
使用 shell-operator 实现 Operator
在本文我们将介绍简化 Kubernetes Operator 创建的方法,并展示如何使用 shell-operator 轻松实现自己的 Operator。本文基于我们在 KubeCon Europe 2020上的最新演讲,这是此演讲的完整视频[1]
Kubernetes API 和控制器
我们可以将 Kubernetes API 看成包含每种对象文件夹的文件服务器,这些资源对象通过服务器上的 YAML 文件来表示。APIServer 有一个基本的 HTTP API,使我们可以对这些对象执行三件事。我们可以:
根据资源类型和名称获取资源 更改资源 watch 资源
换句话说,我们可以将 Kubernetes 看作基本上是具有三种通用方法的YAML 文件服务器(当然还有其他方法,我们现在可以先忽略它们)。

但是,服务端本身只能存储信息,为了使其正常工作,我们需要一个控制器 - Kubernetes 中第二重要的基础工具。
通常,有两种类型的控制器,第一种类型从 Kubernetes 读取信息,使用某种逻辑对其进行处理,然后将其写回到 Kubernetes。第二种类型也从 Kubernetes 读取数据,但是与第一种类型不同,它改变了某些外部资源的状态。
我们先看看用户创建 Kubernetes Deployment 时会发生什么:
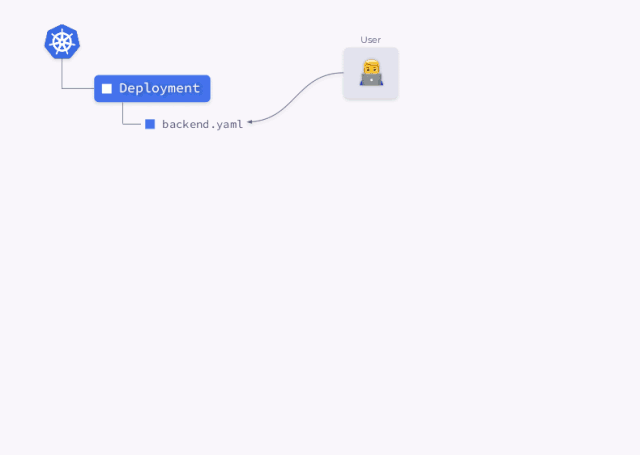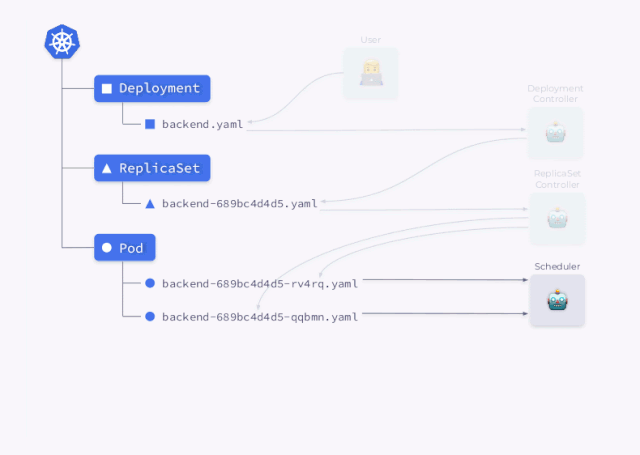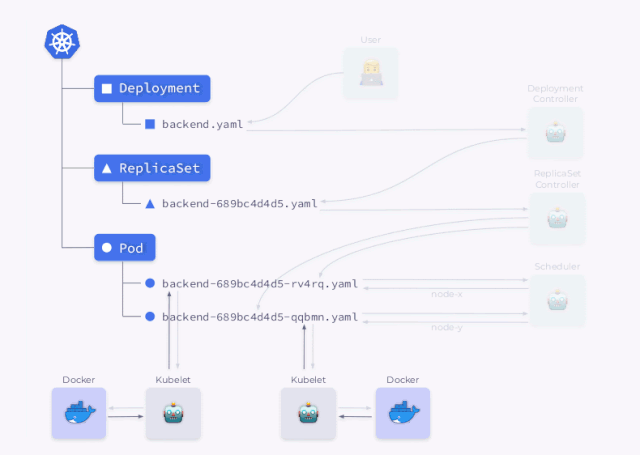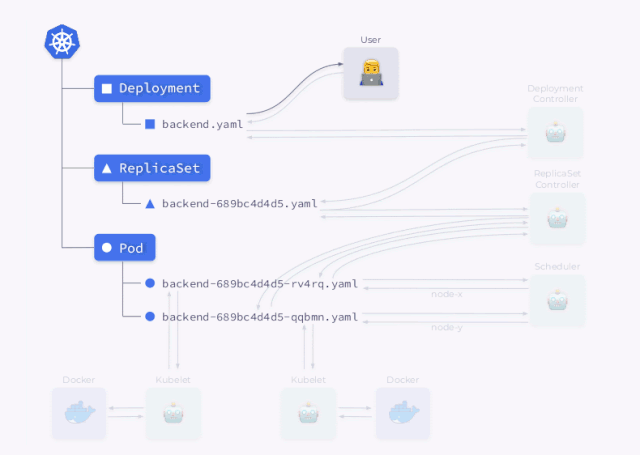
Deployment 控制器( kube-controller-manager的一部分)获取对应的资源信息并创建一个 ReplicaSet。然后,ReplicaSet 使用对应的信息来创建两个 Pod 副本,但是还没有调度这些 Pod。 然后才是调度程序调度 Pod 并将调度结果的节点信息更新回YAML。 最后 Kubelets watch 到 Pod 数据后去启动对应的容器。
