
解一道反常的Pandas题(附源数据和代码)
大家好,我是宝器
潘大师(Pandas)基础教程和实战案例我写了不少,增、删、改、查这样的常规操作,感兴趣的同学多看、多练基本上都能掌握的差不多。
但是,实际业务场景,由于各种原因,总会有一些反常的需求。今天这个反常又有代表性的需求,来源于粉丝的提问,相关数据已经做了完全脱敏处理,供大家实战练手。
需求背景
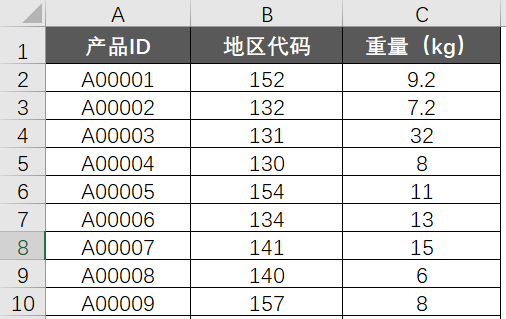
有两张表,A表记录了很多款产品的三个基础字段,分别是产品ID,地区代码和重量:
B表是运费明细表,这个表结构很“业务”。每行对应着单个地区,不同档位重量,所对应的运费:
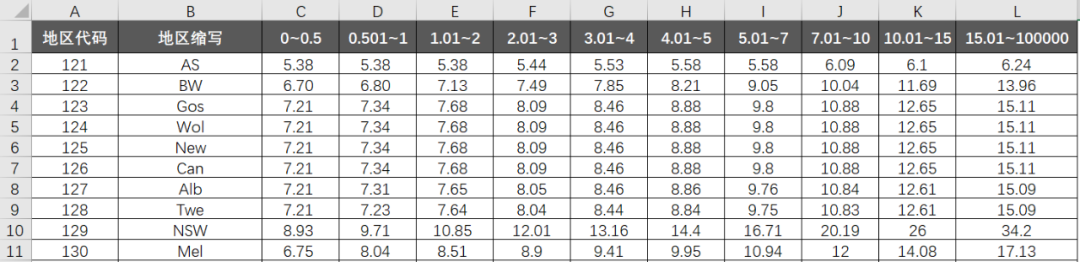
比如121地区,0-0.5kg的产品,运费是5.38元;2.01(实际应该是大于1)-3kg,运费则是5.44元。
现在,我们想要结合A表和B表,统计出A表每个产品付多少运费,应该怎么实现?
可以先自己思考一分钟
解题思路
人海战术
任何数据需求,在人海战术面前都是弟弟。
A表一共215行,我们只需要找215个人,每个人只需要记好自己要统计那款产品的地区代码和重量字段,然后在B表中根据地区代码,找到所在地区运费标准,然后一眼扫过去,就能得到最终运费了。
两个“只需要”,问题就这样easy的解决了。
问题变成了,我还差214个人。
解构战术
通过人海战术,我们其实已经明确了解题的朴素思路:根据地区代码和重量,和B表匹配,返回运费结果。
难点在于,B表是偏透视表结构的,运费是横向分布,用Pandas就算用地区代码匹配,还是不能找到合适的运费区间。
怎么办呢?
