
Meta AI:让手绘小人动起来

来源:公众号 新智元 授权
【导读】想让画中的「纸片人」有生命,Meta AI来搞定!昨日,Meta AI宣布了一种独创性方法,只需几分钟,就能动画化儿童手绘的角色,效果拔群。

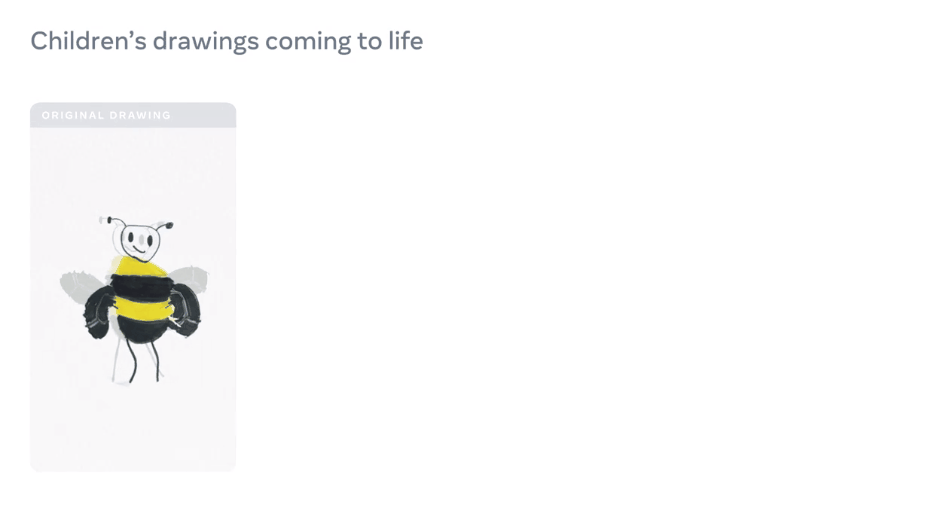