
End-to-End Object Detection with Fully Convolutional Network

摘要
基于全卷积网络的主流目标检测器已经取得了很好的表现。然而大多数检测器仍旧需要一个手动设计的NMS后处理流程,阻碍了端到端的训练。
本文给出去掉NMS的分析,且结果显示适当的标签分配起着至关重要的作用。
为了达到该目的,对全卷机检测器,我们提出了一个感知预测的一对一(POTO)标签分配,用于分类,以实现端到端检测,获得与NMS相当的性能。
同时,一个简单的三维最大过滤(3DMF)模块被用来利用卷积的多尺度特征,提高卷积在局部区域的可分辨性。
通过这些技术,我们的端到端框架实现了与COCO和CrowdHuman数据集上的许多最先进的NMS检测器相比具有竞争力的性能。
摘要中也说明了首先要达到的目的是解决NMS流程在训练时不够端到端的问题,尝试在网络模型前向推理过程中自动的完成重复检测的去除。然后从标签分配着手,设计了POTO模块来辅助训练,并添加了一个重新设计的3DMF模块用于提高性能。
创新点
1、POTO模块在训练时的使用
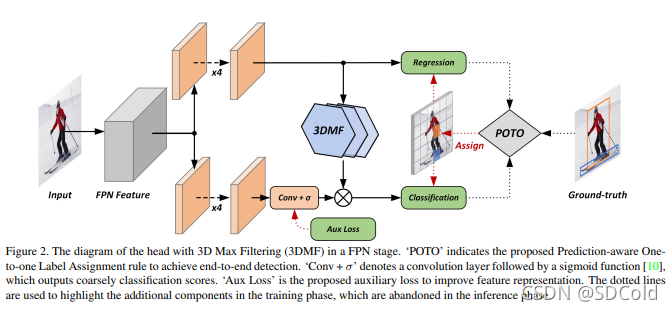
首先如上图,是作者设计的网络模型图,其中作者提出了POTO模块用于辅助模型训练,该模块的设计思路是基于label-assign的思想:
在训练阶段,不断强化“最正确位置检测结果”和“其余检测结果的分数差异”。 然后在部署后的推理阶段则去掉该模块,直接执行前向推理即可。
既然作者在论文摘要中提到了标签分配,就在论文里首先调研了当前的标签分配策略。并大致归类为一对多标签分类和手工设计的一对一标签分类两种。
其中一对多的标签分配就是指类似faster rcnn中的RPN网络 一对一的标签分配指的是类似yolo中的标签分配方式,即anchor策略和center策略。
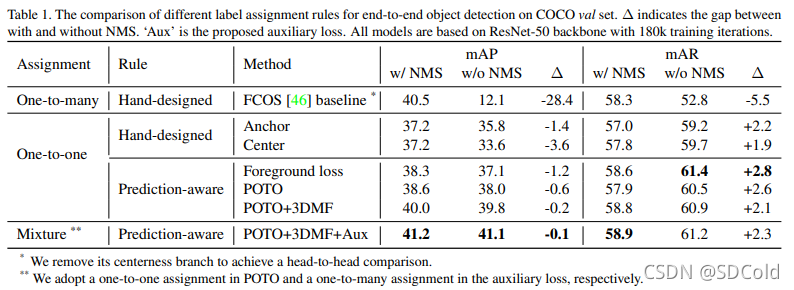
如图为作者做的标签分配策略消融实验的统计表格,选用的数据集为COCO,基线模型为resnet50-FCOS,且去掉了目标中心度感知分支(centerness branch)。
如表所示,作者的结论是一对多标签分配在特征表达上具有优越性,一对一标签分配则在去掉NMS的模型设计方案上展现了潜力。
作者在论文中提出了一种混合的标签分配方案,也就是称为POTO一对一标签分配方案和修改过的一对多的标签分配损失。
作者通过前人的论文观察到一对一的标签分配多采用固定的设计规则,该规则可能会导致的就是将次最高分作为当前ground truth的匹配,从而使得假阳性检测结果升高,也是针对该点,作者提出了自己的POTO一对一标签分配规则,作者简述为通过预测的质量来动态的分类样本标签。
具体来说,就是作者首先使用了空间先验乘以分类分数和iou的加权平均来得到一个归一化的当前预测质量评价值,来代表当前的预测bbox与GT的匹配度。