然后以相反的顺序重复所有操作:kubelet 检查容器,计算容器的状态,然后将其发送回去。ReplicaSet 控制器 接收它并更新副本集的状态。Deployment 控制器也发生了同样的事情,用户最终获得了当前状态。
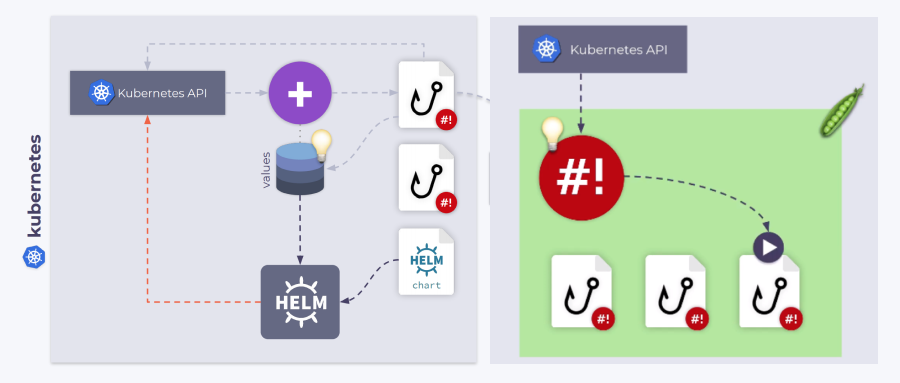
Shell-operator
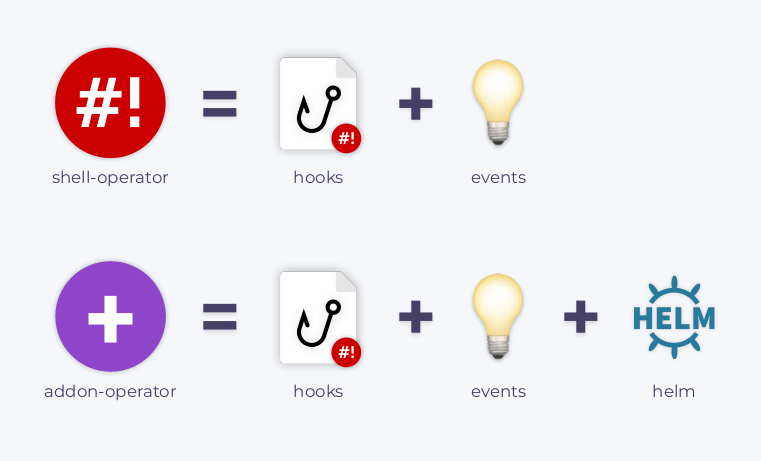
事实上 Kubernetes 完全就是各种控制器一起运行实现的(Operator 也是控制器)。为了能够轻松创建一个控制器呢,我们引入了一个工具 shell-operator[2],它可以让系统管理员使用他们习惯的方法来创建 Operator。

简单的示例:复制 Secrets
让我们看一个简单的例子,假设我们有一个 Kubernetes 集群。其中有一个默认的名称空间,其中包含一些 Secret(mysecret)资源对象。此外,集群中还有其他名称空间。这些名称空间中有几个具有额外的特定标签。我们的目标是将 Secret 复制到带有此标签的名称空间中。
新的命名空间可以出现在集群中,并且其中一些可能带有此标签,这一事实使任务变得复杂。另一方面,如果标签被删除,则 Secret 也必须被删除。Secret 本身也可以更改,在这种情况下,新的 Secret 必须传播到所有带标签的命名空间中去。如果 Secret 在某个命名空间中被意外删除,则 Operator 必须立即将其还原。
现在我们已经了解了需要实现的需求,接下来我们来使用 shell-oprerator 来真正实现它。
运行原理
与其他 Kubernetes 工作负载类似,shell-operator 部署在 Pod中。在 Pod 中有一个 /hooks 的一个子目录,其中存储了可执行文件,它们可以用 Bash、Python、Ruby等编写的,我们称这些可执行文件为hooks。

Shell-opeator 订阅 Kubernetes 事件并执行这些钩子来响应我们感兴趣的事件。
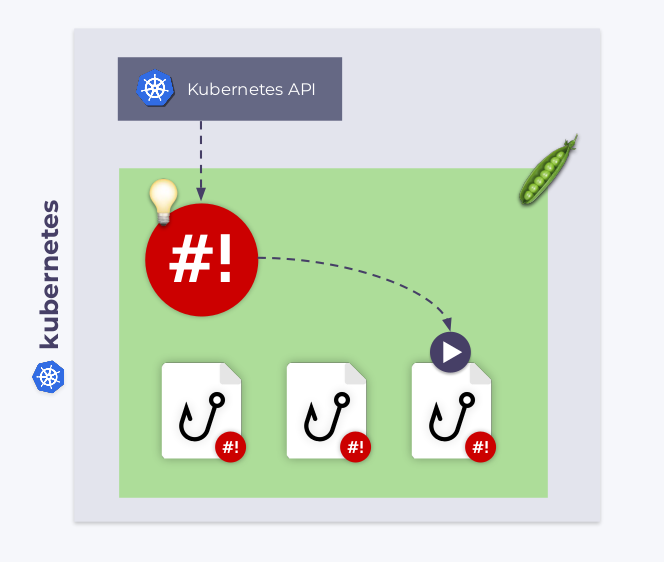
但是,shell-operator 如何知道何时执行钩子呢?事实上每个钩子都有两个阶段。在启动过程中,shell-operator 使用-config参数运行每个钩子。一旦配置阶段结束,钩子将以“正常”方式执行:响应附加给它们的事件。在这种情况下,钩子会获取绑定上下文。
使用 Bash 实现
现在,如果我们使用 Bash,我们需要实现两个函数(强烈建议使用shell_lib[3] 库,因为它大大简化了 Bash 中钩子的编写):
第一个用于配置阶段,并且应该输出绑定上下文; 第二个包含钩子的核心逻辑。
#!/bin/bash
source /shell_lib.sh
function __config__() {
cat << EOF
configVersion: v1
# BINDING CONFIGURATION
EOF
}
function __main__() {
#THE LOGIC
}
hook::run "$@"
下一步是确定我们感兴趣的对象,在我们的示例中,我们需要跟踪:
变更的 Secret 源对象; 集群中的所有命名空间,以查看带有标签的命名空间; 目标 Secret,以验证它们是否已和源 Secret 同步了。
订阅源 Secret
绑定配置非常简单,这里我们的mysecret对default 命名空间中的 Secrets 感兴趣。
function __config__() {
cat << EOF
configVersion: v1
kubernetes:
- name: src_secret
apiVersion: v1
kind: Secret
nameSelector:
matchNames:
- mysecret
namespace:
nameSelector:
matchNames: ["default"]
group: main
EOF
结果会根据源 Secret(src_secret)中的更新执行该钩子,它将获得以下绑定上下文:
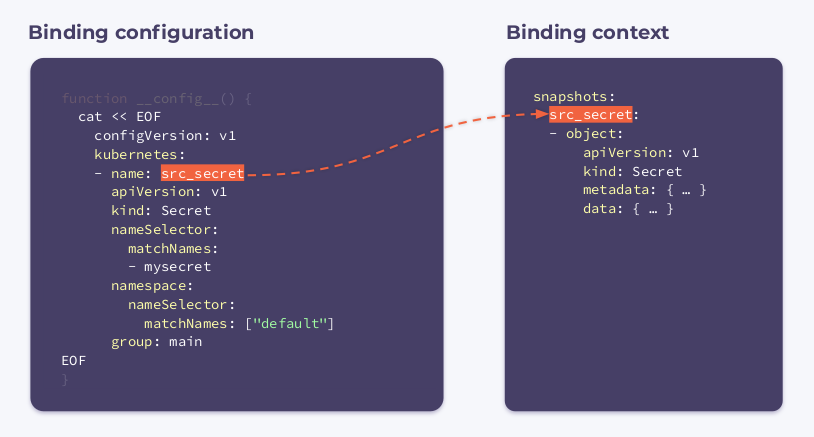
可以看到该绑定上下文具有其名称和完整的对象信息。
处理命名空间
接下来我们需要订阅命名空间,这是所需的绑定配置:
- name: namespaces
group: main
apiVersion: v1
kind: Namespace
jqFilter: |
{
namespace: .metadata.name,
hasLabel: (
.metadata.labels // {} |
contains({"secret": "yes"})
)
}
group: main
keepFullObjectsInMemory: false
可以看到的在配置中有一个新的字段,叫做 jqFilter。顾名思义,jqFilter 就是过滤掉所有不必要的信息,并提供一个新的 JSON 对象,其中包含我们感兴趣的字段。以这种方式配置的钩子会收到以下绑定上下文:
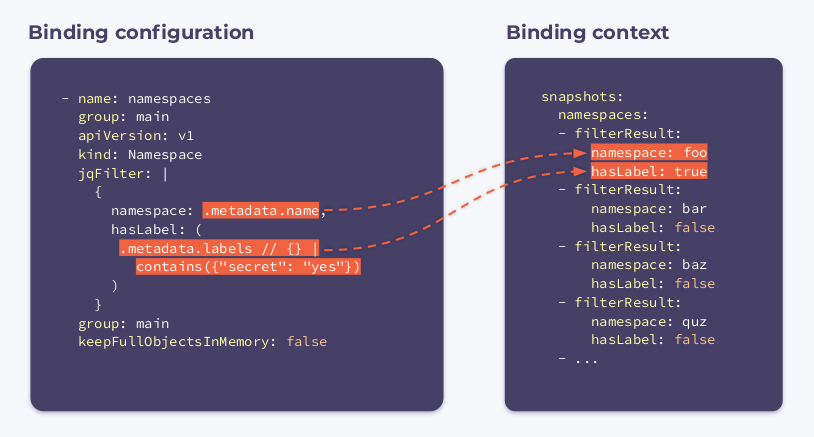
它由集群中每个命名空间的 filterResults 数组组成,布尔变量hasLabel显示相关的命名空间是否具有mysecret标签,keepFullObjectsInMemory: false选择器表示将删除内存中的完整对象。
追踪目的 Secret
我们订阅所有具有 managed-secret: "yes"注释的 Secrets (这些就是是我们的dst_secrets):
- name: dst_secrets
apiVersion: v1
kind: Secret
labelSelector:
matchLabels:
managed-secret: "yes"
jqFilter: |
{
"namespace":
.metadata.namespace,
"resourceVersion":
.metadata.annotations.resourceVersion
}
group: main
keepFullObjectsInMemory: false
在这种情况下,jqFilter过滤掉除命名空间名称和resourceVersion参数之外的所有信息。创建此目标 Secret 时,我们将该参数传递给注释。
以这种方式配置的钩子在执行时将获得上述三个绑定上下文,你可以将它们视为集群的某种快照。

我们可以使用所有这些信息来设计一种最基本的算法,它遍历所有命名空间,如果当前命名空间 hasLabel是true,则进行迭代:
