
超越Swin Transformer!谷歌提出了收敛更快、鲁棒性更强、性能更强的NesT

极市导读
谷歌&罗格斯大学的研究员对ViT领域的分层结构设计进行了反思与探索,提出了一种简单的结构NesT,方法凭借68M参数取得了超越Swin Transformer的性能。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

本文是谷歌&罗格斯大学的研究员在Vision Transformer的一次尝试,对ViT领域的分层结构设计进行了反思与探索,提出了一种简单的结构NesT:它在非重叠图像块上嵌套基本transformer,然后通过分层方式集成。所提方法不仅具有更快的收敛速度,同时具有更强的数据增广鲁棒性。更重要的是,所提方法凭借68M参数取得了超越Swin Transformer的性能,同时具有更少(仅43%)的参数量。
Abstract
尽管分层结构在Vision Transformer领域非常流行,但它需要复杂设计以及大量的数据才能表现够好。我们进行了如下探索:在非重叠图像块上嵌套基本局部Transformer,然后采用分层方式进行集成。我们发现:块集成函数对于促进跨块非局部信息通信起着非常重要的作用。该发现促使我们设计了一种简单的结构,仅需对原始Vision Transformer进行微小改动即可取得显著性的性能提升。
实验结果表明:所提NesT具有更快的收敛速度、更少的训练数据即可取得好的泛化性能。比如,68M参数量的NesT在ImageNet可以取得82.3%/83.8%的top1精度(注:这两个精度是训练100epoch与300epoch时所得,验证图像尺寸为),优于已有方案同时减少了57%的参数量。在CIFAR10数据集上,采用单个GPU训练的6M参数量的NesT取得了96%的精度,取得了Vision Transformer领域的新的SOTA精度。
除了图像分类外,我们还将该思想扩展到了图像生成任务,表明:相比其他基于Transformer的生成器,所提方法是一种极强的decoder,同时具有8x更快的速度。此外,我们还提出一种新的方法对所学习模型进行可视化。
Method
Main Architecture
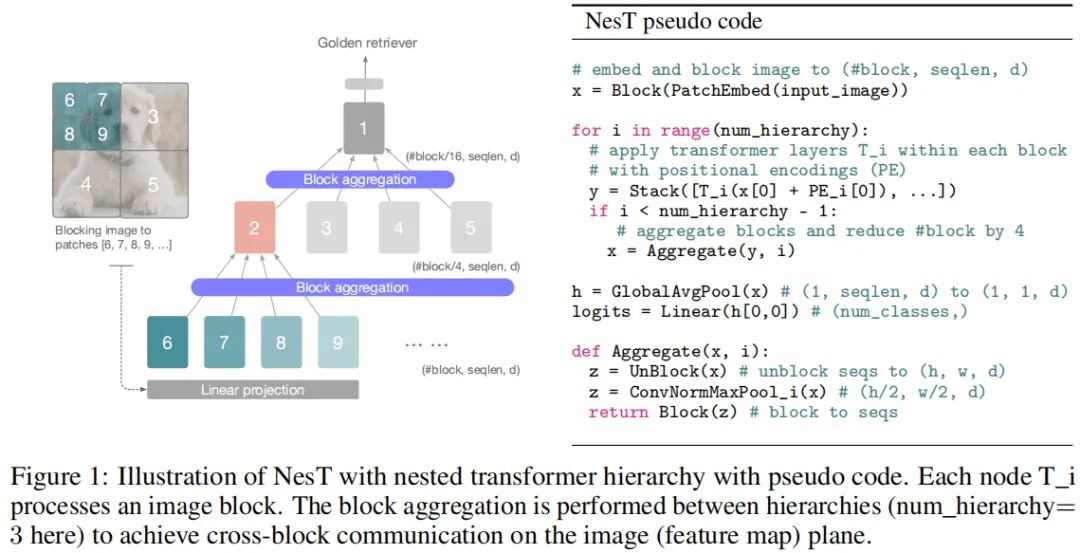
上图给出了所提方案的架构示意图与伪代码实现,它采用堆叠基础transformer层在每个独立图像块上实施局部自注意力,然后采用分层方式嵌套集成。通过所提层间块聚合,空域相邻块之间实现的信息耦合与通信。整体分层结构空域通过关键超参数决定:块尺寸与分分层数。每层内所有块还会进行参数共享。
给定输入图像,每个尺寸图像块线性投影到词向量空间,所有词向量拆分为块并平展生成输入,表示NesT最底层的块数,n表示序列长度,。
在每个图像块内,我们简单堆叠多个transformer层,每个层包含一个多头自注意力(MSA)后接全连接层与跳过连接、LayerNorm(LN),可训练的位置嵌入向量将倍加到所有序列向量中以编码空间位置信息:
给定输入,由于NesT同层块的参数共享性,此时上述公式可以转换成如下并行形式:
最后,我们采用所提块集成构建一个分层嵌套:即每四个空域相邻的块合并为一个块。这种设计方式使得NesT极为容易实现,仅需对原始ViT进行微调改动即可。
Block Aggregation
从高层视觉来看,NesT产生了分层表达,类似于金字塔。然而,现有工作大多采用全局自注意力并于下采样交叉。相反,所提NesT仅利用局部注意力即可产生更强的数据有效利用。在局部自注意力中,非局部通信对于保持平移不变性非常重要。
不同于HaloNet、Swin Transformer,NesT的每个块采用标准transformer层独立的处理信息,仅在块集成阶段采用简单的空域操作(比如卷积、池化)进行通信并混合全局信息。块集成的关键在于:在图像层面执行块集成以促进近邻块的信息交互。可参见Figure1.