如果我们把B表解构,变成“源数据”格式,问题就全部解决了:
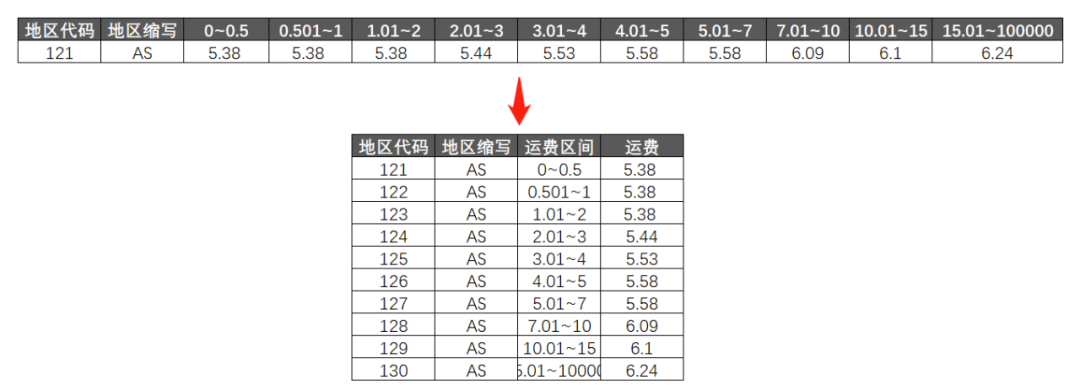
转换完成后,和A表根据地区代码做一个匹配筛选,答案就自己跑出来了。
下面是动手时刻。
具体实现
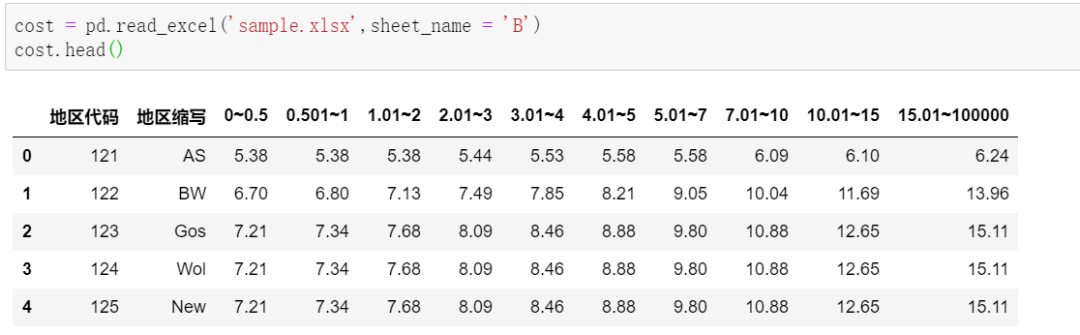
先导入数据,A表(product):

B表(cost):
要想把B表变成“源数据”的格式,关键在于理解stack()堆叠操作,结合示例图比较容易搞懂:
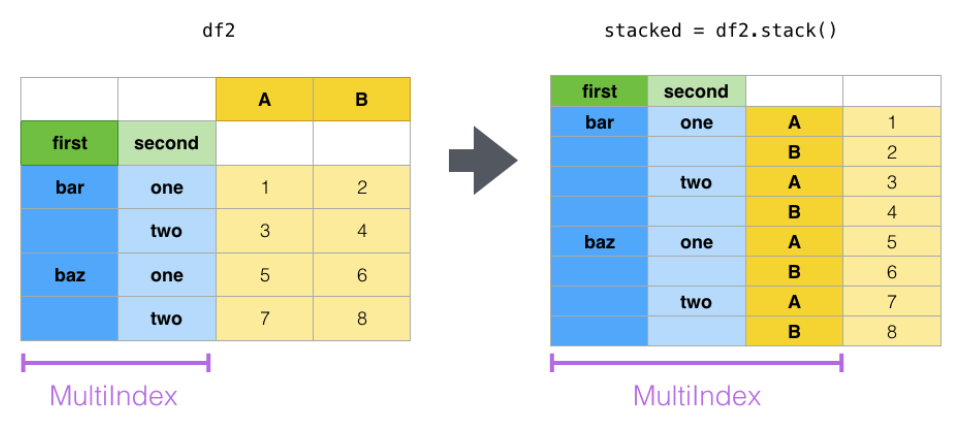