按我的个人理解来说,这里的操作,作者就是想拉开真阳性和假阳性及负样本的分数差,从而优化模型表现。
作者在后续论文中也强调了采用辅助损失的重要性,辅助损失主要是帮助弥补一对一标签分配对网络的监督过少,也就是正样本过少使得训练不充分,网络没有学的很好的问题。
2、3DMF模块
对于基于FPN的检测器,当将NMS分别应用在每个尺度的特征图下时,性能将明显下降。(这里是说在每个FPN的特征图下先分别做NMS,再合并所有NMS后的结果。废话,分别做NMS后续合并输出结果时bbox的位置误差太大了,根本不能用)。
此外,我们发现重复预测主要来自最可靠预测的邻近空间区域。因此,我们提出了一种新的模块**3DMaxFiltering (3DMF)**来抑制重复预测。
卷积是具有平移等方差的线性运算,为不同位置的相似模式产生相似的输出。然而,这种特性对重复去除有很大的障碍,因为对于密集预测探测器来说,同一实例的不同预测通常具有类似的特征。
最大滤波器是一种基于秩的非线性滤波器,可以用来补偿卷积在局部区域的鉴别能力。此外,在基于关键点的检测器中还采用了最大滤波器,例如Centernet和Cornetnet,作为一个新的后处理步骤来替代NMS。
它展示了执行重复删除的一些潜力,但不可训练的方式阻碍了有效性和端到端训练。同时,max滤波器只考虑单尺度特征,不适用于广泛应用的基于FPN的探测器。
因此,我们扩展了MF到多尺度版本,称为3DMF,在FPN的每个尺度转换特征。feature map的每个通道分别采用3D Max滤波。
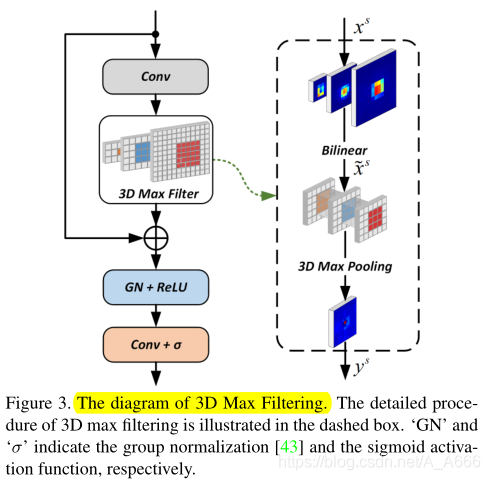
具体如上所示,给定一个FPN尺度s的输入特征x,我们首先采用双线性算子从τ相邻尺度插值特征作为相同大小的输入特征x
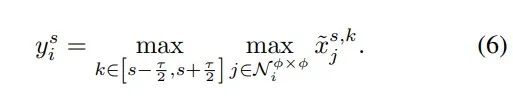
我自己的理解是,作者首先用双线性差值把特征值都弄到一个尺寸,然后基于相同位置的特征应该表征的是相同的场景的先验,直接最大池化出当前位置的最大值作为描述,这样就等于是把特征图的输出中的部分重复描述干掉了。
然后作者在描述这段的时候提到了最大滤波器是一个基于秩的非线性滤波器。我就想到了低秩特征,然后进行类比的思考就是,这里采用将不同层的特征归化到一个尺寸后,可能存在的损失就是高秩的特征信息丢失,那么怎么抽象出和利用好低秩表征没准是个方向。
结论
最后摆上作者的实验结论,本文提出了一种预测感知的一对一标签分配和3D最大滤波,以弥补完全卷积网络和端到端目标检测之间的差距。
在辅助损失的情况下,我们的端到端框架在COCO和CrowdHuman数据集上的许多先进的带NMS的检测器上实现了优越的性能。
我们的方法在复杂和拥挤的场景中也显示出巨大的潜力,这可能有利于许多其他实例级任务。
开源代码地址:https://github. com/Megvii-BaseDetection/DeFCN.
欢迎关注GiantPandaCV
欢迎联系&投稿