具体来说,层的输出转换全图像平面,在下采样特征上执行空域操作,最后特征再转换为。从中空域看到:序列长度n保持不变,总块数以倍率4下降直到1位置,即。因此,很自然的构建了一种分层嵌套结构,同时它的感受野逐步提升。
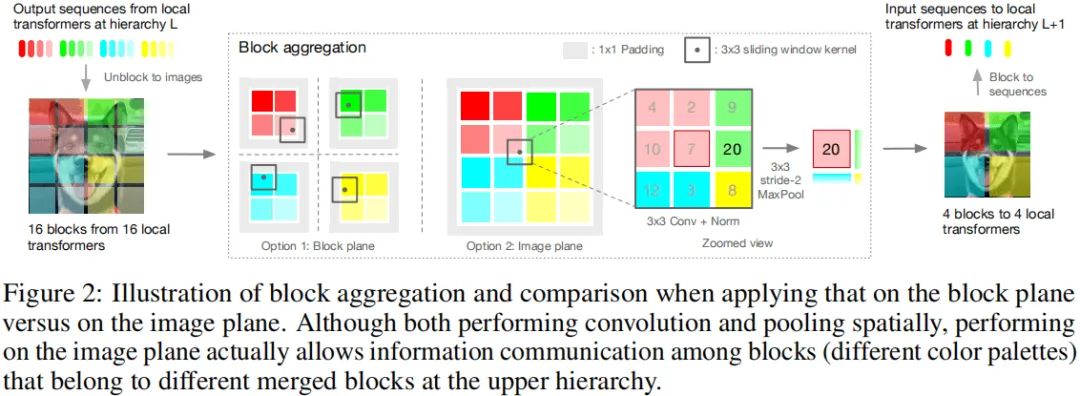
图给出了跨集成的示意图,它卷积+LayerNorm+最大值池化构成。通过卷积与池化构建的跨块信息交互带来了非常重要的增强,后面的实验表明:块集成需要精心设计且与任务相关。
Generation and Interpretability
NestT for Image Generation
NesT的数据高效性与简单性使其可应用于更复杂任务,我们将其应用到生成模型的decoder部分并表明:它可以取得比ConvNet更佳的性能,同时具有相当的速度。值得注意的是,它要比现有基于transformer的decoder快一个量级。

上表给出了NesT构建的生成器架构简要说明,模型的输入为噪声向量,输出为全尺寸图像。为支持渐进提升的模块数量,仅需对NesT的块集成进行合适的调整,比如上采样。在最后,我们将所得输出序列转换到图像空间。
从实验可以得出:精心设计的块集成模块使其可以显著提升模型性能。