比较源和目标 Secret 如果它们相同,则什么都不做 如果它们不同 - 执行 kubectl replace或者create操作。
如果当前命名空间 hasLabel是false,则:
确保命名空间中没有 Secret 如果目标 Secret 存在 - 执行 kubectl delete如果目标 Secret 不存在,则不执行任何操作。

在我们的示例仓储库中[4],可以找到上述算法的完整 Bash 实现。
35 行 YAML 和相同数量的 Bash 组成了一个简单的 Kubernetes 控制器!Shell-operator 的工作是将它们全部绑定在一起。
显然,使用 Shell-operator 并不是只能复制 Secrets,我们还会用更多示例来了解它的用法。
示例1:更新 ConfigMap
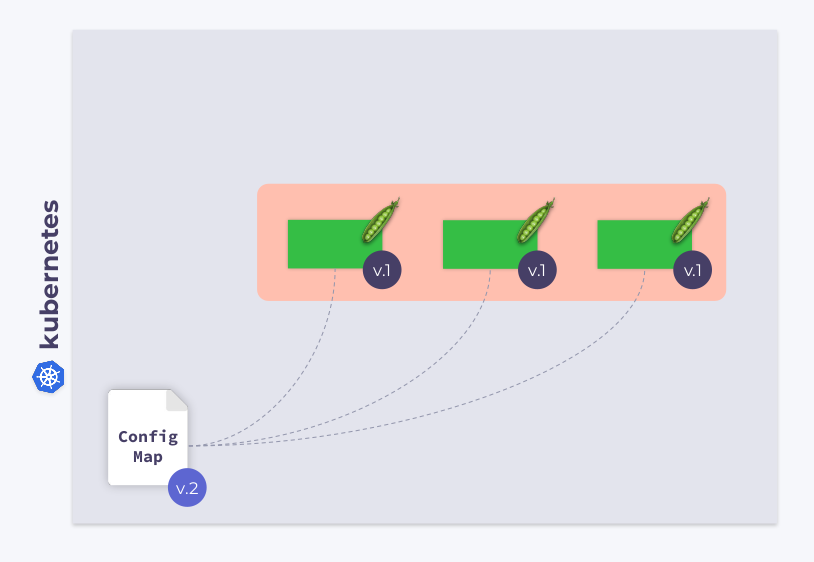
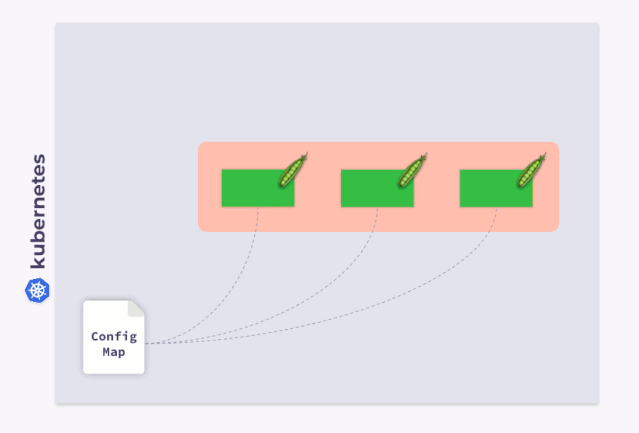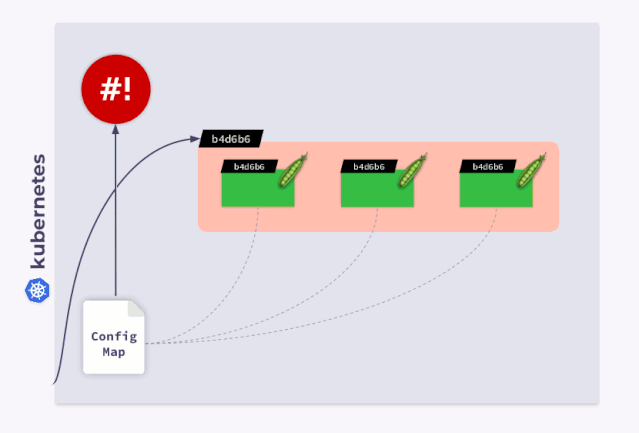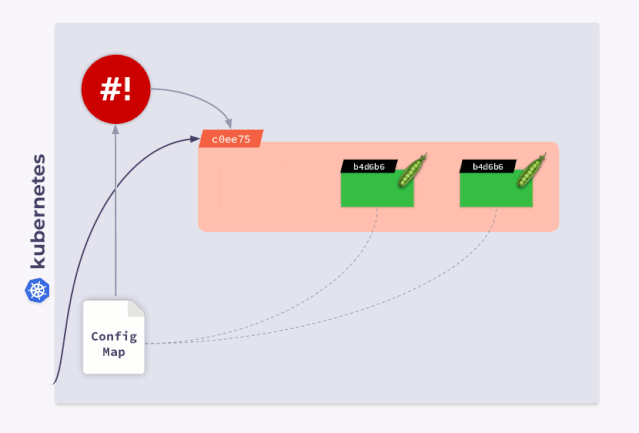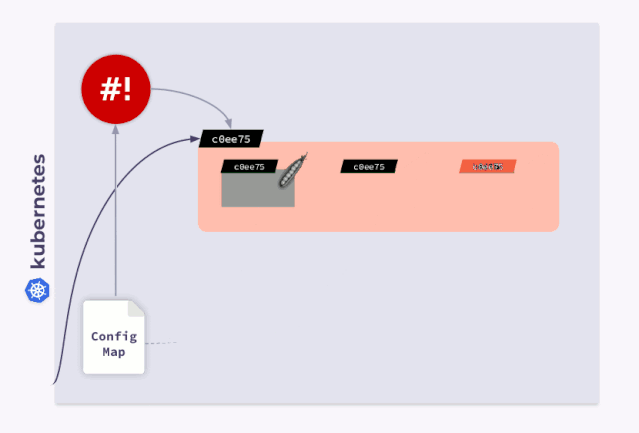
比如现在我们有一个具有三个 Pod 的 Deployment,这些 Pods 使用ConfigMap 来存储一些配置,当这些 Pod 启动时,ConfigMap 处于某种状态(我们将其称为版本1:v.1),我们所有的 Pod 都具有相同的 v.1 版本的 ConfigMap。
现在,假设 ConfigMap 更改为另一个版本 v.2,在这种情况下,我们的Pod 仍将使用 ConfigMap 的早期版本 v.1。
在这种情况下我们通常怎么做呢?是的,我们可以在 Pod 的模板中添加一些内容。因此,让我们将 checksum 注解添加到 Deployment 定义的模板部分:

现在,我们所有的 Pod 都有 checksum,并且与 Deployment 的 checksum 相同。接下来,我们应该更新注释来响应 ConfigMap 的更改。这就是 shell-operator 可能派上用场的时候,我们只需要编写一个钩子即可订阅 ConfigMap 并更新 checksum。