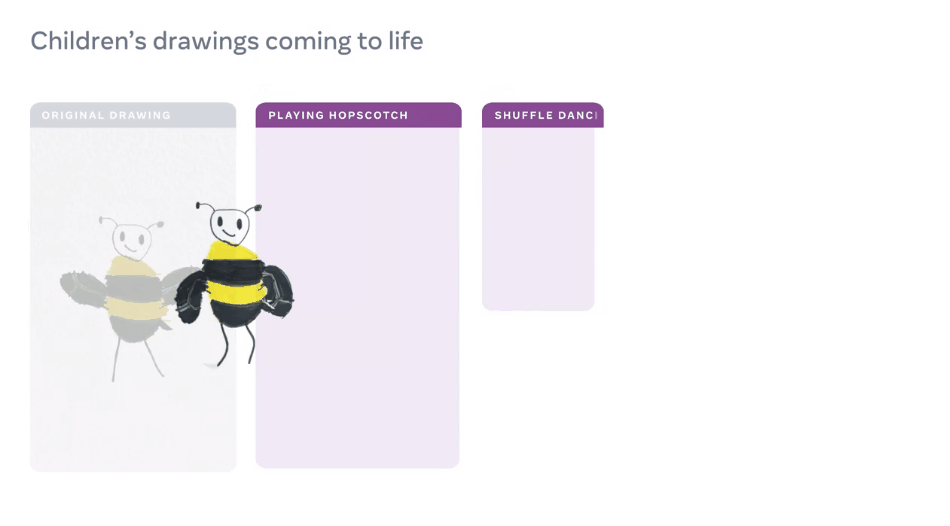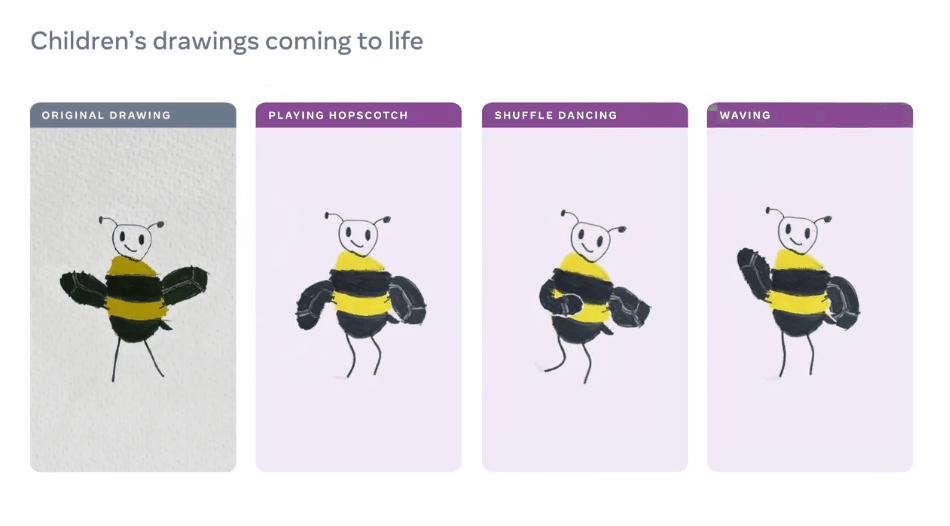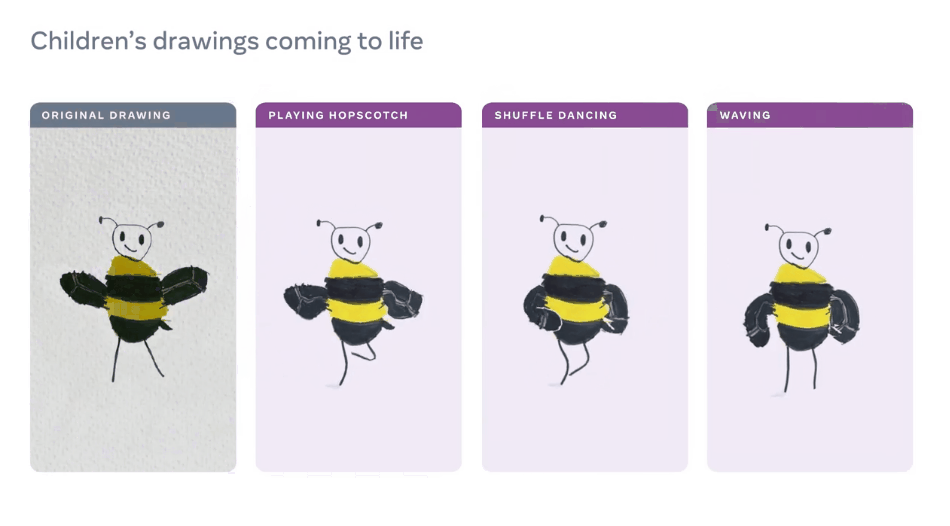