Visual Interpretability via Tree Traversal
不同于现有方法,NesT中的嵌套分层块具有类似决策树的效果,即非重叠块上学习特征,然后通过块集成自适应选择。这种独一无二的特性驱动我们探索一种新的方法解释模型的决策特性。

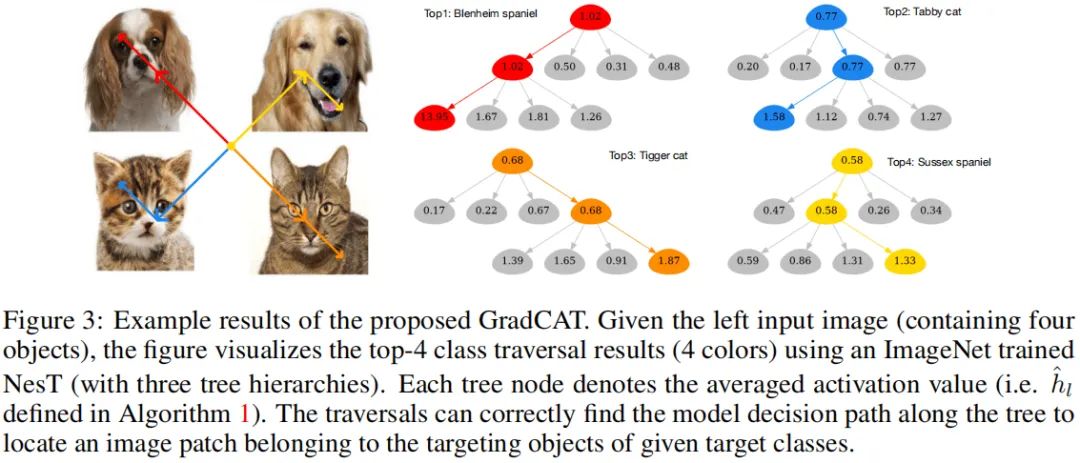
上图给出了本文所提GradCAT方法,其主要思想在于:寻找从子节点到根节点最具价值的路径。直观上来讲,在顶层,四个子节点分别处理非重叠部分中一个,我们可以采用对应的激活与类别相关梯度特征跟踪高价值信息流直到叶子节点。下图给出了GradCAT的可视化示意图。
Experiments
Main Results
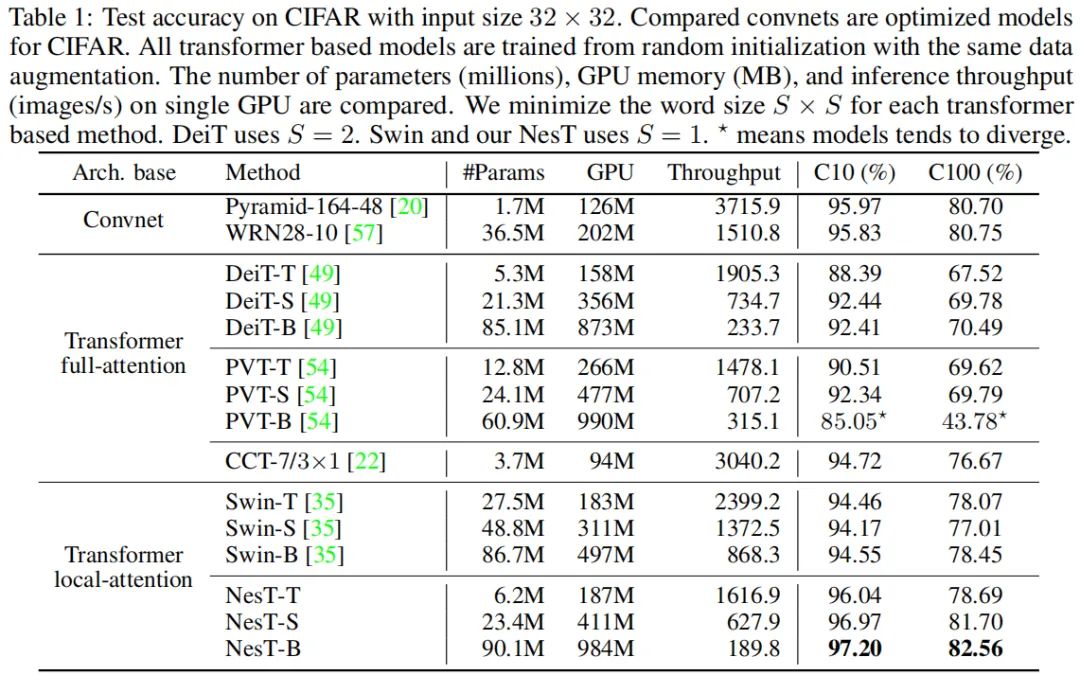
上表给出CIFAR10数据集上的性能对比,可以看到:
之前的Transformer在该任务上表现较差,大尺度数据上表现好并不意味着小尺度数据上表现好。 全注意力方法需要大量的数据才能达到好的性能,比如DeiT、PVT、Swin Transformer。 所提方法在CIFAR10上取得了最佳的性能,显著优于Swin Transformer。