当用户修改 ConfigMap 时,shell-operator 会 watch 到变更并更新 checksum。然后,Kubernetes 会杀死 Pod,创建一个新 Pod,等到准备就绪后再进行下一个 Pod。因此,我们的 Deployment 可以完美同步并与更新的 ConfigMap 一起运行。
示例2:使用 CRD
我们知道 Kubernetes 允许我们创建自定义类型的对象。例如,我们可以创建一个名为 MysqlDatabase 的资源,假设这种类型只有两个元数据参数:name和namespace。
apiVersion: example.com/v1alpha1
kind: MysqlDatabase
metadata:
name: foo
namespace: bar
因此,我们可以在 Kubernetes 集群中创建 MySQL 数据库,在这种情况下,可以使用 shell-operator 来 watch MysqlDatabase这类资源,将它们连接到 MySQL 数据库服务器,并同步所需状态和 watch 到的状态。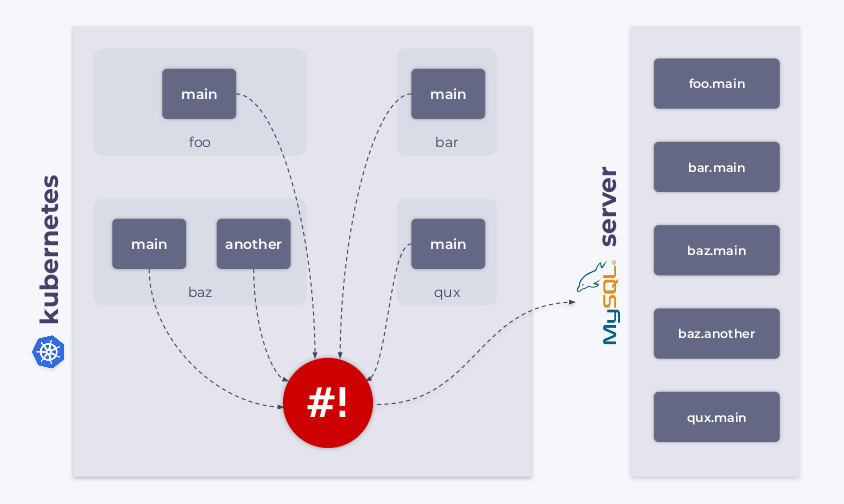
示例3:监控集群网络
如您所知,ping 是监视网络的最简单方法,当然我们也可以使用 shell-operator 来实现。
首先,我们需要订阅节点,shell-operator 需要每个节点的名称和 IP 地址,以循环浏览节点列表并 ping 它们中的每一个。
configVersion: v1
kubernetes:
- name: nodes
apiVersion: v1
kind: Node
jqFilter: |
{
name: .metadata.name,
ip: (
.status.addresses[] |
select(.type == "InternalIP") |
.address
)
}
group: main
keepFullObjectsInMemory: false
executeHookOnEvent: []
schedule:
- name: every_minute
group: main
crontab: "* * * * *"
该executeHookOnEvent: []参数可防止响应任何事件而调用该钩子(更新、添加或删除节点时将不执行挂钩)。但是,它将根据 schedule 字段每分钟运行一次(并更新节点列表)。
我们如何确定丢包之类的问题?让我们看一下如下所示代码:
function __main__() {
for i in $(seq 0 "$(context::jq -r '(.snapshots.nodes | length) - 1')"); do
node_name="$(context::jq -r '.snapshots.nodes['"$i"'].filterResult.name')"
node_ip="$(context::jq -r '.snapshots.nodes['"$i"'].filterResult.ip')"
packets_lost=0
if ! ping -c 1 "$node_ip" -t 1 ; then
packets_lost=1
fi
cat >> "$METRICS_PATH" < {
"name": "node_packets_lost",
"add": $packets_lost,
"labels": {
"node": "$node_name"
}
}
END
done
}
我们遍历节点列表,获取节点名称和 IP 地址,对节点执行 ping 操作,然后将结果写入 Prometheus 指标端点。Shell-operator 可以通过将指标写入存储在 $METRICS_PATH 环境变量中指定路径下的文件中来将指标暴露到 Prometheus。
这样我们就使用最少的代码[5]在群集中实现了基本网络监视的方式。
排队机制
如果不讨论 shell-operator 必不可少的排队机制,那么将是不完整的。想象一下,shell-operator 响应集群中的某些事件而执行了一个钩子。
如果集群中发生了另一个事件,将会怎样? shell-operator 会运行该钩子的另一个实例吗? 例如,如果集群中同时发生五个事件,该怎么办? shell-operator 会并行运行它们吗? 消耗的资源(如内存和CPU)又如何呢?
