
幽默度识别第一名解决方案代码及说明

向AI转型的程序员都关注了这个号👇👇👇
机器学习AI算法工程 公众号:datayx
幽默是一种特殊的语言表达方式,在日常生活中扮演着化解尴尬、活跃气氛、促进交流的重要角色。
而幽默计算是近年来自然语言处理领域的新兴热点之一,其主要研究如何基于计算机技术对幽默进行识别、分类与生成,具有重要的理论和应用价值。
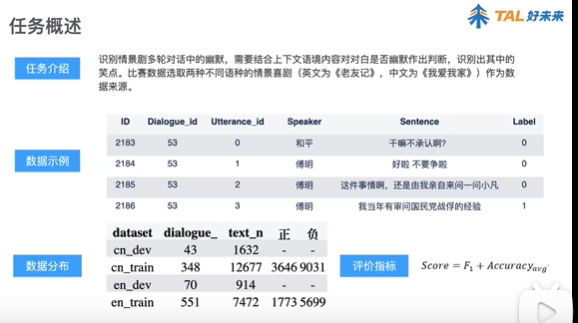
子任务一:生成幽默识别 **F1**
该子任务是二分类任务,标签有:生成幽默(label=0)、非生成幽默(label=1)。任务采用F1值进行评价
子任务二:中文幽默等级划分 **MacroF**
该子任务是三分类任务,标签有:弱幽默(label=1)、普通幽默(label=3)、强幽默(label=5)。任务采用宏平均(Macro-Average)进行评价。宏平均首先对每一个类统计评价指标值
队伍最终的得分由两个子任务的得分综合决定,即:
Score=0.6*子任务一得分+0.4*子任务二得分
划分内容的幽默程度,不仅可以帮助我们判定聊天机器人是不是真的幽默,还可以帮助聊天机器人,对与之聊天的人进行情绪强度的划分,有的人只是想简单幽默一下,而有的人则隐含较强的幽默意味,掌握这些,聊天机器人就能因人而异选择更适宜的方式服务人类。
两个子任务均是分类任务,按照传统的思想,按照以下步骤进行
1.预训练
2.传统模型/BERT等模型训练与调试
3.local CV 验证
4.模型向下接网络层
5.模型融合
6.其他trick
*对于本题,task1区分度较task2大,任务得分权重较大0.6,task2*0.4,针对任务,应该优先优化task1
*本团队在任务进行当中,发现两个任务存在上下游的关系,尝试使用多任务联合学习,并使用任务二的数据对任务一进行数据扩充,取得了明显的效果。
视频讲解
https://www.bilibili.com/video/av415140402
项目 代码 和 数据集 获取方式:
长按图片,识别下面二维码 关注微信公众号 datanlp 然后回复 幽默 即可获取。
搜索公众号关注: datanlp
长按图片,识别二维码
further pre-train BERT or other models on within-task training data and in-domain data
在pretrain下生成预训练模型
1.通过datapro.py对数据进行处理,每段话从中间断开分成两句话,每段话之间用空白行隔开,针对ccl2019幽默度比赛task1和task2,生成了
cclhumortask12_bert.txt,以及加上去年ccl幽默度得比赛数据和我们自行对task1数据翻译生成得到得数据,生成了cclhumortaskalldata_bert.txt
2.通过运行prepocess.py对cclhumortask12_bert.txt和cclhumortaskalldata_bert.txt这两份数据分别在chinese_L-12_H-768_A-12、bert_wwm、bert_wwm_ex
、roberta四个中文预训练模型处理得到了8个文件夹
pytorchmodeltask12_bert_1005
pytorchmodeltask12_roerta_1005
pytorchmodeltask12_wwm_1005
pytorchmodeltask12_wwm_ex_1005
pytorchmodeltaskalldata_bert_1005
pytorchmodeltaskalldata_roerta_1006
pytorchmodeltaskalldata_wwm_1005
pytorchmodeltaskalldata_wwm_ex_1005
3.运行finetune_on_pretrain.py针对上述生成得8个文件夹分别进行预训练,为了不产生太多的文件夹最终生成的pytorch预训练模型
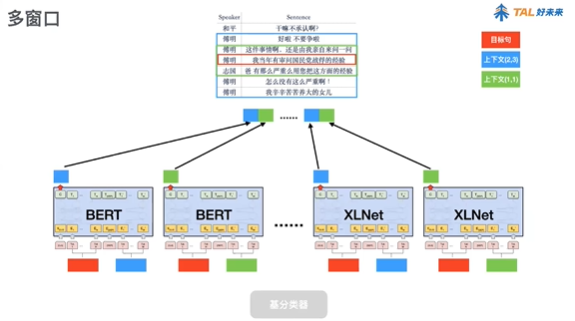
fine-tune
用bert等事先训练好的预训练模型,采用输出的[CLS]token的向量作为特征,向下接线性分类层。
融合策略
对于cv内的每个模型,分别在其预留验证集上对结果进行微调,找到最佳的分类阈值,并用在测试集的预测结果。综合所有模型的微调结果

Multi-task learning(实验中)
为什么多任务学习有效
定义两个任务A和B, 两者的共享隐藏层用F表示。
隐式数据增加机制. 多任务学习有效的增加了训练实例的数目. 由于所有任务都或多或少存在一些噪音, 同时学习到两个任务可以得到一个更为泛化的表示. 如果只学习任务A要承担对任务A过拟合的风险, 然而同时学习任务A与任务B对噪音模式进行平均, 可以使得模型获得更好表示F;
注意力集中机制. 若任务噪音严重, 数据量小, 数据维度高, 则对于模型来说区分相关与不相关特征变得困难. 多任务有助于将模型注意力集中在确实有影响的那些特征上, 是因为其他任务可以为特征的相关与不相关性提供额外的证据;
窃听机制. 对于任务B来说很容易学习到某些特征G, 而这些特征对于任务A来说很难学到. 这可能是因为任务A与特征G的交互方式更复杂, 或者因为其他特征阻碍了特征G的学习. 通过多任务学习, 我们允许模型窃听, 即任务A使用任务B来学习特征G;
表示偏置机制. 多任务学习更倾向于学习到一类模型, 这类模型更强调与其他任务也强调的那部分表示. 由于一个对足够多的训练任务都表现很好的假设空间, 对来自于同一环境的新任务也会表现很好, 所以这样有助于模型展示出对新任务的泛化能力;
正则化机制. 多任务学习通过引入归纳偏置起到与正则化相同的作用, 它减小了模型过拟合的风险, 降低了拟合随机噪声的能力。
提升细节:
task1:
加入任务二数据 +0.04
调整各类损失权重 +0.02
融合模型时学习最佳分类阈值 +0.02
task2:
调整各类损失权重 +0.01
融合模型时学习最佳分类阈值 +0.01
不同batch_size训练模型融合 +0.02
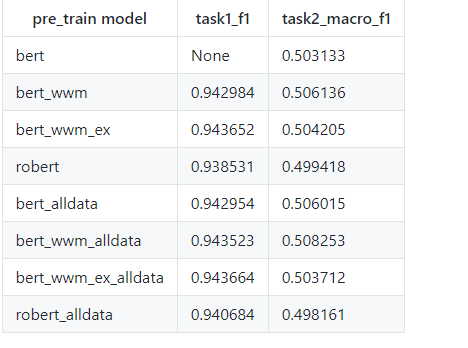
结果对比
机器学习算法AI大数据技术
搜索公众号添加: datanlp
长按图片,识别二维码
阅读过本文的人还看了以下文章:
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx