CVPR 2022 | 华为诺亚&北大提出新框架,性能超越Swin Transfomer(源代码下载)
来源:计算机视觉研究院
来自华为诺亚方舟实验室、北京大学、悉尼大学的研究者提出了一种受量子力学启发的视觉 MLP 新架构。

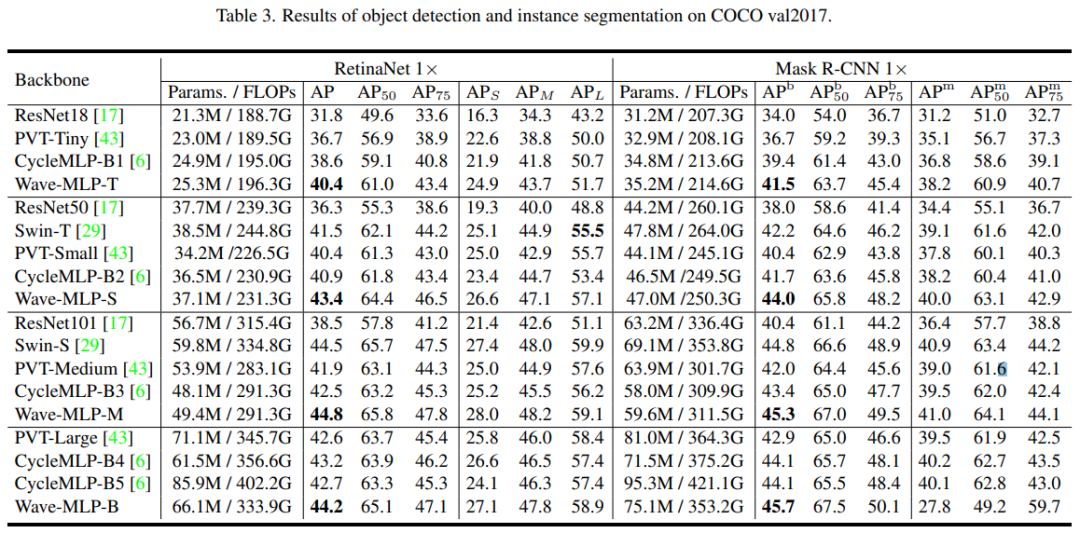
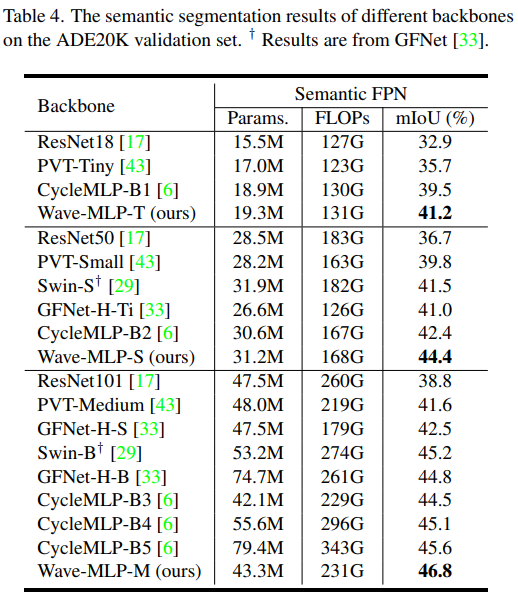
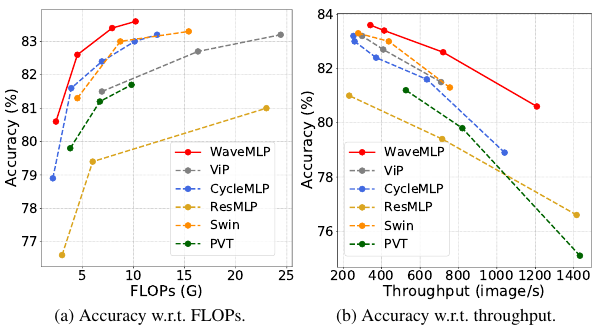
该研究受量子力学中波粒二象性的启发,将 MLP 中每个图像块 (Token) 表示成波函数的形式,从而提出了一个新型的视觉 MLP 架构——Wave-MLP,在性能上大幅超越了现有 MLP 架构以及 Transformer。
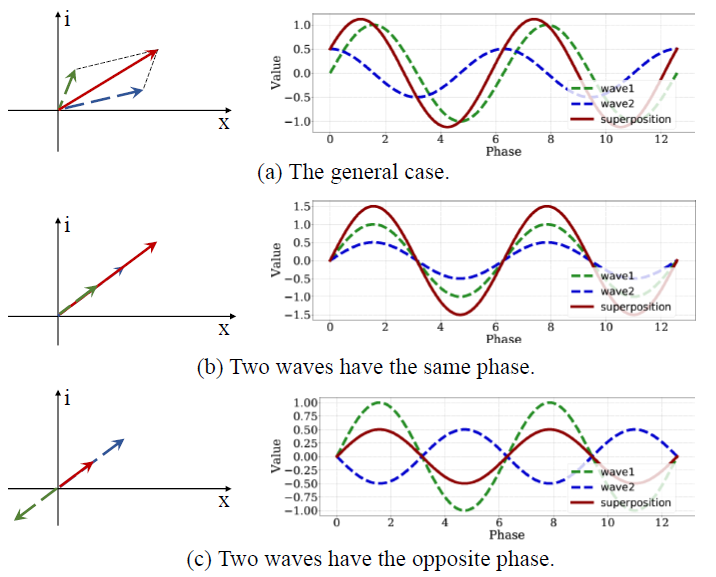
量子力学是描述微观粒子运动规律的物理学分支,经典力学可被视为量子力学的特例。量子力学的一个基本属性是波粒二象性,即所有的个体(比如电子、光子、原子等)都可以同时使用粒子的术语和波的术语来描述。一个波通常包括幅值和相位两个属性,幅值表示一个波可能达到的最大强度,相位指示着当前处在一个周期的哪个位置。将一个经典意义上的粒子用波(比如,德布罗意波)的形式来表示,可以更完备地描述微观粒子的运动状态。
那么,对于视觉 MLP 中的图像块,能不能也把它表示成波的形式呢?该研究用幅值表达每个 Token 所包含的实际信息,用相位来表示这个 Token 当前所处的状态。在聚集不同 Token 信息的时候,不同 Token 之间的相位差会调制它们之间的聚合过程(如图 3 示)。考虑到来自不同输入图像的 Token 包含不同的语义内容,该研究使用一个简单的全连接模块来动态估计每个 Token 的相位。对于同时带有幅度和相位信息的 Token,作者提出了一个相位感知 Token 混合模块(PATM,如下图 1 所示)来聚合它们的信息。交替堆叠 PATM 模块和 MLP 模块构成了整个 Wave-MLP 架构。