AI动画工具在儿童绘画上翻车?



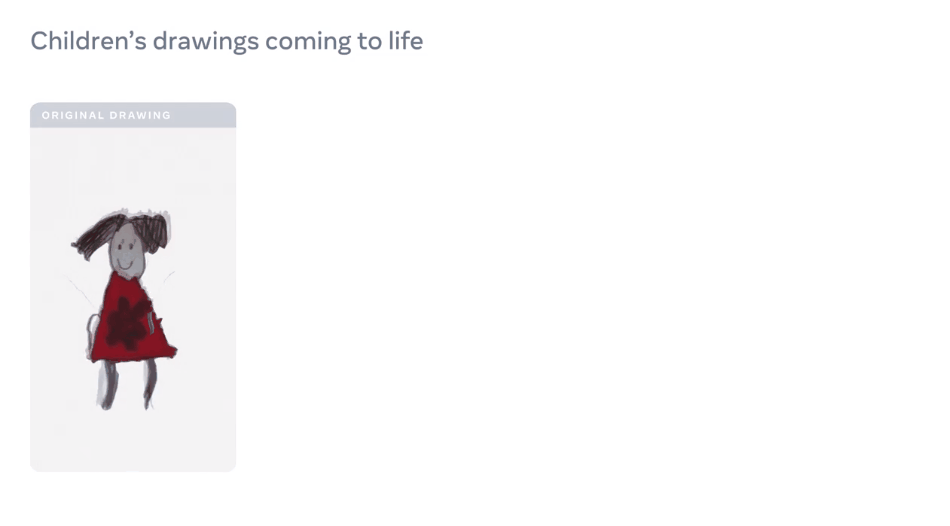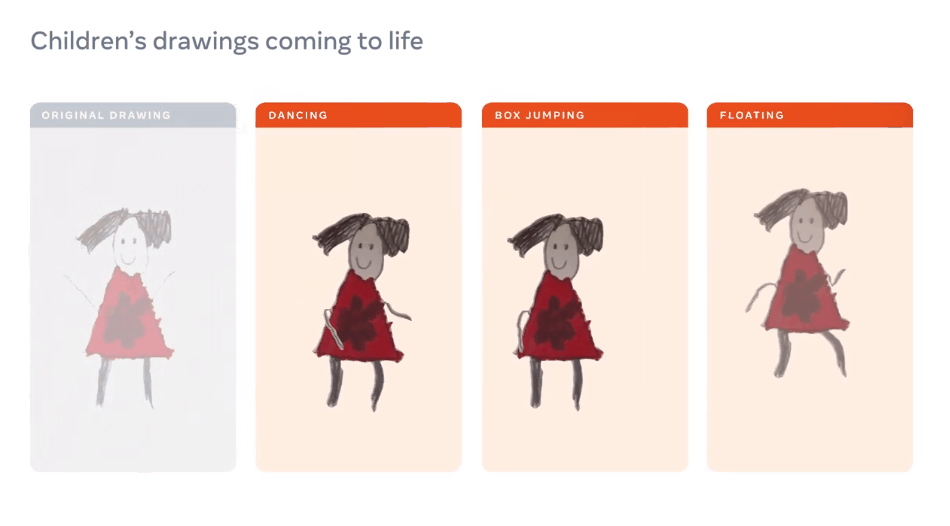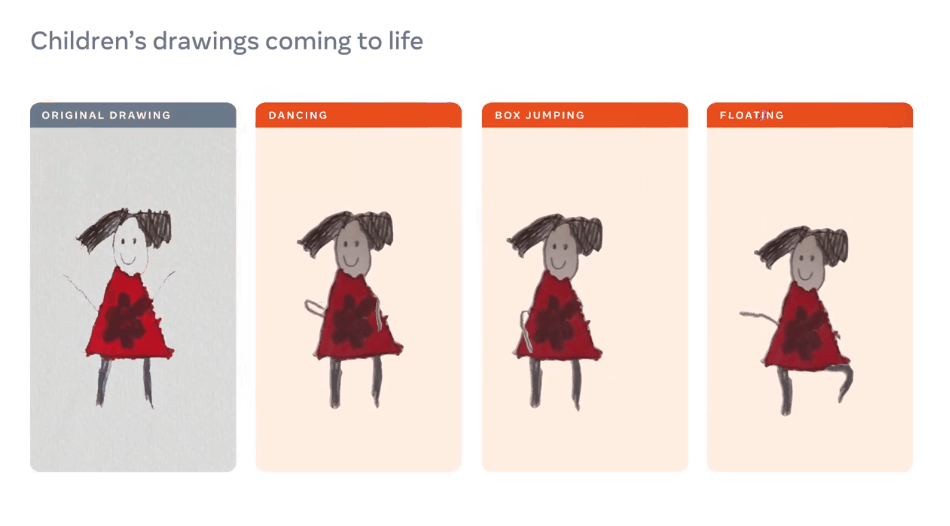