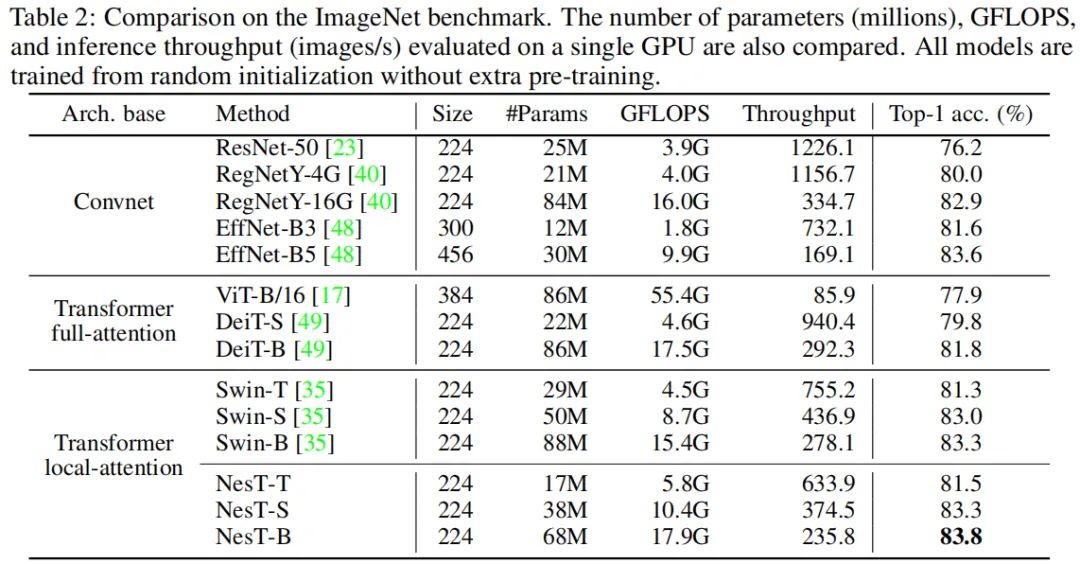
上表给出了ImageNet数据上的性能对比,从中可以看到:
NesT取得了最佳性能:83.8%top1精度; NesT-S凭借38M参数取得了与Swin-B相当的精度(83.3%)同时具有更少的参数量(43%); 上述结果表明:正确的集成局部transformer空域使得简单的局部自注意力表现非常好。
Training Advantages
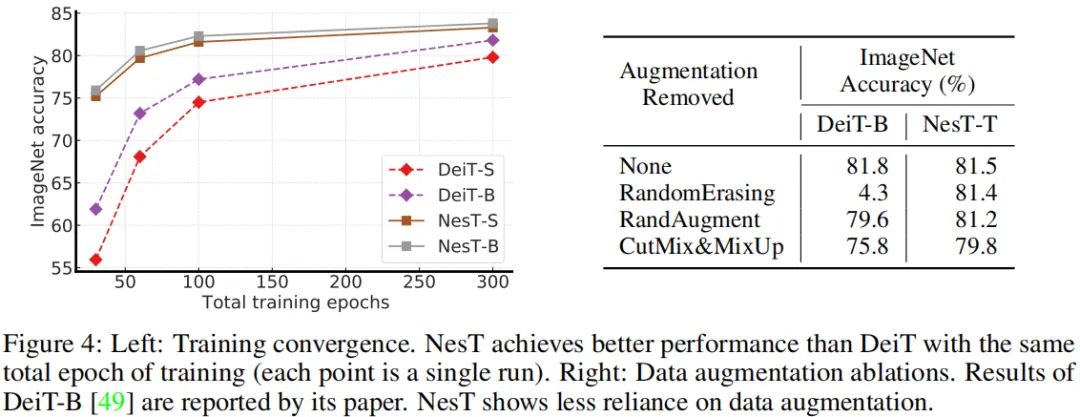
上图给出了所提方案在训练方面的优势,从中可以看到:
NesT具有更快的收敛速度,在100-300epoch训练过程中,DeiT的性能差异高达14%,而NesT差异仅为1.5%。这意味着:相比全局自注意力方法,NesT可以更高效的学习更有效的视觉特征。 NesT对于数据增光具有更强的鲁棒性,全局自注意力的性能受数据增强较大,而NesT则很少受其影响。
Block of Block Aggregation
为说明块集成的重要性,我们从三个角度出发对其进行了理解:
将序列特征转到图像空间是否必要; 如何使用卷积; 采用何种类型的卷积 自注意力内部是否使用采用query