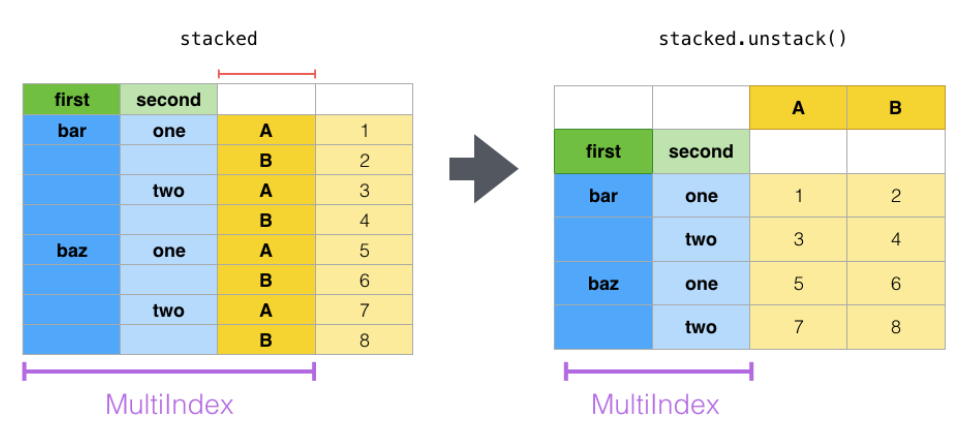
通过stack操作,把多列变为单列多行,原本的2列数据堆成了1列,从而方便了一些场景下的匹配。要变回来也很简单,unstack即可:
在我们的具体场景中,先指定好不变的索引列,然后直接上stack:
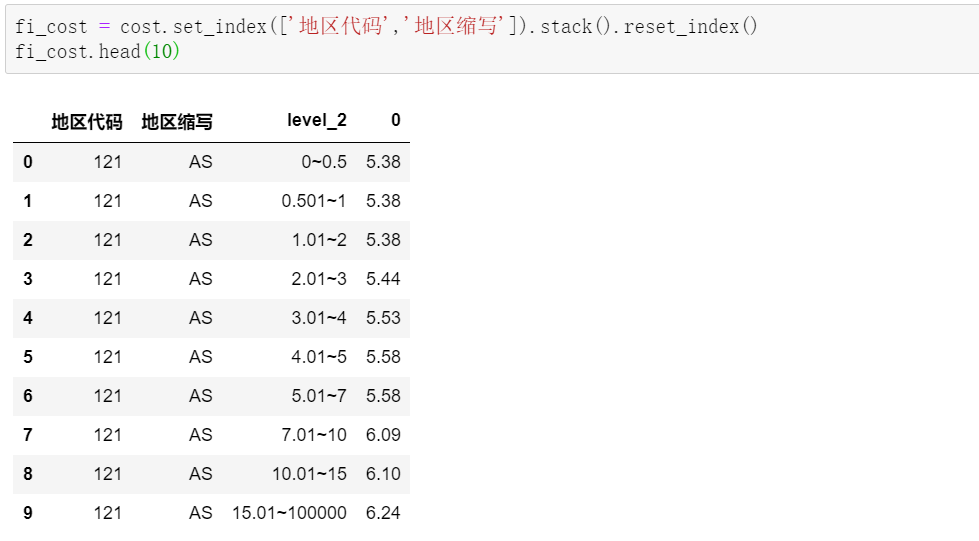
这样,就得到了我们目标的源数据。接着,A表和B表做匹配:
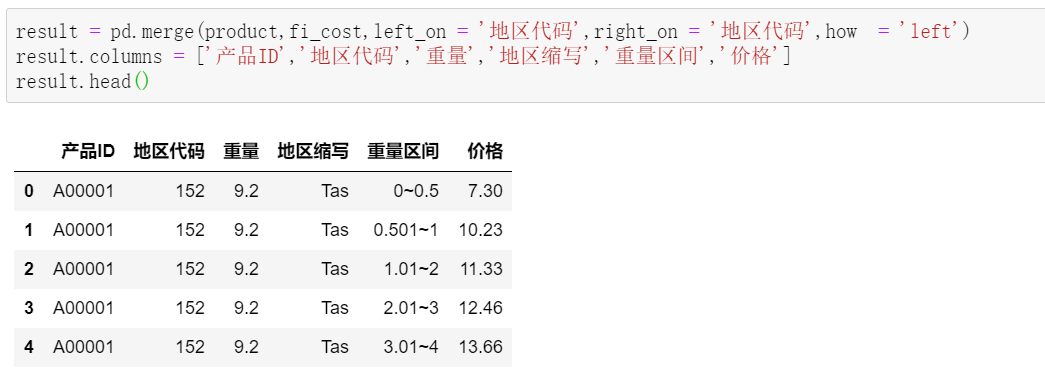
