本文约2100字,建议阅读5分钟
将文本生成图像的逼真度和语言理解提高到了前所未有的新高度!
这次的主角是Google Brain推出的 Imagen,再一次突破人类想象力,将文本生成图像的逼真度和语言理解提高到了前所未有的新高度!比前段时间OpeAI家的DALL·E 2更强!A brain riding a rocketship heading towards the moon.(一颗大脑乘着火箭飞向月球。)A dragon fruit wearing karate belt in the snow.(在雪地里戴着空手道腰带的火龙果)A marble statue of a Koala DJ in front of a marble statue of a turntable. The Koala has wearing large marble headphones.(一只带着巨大耳机的考拉DJ的大理石雕像站在一个大理石转盘前。)
An art gallery displaying Monet paintings. The art gallery is flooded. Robots are going around the art gallery using paddle boards.(陈列莫奈画作的美术馆被水淹没。机器人正在使用桨板在美术馆里划行。)A giant cobra snake on a farm.The snake is made out of corn(农场里有一条巨大的玉米构成的眼镜蛇。)Teddy bears swimming at the Olympics 400m Butterfly event.(泰迪熊在奥运会400米蝶泳项目中游泳。)给出同样的文本提示,Imagen还可以生成不同类别的图像。比如下面这些图中,各组图片在物品的颜色、空间位置、材质等范畴上都不太相同。论文地址:https://gweb-research-imagen.appspot.com/paper.pdf
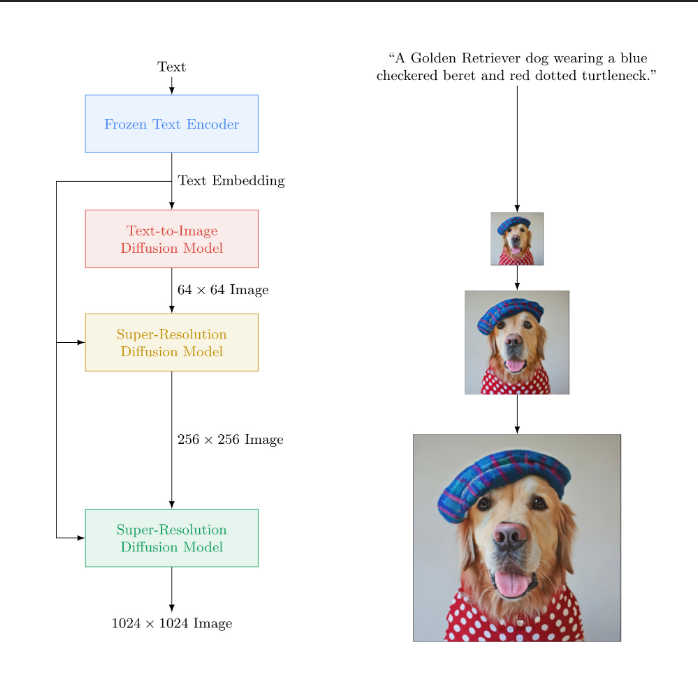
Imagen的可视化流程
Imagen基于大型transformer语言模型在理解文本方面的能力和扩散模型在高保真图像生成方面的能力。在用户输入文本要求后,如“一只戴着蓝色格子贝雷帽和红色波点高领毛衣的金毛犬”,Imagen先是使用一个大的冻结(frozen)T5-XXL 编码器将这段输入文本编码为嵌入。然后条件扩散模型将文本嵌入映射到64×64的图像中。Imagen进一步利用文本条件超分辨率扩散模型对64×64的图像进行升采样为256×256,再从256×256升到1024×1024。结果表明,带噪声调节增强的级联扩散模型在逐步生成高保真图像方面效果很好。图注:输入“一只戴着蓝色格子贝雷帽和红色波点高领毛衣的金毛犬”后Imagen的动作
图注:64 × 64生成图像的超分辨率变化。对于生成的64 × 64图像,将两种超分辨率模型分别置于不同的提示下,产生不同的上采样变化
大型预训练语言模型×级联扩散模型
Imagen使用在纯文本语料中进行预训练的通用大型语言模型(例如T5),它能够非常有效地将文本合成图像:在Imagen中增加语言模型的大小,而不是增加图像扩散模型的大小,可以大大地提高样本保真度和图像-文本对齐。- 大型预训练冻结文本编码器对于文本到图像的任务来说非常有效;
- 缩放预训练的文本编码器大小比缩放扩散模型大小更重要;
- 引入一种新的阈值扩散采样器,这种采样器可以使用非常大的无分类器指导权重;
- 引入一种新的高效U-Net架构,这种架构具有更高的计算效率、更高的内存效率和更快的收敛速度;