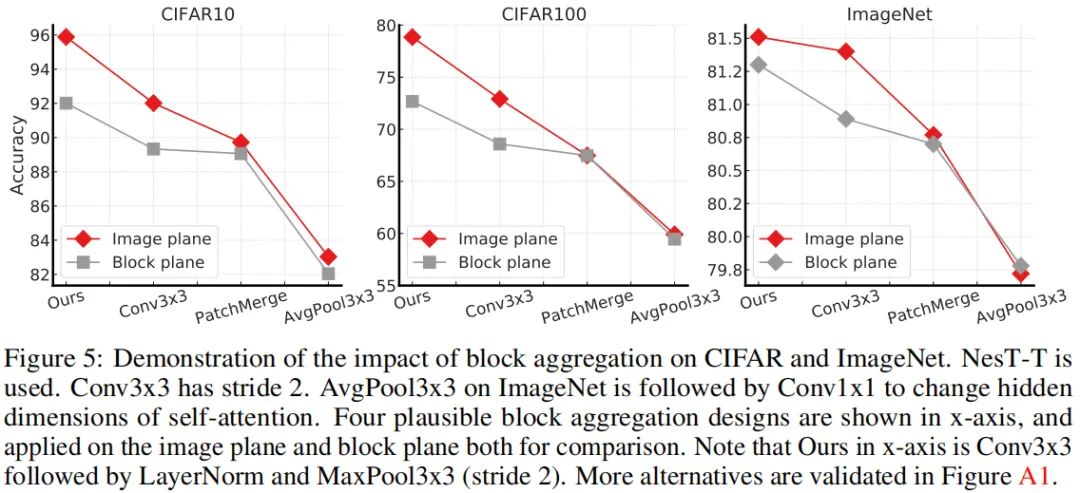
上图比较了不同配置下的性能对比,从中可以看到:
在图像空间进行处理更有必要,可以带来更好的性能提升; 小尺寸卷积+池化组合足够高效; 最大值池化要比其他下采样更佳。
Generative Modeling with NesT as Decoders
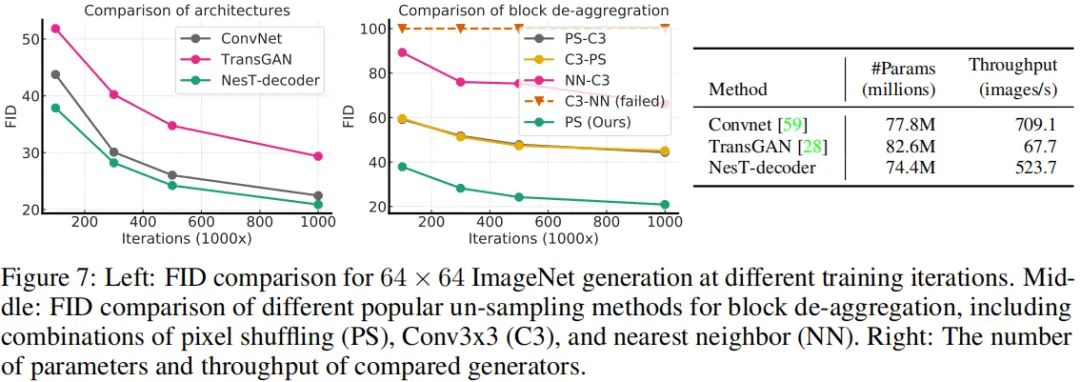
上图对比了所提方案在生成模型中的性能对比,可以看到:相比TransGAN,Nest-decoder具有更快的收敛性,同时具有更高的FID与Inception得分,更重要的是具有8x吞吐量。
Visual Interpretability

上图给出了所提GradCAT的结果示意图,树遍历结果表明 :它可以由目标定位图像块。每个树节点值反应了激活的强度,遍历过程则通过了具有高激活强度的路径。
全文到此结束,更多消融实验与分析,强烈建议各位同学查看原文。
本文亮点总结
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“82”获取CVPR 2021-LightTrack直播回放及PPT~

# 极市原创作者激励计划 #