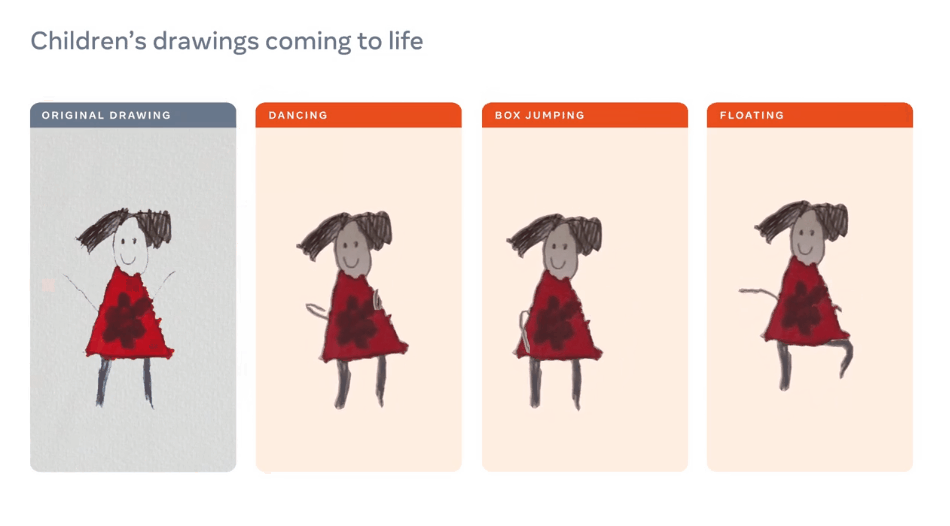
手绘变动画四步走
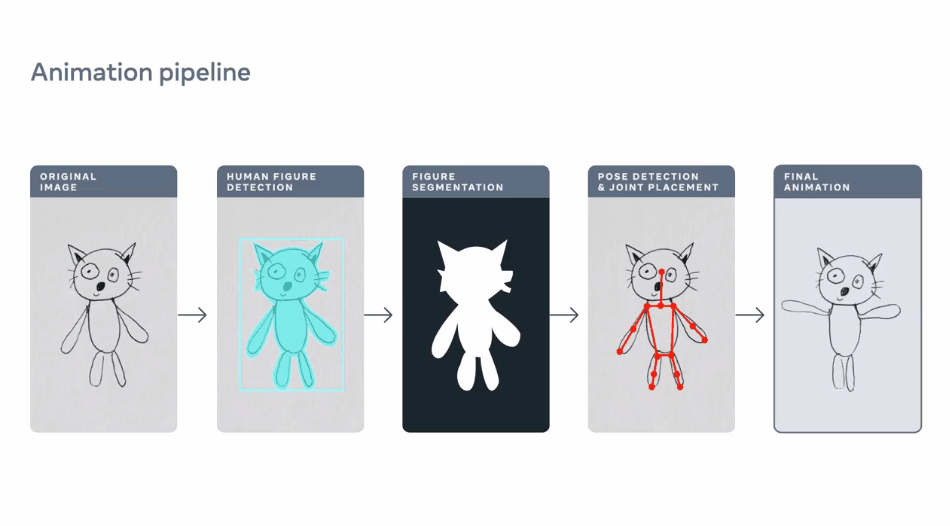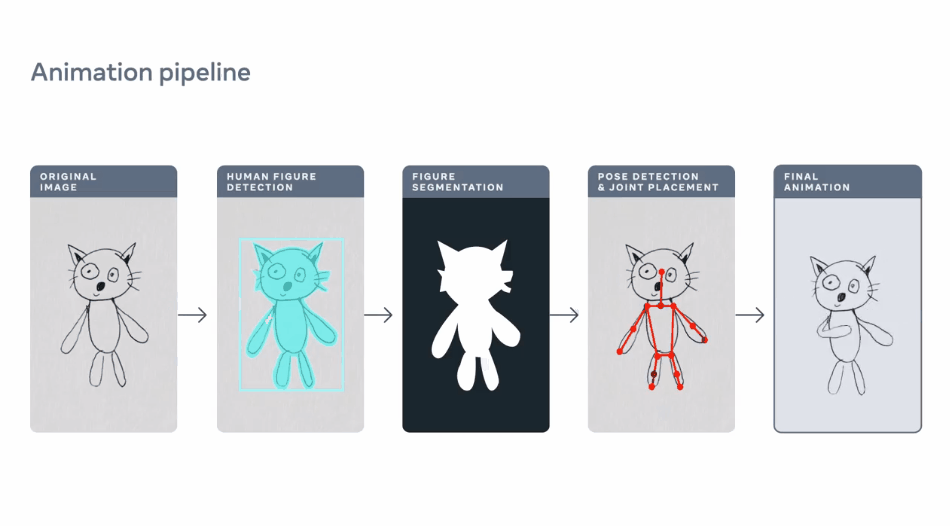