
使用OpenCV4实现硬件级别加速
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文使用一个向量点乘的例子,来展示universal intrinsics的的提速。
我们有两个向量vec1和vec2,将对应元素相乘,然后累加起来。计算公式为:
sum=vec1[0]*vec2[0] + vec1[1]*vec2[1]+ ... + vec1[n]*vec2[n].
如果采用纯C语言,两个行向量的点乘实现如下(如代码显示不完整,可以左右滑动;或横屏阅读)
float dotproduct_c_float(Mat vec1, Mat vec2)
{
float * pV1 = vec1.ptr(0);
float * pV2 = vec2.ptr(0);
float sum = 0.0f;
for (size_t c = 0; c < vec1.cols; c++)
{
sum += pV1[c] * pV2[c];
}
return sum;
}
如果采用OpenCV的universal intrinsics,两个行向量的点乘实现如下:
(注意:下面函数仅为展示原理,未考虑数组长度不是16(32或64)字节倍数情况)
float dotproduct_simd_float(Mat vec1, Mat vec2)
{
float * pV1 = vec1.ptr(0);
float * pV2 = vec2.ptr(0);
size_t step = sizeof(v_float32)/sizeof(float);
//向量元素全部初始化为零
v_float32 v_sum = vx_setzero_f32();
for (size_t c = 0; c < vec1.cols; c+=step)
{
v_float32 v1 = vx_load(pV1+c);
v_float32 v2 = vx_load(pV2+c);
//把乘积累加
v_sum += v1 * v2;
}
//把向量里的所有元素求和
float sum = v_reduce_sum(v_sum);
return sum;
}
例程使用Open AI Lab的EAIDK-310开发板,OpenCV4.2.0,CPU型号为是RK3228H,采用ARM四核64位处理器 ,四核Cortex-A53,最高1.3GHz。两个例子的编译命令分别如下(注意:皆采用了-O3选项以提速):
g++ dotproduct-c.cpp -o dotproduct-c -O3 -I/usr/local/include/opencv4 -lopencv_coreg++ dotproduct-simd.cpp -o dotproduct-simd -O3 -I/usr/local/include/opencv4 -lopencv_core运行耗时如下图
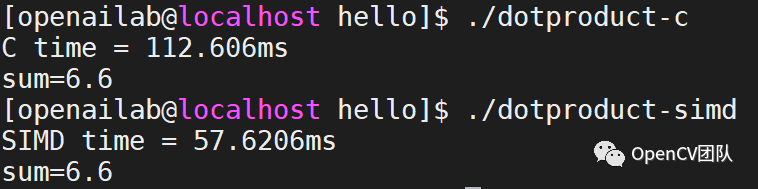
从两个函数的耗时可以看出,采用OpenCV的universal intrinsics后耗时仅为一半,速度翻倍。
两个例程的完整源代码如下。首先是C语言版本的dotproduct-c.cpp:
#include
using namespace cv;
float dotproduct_c_float(Mat vec1, Mat vec2)
{
float * pV1 = vec1.ptr(0);
float * pV2 = vec2.ptr(0);
float sum = 0.0f;
for (size_t c = 0; c < vec1.cols; c++)
{
sum += pV1[c] * pV2[c];
}
return sum;
}
int main(int argc, char ** argv)
{
Mat vec1(1, 16*1024*1024, CV_32FC1);
Mat vec2(1, 16*1024*1024, CV_32FC1);
vec1.ptr(0)[2]=3.3f;
vec2.ptr(0)[2]=2.0f;
double t = 0.0;
t = (double)getTickCount();
float sum = dotproduct_c_float(vec1, vec2);
t = ((double)getTickCount() - t) / (double)getTickFrequency() * 1000;
printf("C time = %gms\n", t);
printf("sum=%g\n", sum);
return 0;
}
dotproduct-simd.cpp如下:
#include
#include
#include
using namespace cv;
float dotproduct_simd_float(Mat vec1, Mat vec2)
{
float * pV1 = vec1.ptr(0);
float * pV2 = vec2.ptr(0);
size_t step = sizeof(v_float32)/sizeof(float);
//向量元素全部初始化为零
v_float32 v_sum = vx_setzero_f32();
for (size_t c = 0; c < vec1.cols; c+=step)
{
v_float32 v1 = vx_load(pV1+c);
v_float32 v2 = vx_load(pV2+c);
//把乘积累加
v_sum += v1 * v2;
}
//把向量里的所有元素求和
float sum = v_reduce_sum(v_sum);
return sum;
}
int main(int argc, char ** argv)
{
Mat vec1(1, 16*1024*1024, CV_32FC1);
Mat vec2(1, 16*1024*1024, CV_32FC1);
vec1.ptr(0)[2]=3.3f;
vec2.ptr(0)[2]=2.0f;
double t = 0.0;
t = (double)getTickCount();
float sum = dotproduct_simd_float(vec1, vec2);
t = ((double)getTickCount() - t) / (double)getTickFrequency() * 1000;
printf("SIMD time = %gms\n", t);
printf("sum=%g\n", sum);
return 0;
}
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~