幸运的是,shell-operator 具有内置的排队机制,所有事件都放入队列并顺序处理。
假设我们有两个钩子,第一个事件转到第一个钩子,处理完成后,队列前进。接下来的三个事件是另一个钩子,它们从队列中弹出并作为批处理传递给钩子。因此,该钩子接收事件数组 -更准确地说是绑定上下文数组。
另一种选择是将这些事件合并为一个较大的事件,绑定配置的group参数对此负责。

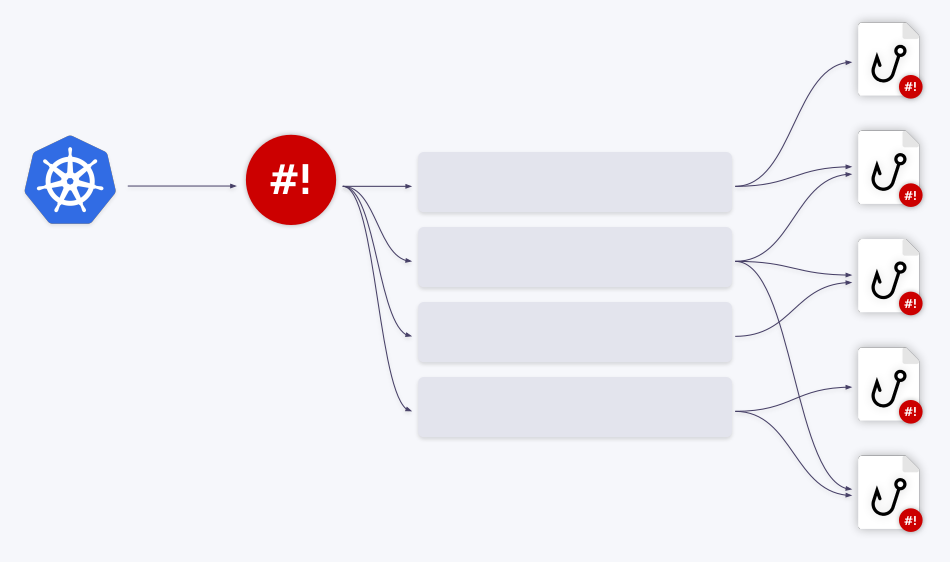
您要做的就是将queue字段插入绑定配置中,如果queue省略该名称,则钩子在default队列中运行,这种排队机制可以整体解决所有资源管理问题。
总结
在本文中,我们解释了什么是 shell-operator,展示了如何快速简单地创建它的 Kubernetes Operator,并提供了使用它的一些示例。
有关我们工具的详细信息以及快速入门指南,请参考其 GitHub 存储库。另外也可以看看我们的其他项目,例如,addon-operator[6] ,它可以绑定 Helm Charts,对其进行升级,监视各种 Chart 参数/值(以及控制 Helm Chart 的安装)并根据集群事件进行更新。
原文链接:https://medium.com/flant-com/meet-the-shell-operator-kubecon-36c14ba2f8fe
此外后台回复 shell 可以获取 shell-operator 完整的 PDF 文档。
参考资料
shell-operator 演讲视频: https://www.youtube.com/watch?v=we0s4ETUBLc
[2]shell-operator: https://github.com/flant/shell-operator
[3]shell_lib: https://github.com/flant/shell-operator/blob/master/shell_lib.sh
[4]示例仓储库: https://github.com/flant/examples/tree/master/2020/08-kubecon
[5]集群网络监控代码: https://github.com/flant/examples/blob/master/2020/08-kubecon/container/ping_exporter.sh
[6]addon-operator: https://github.com/flant/addon-operator
K8S进阶训练营,点击下方图片了解详情
