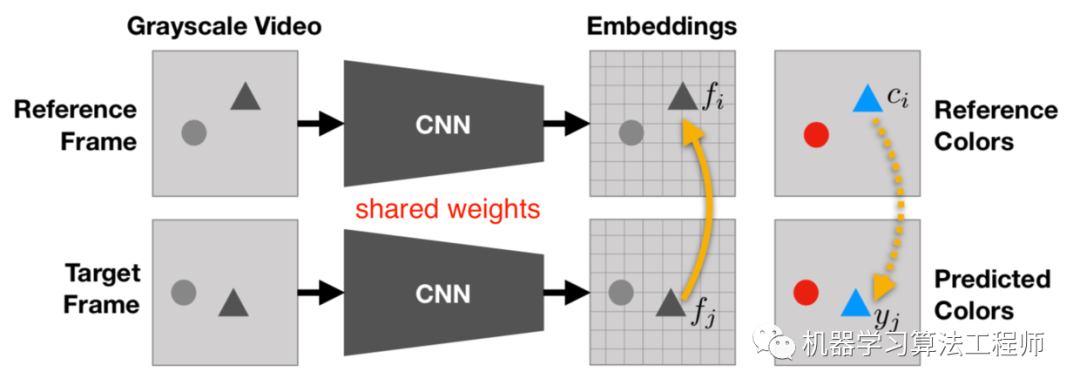

下载1:OpenCV-Contrib扩展模块中文版教程 在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。 下载2:Python视觉实战项目52讲 在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。 下载3:OpenCV实战项目20讲 在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。 交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~