 ,
, 其中 i 是满足 i^2 = -1 的虚数单位,|·| 表示绝对值运算,⊙是逐元素乘法。幅值 |z_j| 是实值的特征,表示每个 Token 所包含的内容。θ_j 表示相位,即 Token 在一个波周期内的当前位置。
其中 i 是满足 i^2 = -1 的虚数单位,|·| 表示绝对值运算,⊙是逐元素乘法。幅值 |z_j| 是实值的特征,表示每个 Token 所包含的内容。θ_j 表示相位,即 Token 在一个波周期内的当前位置。
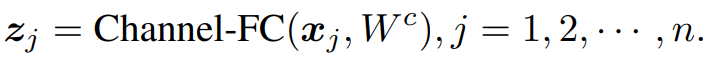
。同时,公式(1)可以采用欧拉公式展开成连个实值向量拼接的形式: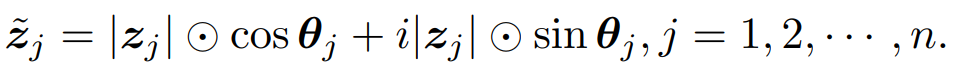 表示不同的 Token 波函数会通过一个 Token-FC 聚合起来,得到复数域的输出:
表示不同的 Token 波函数会通过一个 Token-FC 聚合起来,得到复数域的输出:

 在视觉 MLP 中,该研究构建了一个相位感知模块(PATM,图 1)来完成 Token 聚合的过程。交替堆叠PATM 模块和 channel-mixing MLP 组建了整个 WaveMLP 架构。
在视觉 MLP 中,该研究构建了一个相位感知模块(PATM,图 1)来完成 Token 聚合的过程。交替堆叠PATM 模块和 channel-mixing MLP 组建了整个 WaveMLP 架构。