
DALL·E 2: 让 AI 获得想象力(一)
DALL·E 2 是 OpenAI 的最新工作,可以根据自然语言的描述创建逼真的图像和艺术。
DALL·E 2 也可以根据自然语言标题对现有图像进行逼真的编辑。它可以在考虑阴影、反射和纹理的同时添加和删除元素。
文本描述:An astronaut riding a horse in a photorealistic style
DALL·E 2 生成:

DALL·E 2 学习了图像和用于描述图像的文本之间的关系。它使用一种称为“扩散”的过程,该过程从随机点的图案开始,并在识别图像的特定方面时逐渐改变该图案朝向图像。
1. CLIP
论文地址:https://arxiv.org/abs/2103.00020
CLIP 是 OpenAI 2021 年发表的图文多模态模型,它通过互联网上大量可用的各种自然语言监督对各种图像进行训练(重新定义了 “Zero-Shot” 🐶)
通过对比学习,在 OpenAI 新制作的400亿数据集(💰)上预训练达到了SOTA。CLIP 如此强大的主要原因之一就在于 OpenAI 从互联网收集的 400 亿数据集
CLIP 预训练了一个图像编码器(ResNet50 或者 ViT)和一个文本编码器(Transformer 结构),以预测哪些图像与数据集中的哪些文本相匹配。然后使用这种行为将 CLIP 变成一个 Zero-Shot 分类器。
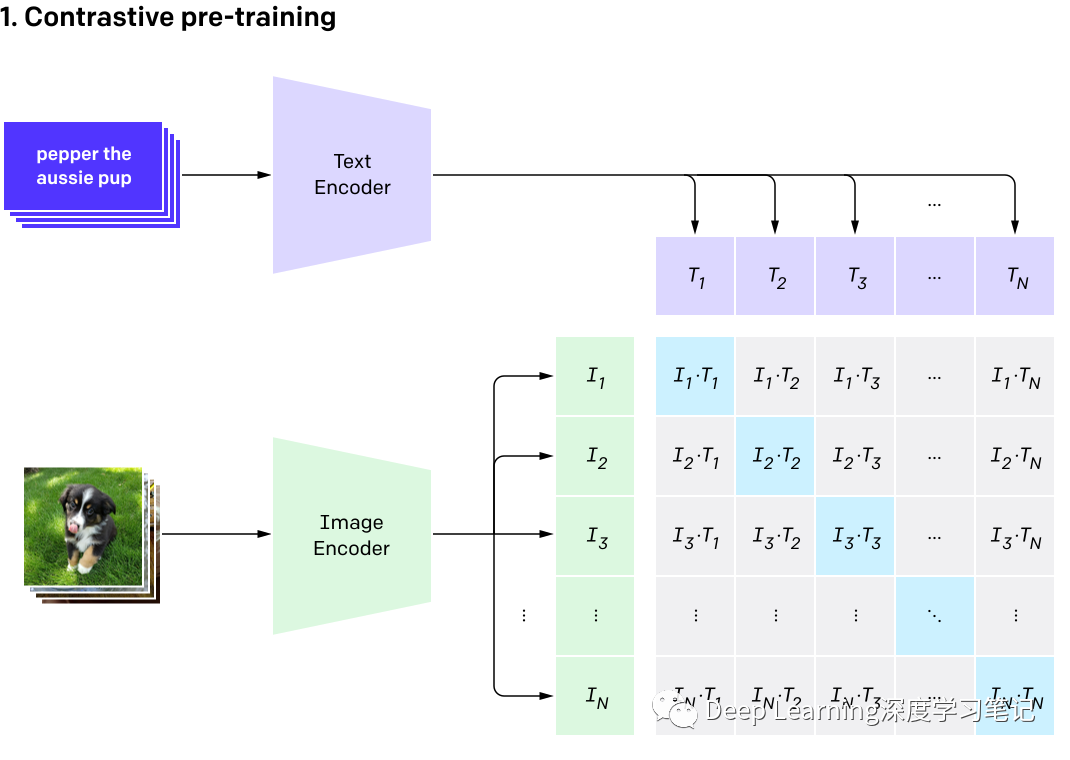
1.1 Contrastive Learning
CLIP 采取的方法非常简单且高效,将图片与对应的文本配对作为正样本,其他的图片文本对作为负样本进行对比学习。
给定一批 图像文本对,训练 CLIP 以预测批次中 可能的图像文本对中的哪一个实际发生。CLIP 通过联合训练图像编码器和文本编码器来学习多模态 embedding 空间,以最大化批次中 个正样本对的图像和文本 embedding 的余弦相似度,同时最小化 个负样本对 embedding 的余弦相似度。并在这些相似性分数上优化了对称交叉熵损失。
1.2 Prompt engineering
比较有意思的是除了互联网数据集,OpenAI 还应用了 prompt:
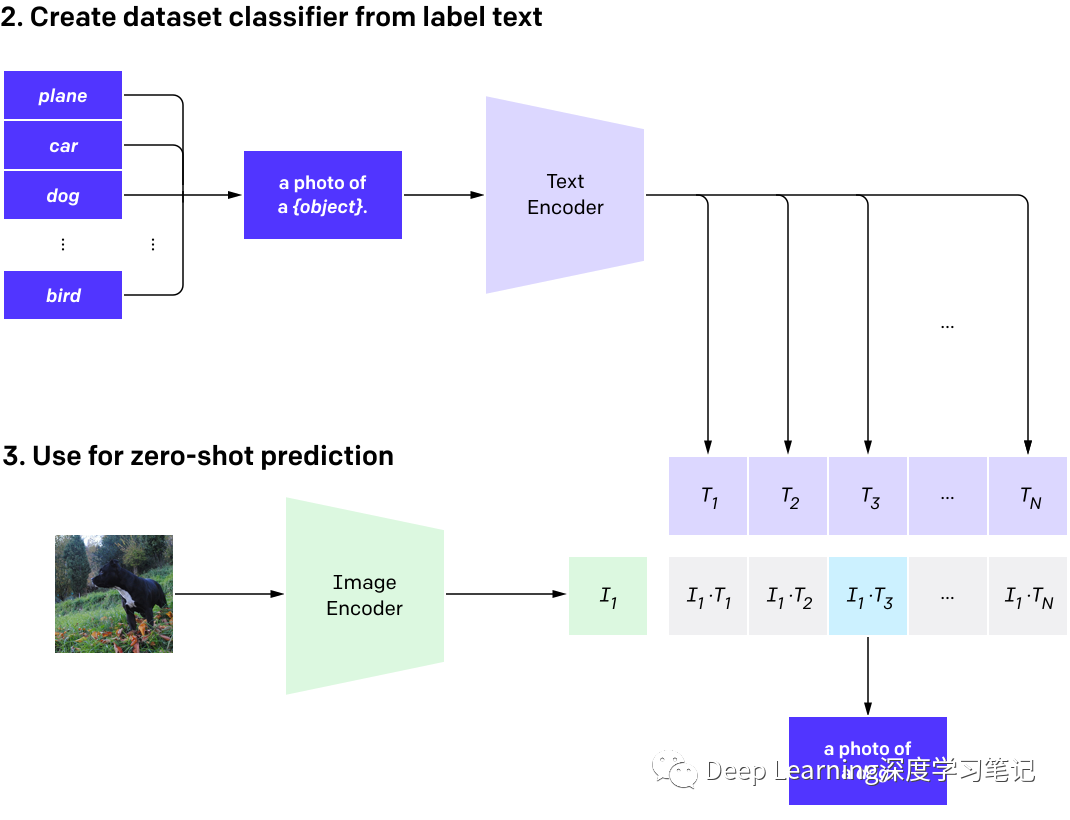
测试的数据集包含了 ImageNet 等,其图片对应一个分类标签,比如 猫狗等。OpenAI 设计了一个模版,如
A photo of a {label}.处理后将标签转化成一句话来处理,这样转化后在 ImageNet 带来 1.3% 的提升。对于 OCR 数据集进行类似处理使用诸如A satellite photo of a {label}.描述OpenAI 还设计了一种更复杂的 Assembly 的方法,使用 80 种模板。将每个词放进去,组合出 80 个句子,分别计算出 embedding 后做一个平均。在 ImageNet 上又有了 3.5% 的提升。