值得注意的是,因为我们根据每个地方的重量区间做了堆叠,这里的匹配结果,每个产品保留了对应地区,所有重量区间的价格,离最终结果还有一步之遥。
需要把重量区间做拆分,从而和产品重量对比,找到对应的重量区间:
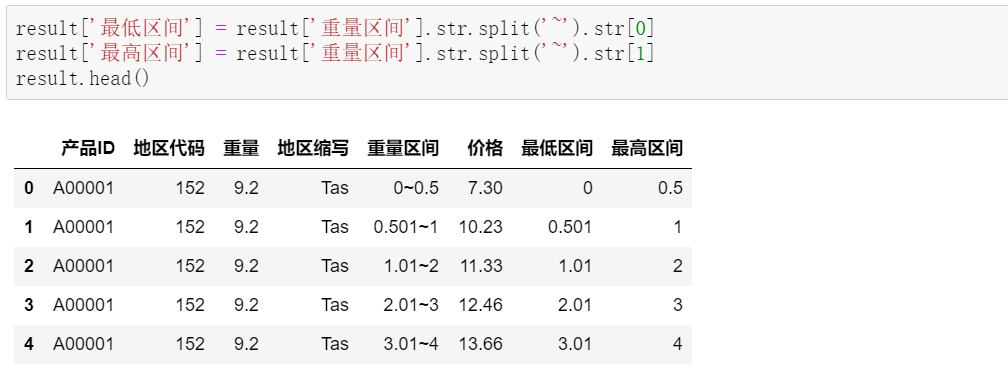
接着,根据重量的最低、最高区间,判断每一行的重量是否符合区间:
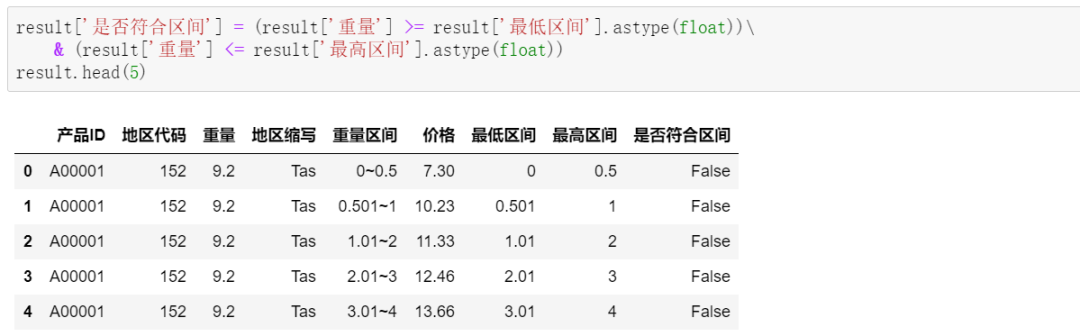
最后,筛选出符合区间的产品,及对应的价格等字段:
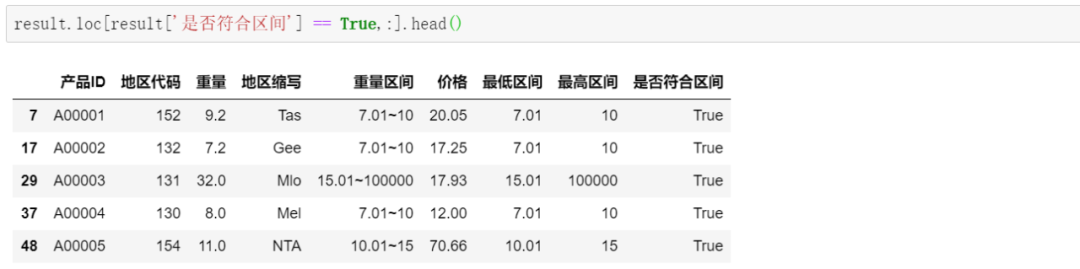
大功告成~

推荐阅读
欢迎长按扫码关注「数据管道」