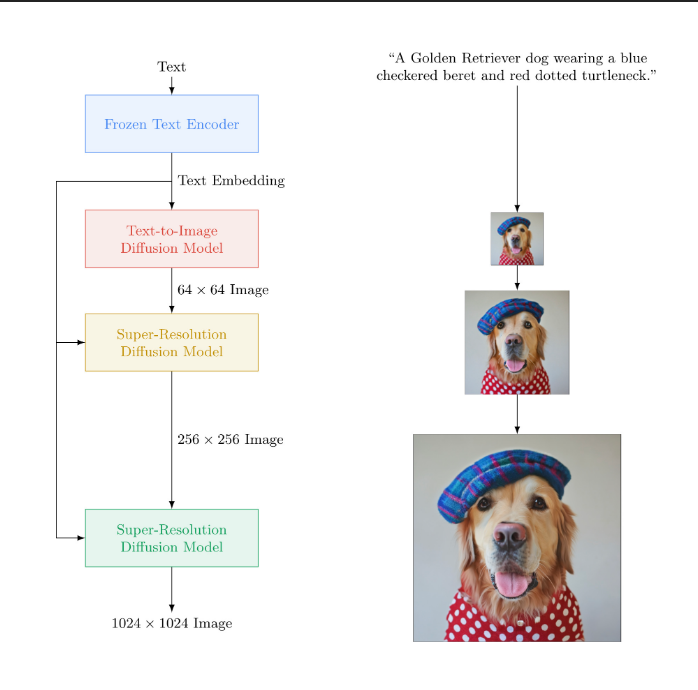
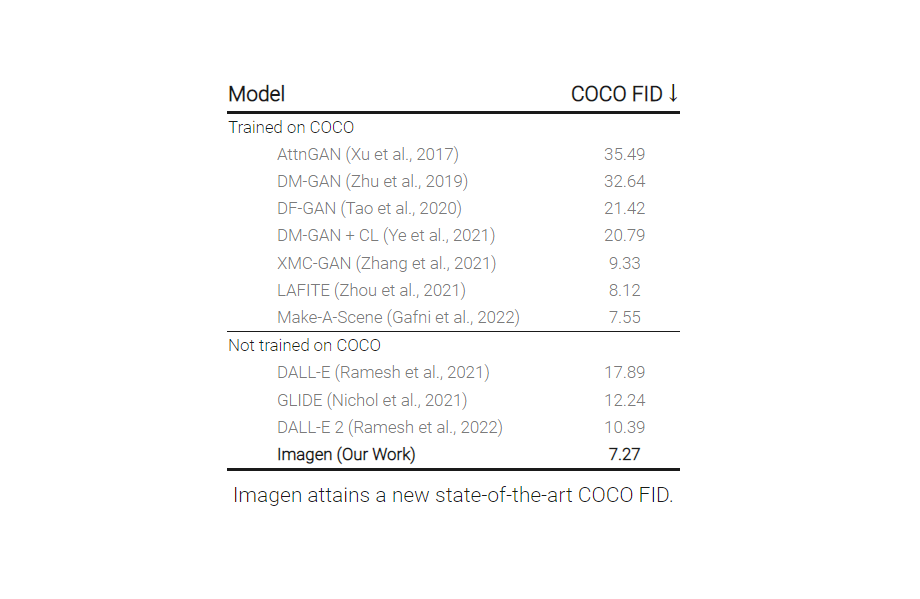
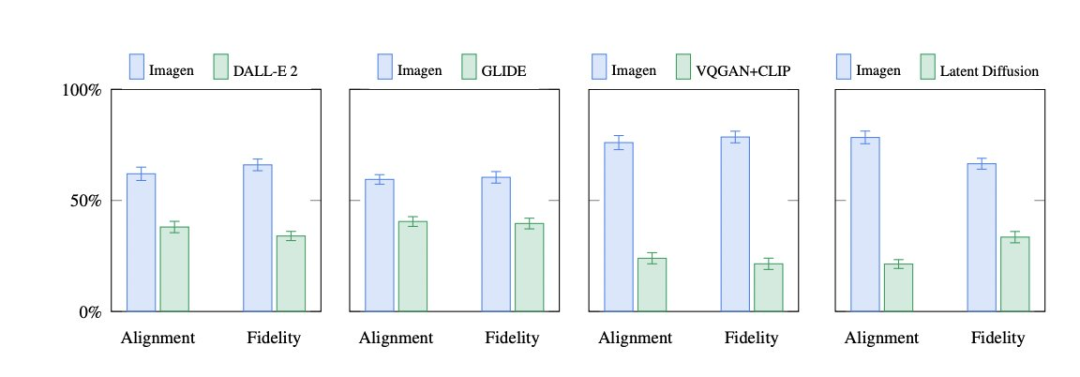
大数据文摘转载自AI科技评论作者:李梅、王玥编辑:陈彩娴 文本生成图像模型界又出新手笔! 这次的主角是Google Brain推出的 Imagen,再一次突破人类想象力,将文本生成图像的逼真度和语言理解提高到了前所未有的新高度!比前段时间OpeAI家的DALL·E 2更强! 话不多说,我们来欣赏这位AI画师的杰作~ A brain riding a rocketship heading towards the moon.(一颗大脑乘着火箭飞向月球。) A dragon fruit wearing karate belt in the snow.(在雪地里戴着空手道腰带的火龙果) A marble statue of a Koala DJ in front of a marble statue of a turntable. The Koala has wearing large marble headphones.(一只带着巨大耳机的考拉DJ的大理石雕像站在一个大理石转盘前。) An art gallery displaying Monet paintings. The art gallery is flooded. Robots are going around the art gallery using paddle boards.(陈列莫奈画作的美术馆被水淹没。机器人正在使用桨板在美术馆里划行。) A giant cobra snake on a farm.The snake is made out of corn(农场里有一条巨大的玉米构成的眼镜蛇。) Teddy bears swimming at the Olympics 400m Butterfly event.(泰迪熊在奥运会400米蝶泳项目中游泳。) 以及更多...... 给出同样的文本提示,Imagen还可以生成不同类别的图像。比如下面这些图中,各组图片在物品的颜色、空间位置、材质等范畴上都不太相同。 Imagen的工作原理 论文地址:https://gweb-research-imagen.appspot.com/paper.pdf