Prompt_Engineering_for_ImageNet.ipynb
2. Diffusion Model
参考资料:从DDPM到GLIDE:基于扩散模型的图像生成算法进展
DDPM 论文:https://arxiv.org/abs/2006.11239

扩散模型通常包括两个过程,从信号逐步到噪声的正向过程/扩散过程(forward/diffusion process)和从噪声逐步到信号的逆向过程(reverse process)。扩散模型大都是基于 DDPM 的框架所设计。
逆向过程:
从一张随机高斯噪声图片 开始,通过逐步去噪生成最终结果 。这个过程是一个马尔可夫链,可以被定义为:
其中,
这个过程可以理解为, 作为输入,预测高斯分布的均值和方差,再基于预测的分布进行随机采样得到 。通过不断预测和采样过程,最终生成一张真实的图片
正向/扩散过程
正向过程或者说扩散过程,采用的是一个固定的马尔可夫链的形式,即逐步地向图片添加高斯噪声:
其中,
在 DDPM 中, 是预先设置的定值参数。扩散过程有一个重要的特性,我们可以采样任意时刻 下的加噪结果 。将 以及 ,则我们可以得到:
使得我们可以直接获得任意程度的加噪图片,方便后续的训练。
2.1 Guided Diffusion
论文地址:https://arxiv.org/abs/2105.05233
通常而言,对于通用图像生成任务,加入类别条件能够比无类别条件生成获得更好的效果,这是因为加入类别条件的时候,实际上是大大减小了生成时的多样性。OpenAI 的Guided Diffusion 就提出了一种简单有效的类别引导的扩散模型生成方式。Guided Diffusion 的核心思路是在逆向过程的每一步,用一个分类网络对生成的图片进行分类,再基于分类分数和目标类别之间的交叉熵损失计算梯度,用梯度引导下一步的生成采样。这个方法一个很大的优点是,不需要重新训练扩散模型,只需要在前馈时加入引导既能实现相应的生成效果。
3. DALL·E 2
CLIP embedding 有一些理想的属性:它们对图像分布的转变是稳健的,有强大的 zero-shot 能力,并且已经被微调以在各种视觉和语言任务上取得 SOTA 。同时,扩散模型(diffusion models )推动了图像和视频生成任务的 SOTA。为了达到最佳效果,扩散模型利用了一种指导方法,以样本多样性为代价提高了样本的保真度(如对于图像,逼真度)。
作者结合这两种方法来进行文本条件的图像生成。首先训练一个扩散编码器(diffusion decoder)来逆向 CLIP 图像编码器。扩散编码器是非确定性的,并且在给定图像 embedding 可以生成多个图像。编码器和它的近似逆变器(approximate inverse,为解码器)的存在允许超越文本到图像翻译的能力。与 GAN 一样,对输入图像进行编码后解码会产生语义为相似的输出图像。还可以通过对多张输入图像编码后的 embedding 之间进行插值得到图片融合的效果。使用 CLIP embedding 空间的一个显著优势是能够通过在任何编码文本向量的方向上移动来对图像进行语义修改。而在 GAN 潜在空间中发现这些方向需要运气和大量的人工检查。此外,编码和解码图像还提供了一种工具,用于观察图像的哪些特征被 CLIP 识别或忽略。作者将其全文本条件的图像生成栈称为 unCLIP,因为它通过倒置 CLIP 图像编码器来生成图像。
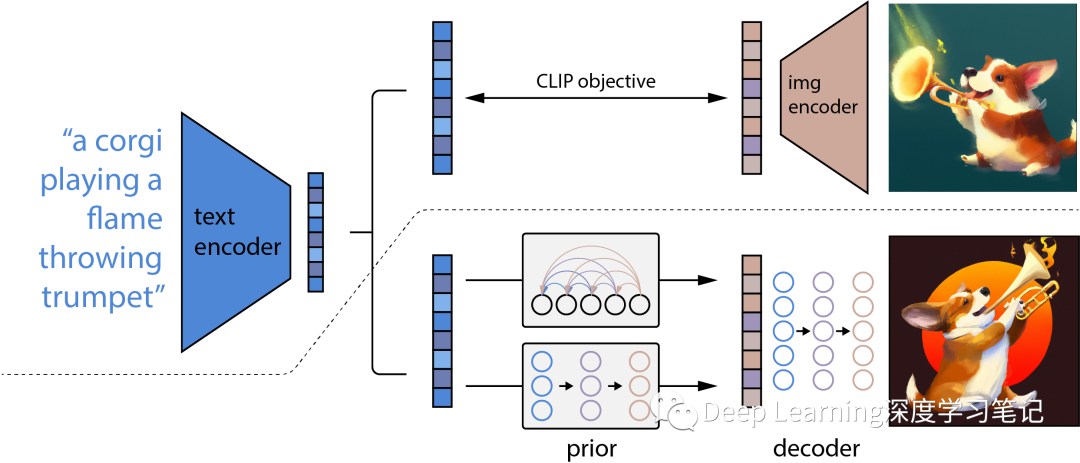 图 3. unCLIP 概述。在虚线上方,描述了 CLIP 训练过程,通过它模型学习了文本和图像的联合表示空间。在虚线下方,描述了文本到图像的生成过程:在生成图像 embedding 之前,首先将 CLIP 文本 embedding 输入到先验模型进行自回归或扩散,然后该 embedding 用于调节扩散解码器,产生最终图片。
图 3. unCLIP 概述。在虚线上方,描述了 CLIP 训练过程,通过它模型学习了文本和图像的联合表示空间。在虚线下方,描述了文本到图像的生成过程:在生成图像 embedding 之前,首先将 CLIP 文本 embedding 输入到先验模型进行自回归或扩散,然后该 embedding 用于调节扩散解码器,产生最终图片。
为了获得完整的图像生成模型,作者将 CLIP 图像 embedding 解码器与先验模型(prior model)相结合,该模型从给定的文本标题生成可能的 CLIP 图像 embedding。作者将其文本到图像系统与 DALL-E 和 GLIDE 等其他系统进行比较,发现样本在质量上与 GLIDE 相当,但在其中具有更大的多样性。作者还开发了在 embedding 空间中训练扩散先验的方法,并表明它们实现了与自回归先验相当的性能,同时具有更高的计算效率。
2.1 Method
训练数据集由图像 及其对应的标题 组成 。给定图像 ,让 和 分别为其 CLIP 图像和文本 embedding。设计的生成堆栈以使用两个组件从标题生成图像:
先验模型 以标题 为条件生成 CLIP 图像 embedding 解码器 以 CLIP 图像 embedding (以及可选的文本标题 )为条件生成图像 。
解码器在给定 CLIP 图像 embedding 的情况下反向生成图像,而先验模型学习图像 embedding 本身的生成模型。堆叠这两个组件产生一个生成模型 图像 给定标题 :
2.2.1 Prior
虽然解码器可以逆向 CLIP 图像 embedding 以生成图像 ,但作者需要一个从标题 生成 的先验模型,以便能够从文本标题生成图像。作者为先前的模型探索了两个不同的模型类型:
Autoregressive (AR) prior:CLIP 图像的 embedding 被转换为一系列离散编码,并根据标题 进行自回归预测。 Diffusion prior:连续向量 使用以标题 为条件的高斯扩散模型直接建模。
因为它是标题的确定性函数,除了标题之外,作者还可以在 CLIP 文本 embedding 上设置先验条件。为了提高样本质量,作者还通过在训练过程中 10% 的时间概率随机丢弃此文本条件信息,对 AR prior 和 Diffusion prior 使用无分类器采样。
为了更有效地从 AR prior 训练和采样,作者首先通过应用主成分分析 (PCA) 来降低 CLIP 图像 embedding 的维数。特别的是,作者发现当使用 SAM (Sharpness-Aware Minimization,是 Google 研究团队发表于 2021年 ICLR 的 spotlight 论文,核心想法是在 minimize 损失函数时,不仅仅追求 loss value的 minima ,同时考虑了 loss landscape 的平坦程度)训练 CLIP 时,CLIP 表示空间的秩显着降低,同时略微提高了评估指标。通过仅保留原始 1,024 个主成分中的 319 个,能够保留几乎所有信息。应用 PCA 后,作者通过降低特征值大小对主成分进行排序,将 319 个维度中的每一个量化为 1,024 个离散桶,并使用带有因果注意掩码(causal attention mask)的 Transformer 模型预测结果序列。这使得推理期间预测的 token 数量减少了三倍,并提高了训练稳定性。
作者通过将文本标题和 CLIP 文本 embedding 编码为序列的前缀来调整 AR prior。此外,作者在文本 embedding 和图像 embedding 之间添加一个表示(量化)点积的 token,。这允许在更高的点积上调整模型,因为更高的文本图像点积对应于更好地描述图像的标题。
对于 diffusion prior,作者在一个序列上训练一个带有因果注意掩码的解码器 Transformer,该序列依次包括:编码文本、CLIP 文本 embedding、扩散时间步的 embedding、噪声 CLIP 图像 embedding、最终 embedding(来自 Transformer 的输出用于预测无噪声的 CLIP 图像嵌入)。作者选择不像 AR prior 那样在 上调节 diffusion prior;相反,通过生成两个 样本并选择一个与 具有更高点积的样本来提高采样时间的质量。而不是使用 Ho 等人的预测公式。[25],我们发现最好训练我们的模型直接预测无噪声 zi,并在该预测上使用均方误差损失
参考资料
https://openai.com/blog/clip/ https://openai.com/dall-e-2/