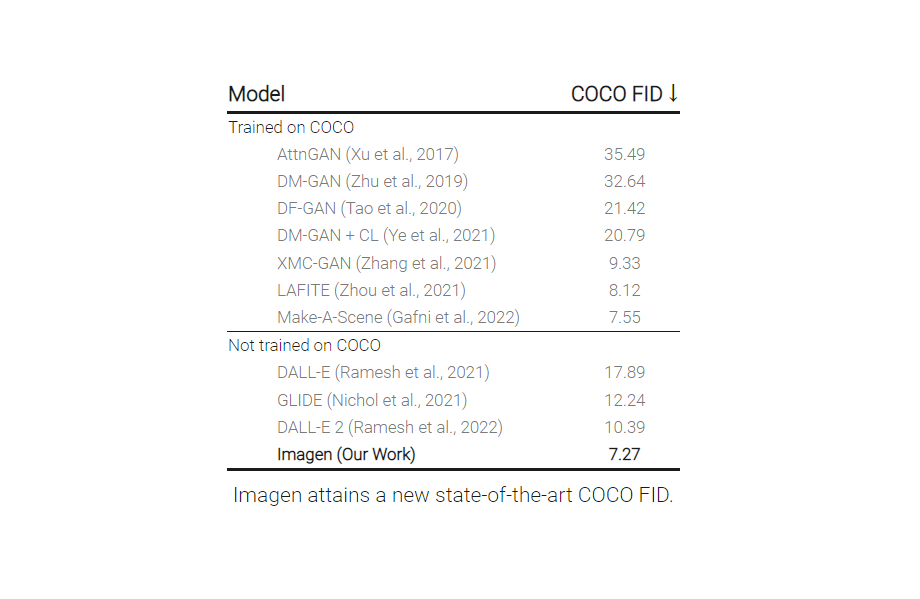
- Imagen在COCO数据集上获得了最先进的FID分数7.27,而没有对COCO进行任何训练,人类评分者发现,Imagen样本在图像-文本对齐方面与COCO数据本身不相上下。
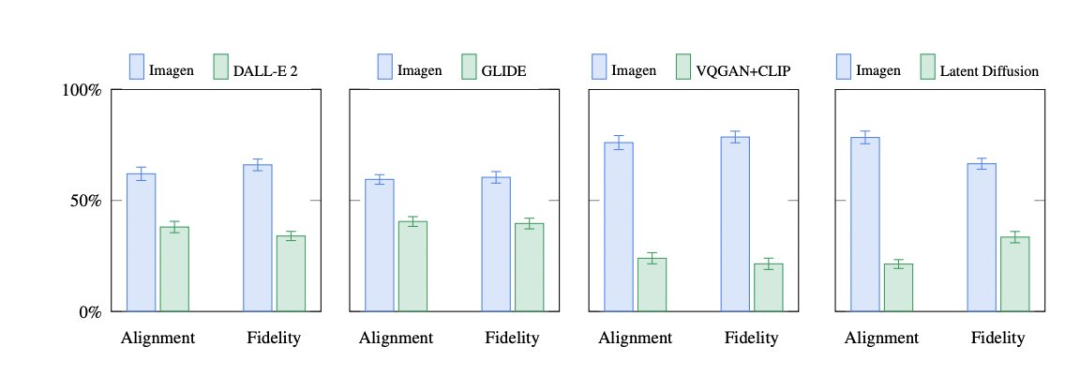
为了更深入地评估文本到图像模型,Google Brain 引入了DrawBench,这是一个全面的、具有挑战性的文本到图像模型基准。通过DrawBench,他们比较了Imagen与VQ-GAN+CLIP、Latent Diffusion Models和DALL-E 2等其他方法,发现人类评分者在比较中更喜欢Imagen而不是其他模型,无论是在样本质量上还是在图像-文本对齐方面。- 对语意合成性、基数性、空间关系、长文本、生词和具有挑战性的提示几方面提出了系统化的考验;
- 由于图像-文本对齐和图像保真度的优势,相对于其他方法,用户强烈倾向于使用Imagen。
图注:Imagen与DALL-E 2、GLIDE、VQ-GAN+CLIP和Latent Diffusion Models在DrawBench上的比较:用户对图像-文本对齐和图像逼真度的偏好率(95%置信区间)Imagen与DALL-E 2 生成图像的比较示例 :图注:“外星人绑架奶牛,将其吸入空中盘旋”(上);“一个被猫绊倒的希腊男性的雕塑”(下)对于涉及颜色的文本提示,Imagen生成的图像也比DALL-E 2更优。DALL-E 2通常很难为目标图像分配正确的颜色,尤其是当文本提示中包含多个对象的颜色提示时,DALL-E 2会容易将其混淆。图注:Imagen和DALL-E 2从颜色类文本生成图像的比较。“一本黄色书籍和一个红花瓶”(上);“一个黑色苹果和一个绿色双肩包”(下)而在带引号文本的提示方面,Imagen生成图像的能力也明显优于DALL-E 2。图注:Imagen 和 DALL-E 2 从带引号文本生成图像的比较。“纽约天际线,天上有烟花写成的“Hello World”字样”(上);“一间写着Time to Image的店面”(下)像Imagen这样从文本生成图像的研究面临着一系列伦理挑战。首先,文本-图像模型的下游应用多种多样,可能会从多方面对社会造成影响。Imagen以及一切从文本生成图像的系统都有可能被误用的潜在风险,因此社会要求开发方提供负责任的开源代码和演示。基于以上原因,Google决定暂时不发布代码或进行公开演示。而在未来的工作中,Google将探索一个负责任的外部化框架,从而将各类潜在风险最小化。其次,文本到图像模型对数据的要求导致研究人员严重依赖于大型的、大部分未经整理的、网络抓取的数据集。虽然近年来这种方法使算法快速进步,但这种性质的数据集往往会夹带社会刻板印象、压迫性观点、对边缘群体有所贬损等“有毒”信息。为了去除噪音和不良内容(如色情图像和“有毒”言论),Google对训练数据的子集进行了过滤,同时Google还使用了众所周知的LAION-400M数据集进行过滤对比,该数据集包含网络上常见的不当内容,包括色情图像、种族主义攻击言论和负面社会刻板印象。Imagen依赖于在未经策划的网络规模数据上训练的文本编码器,因此继承了大型语言模型的社会偏见和局限性。这说明Imagen可能存在负面刻板印象和其他局限性,因此Google决定,在没有进一步安全措施的情况下,不会将Imagen发布给公众使用。https://gweb-research-imagen.appspot.com/
编辑:于腾凯