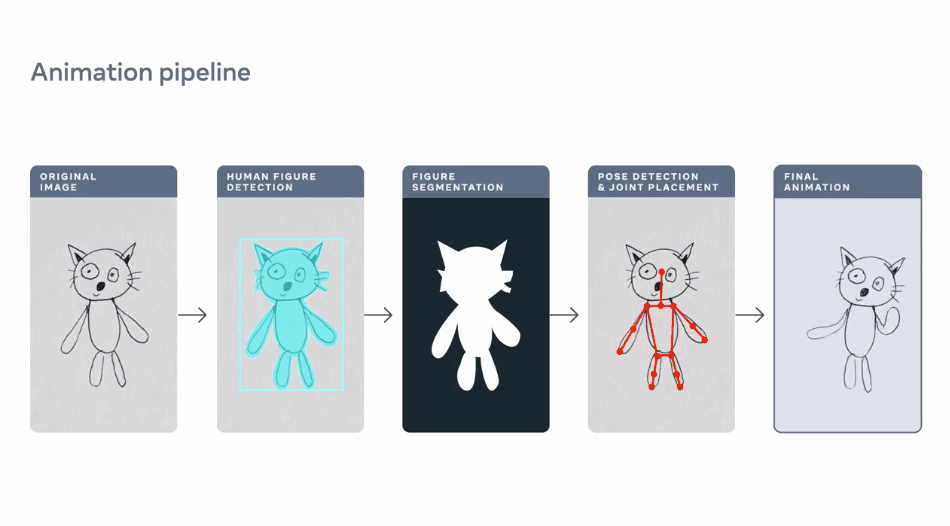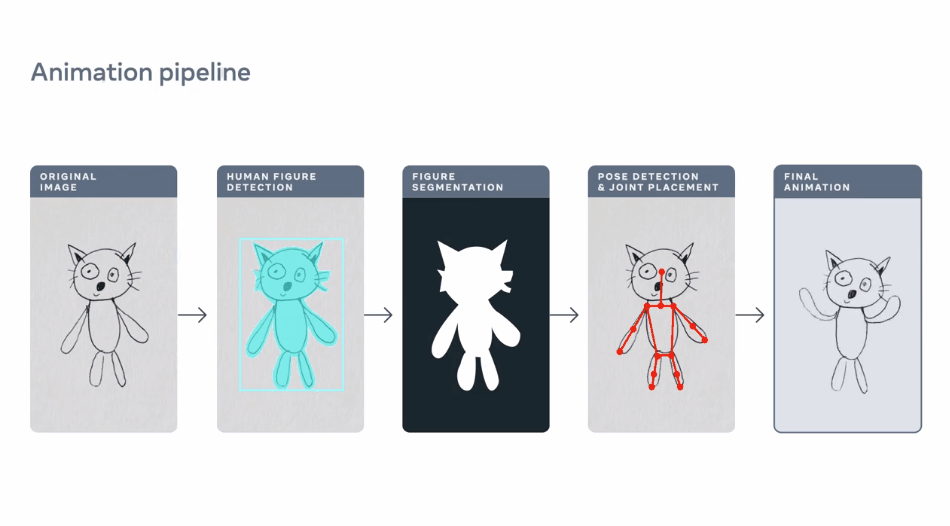
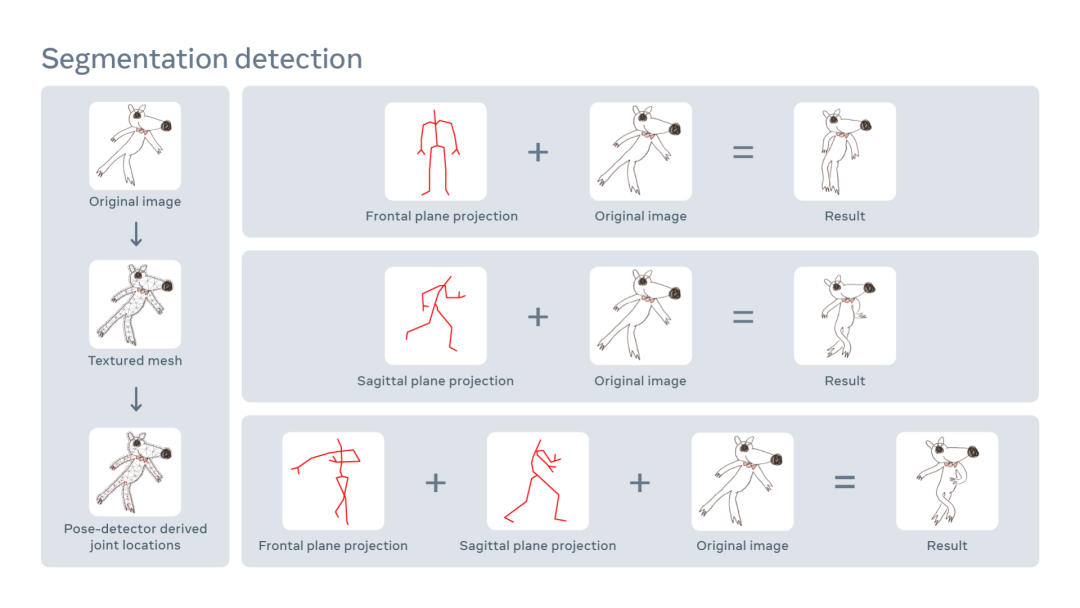
通过物体检测识别人形

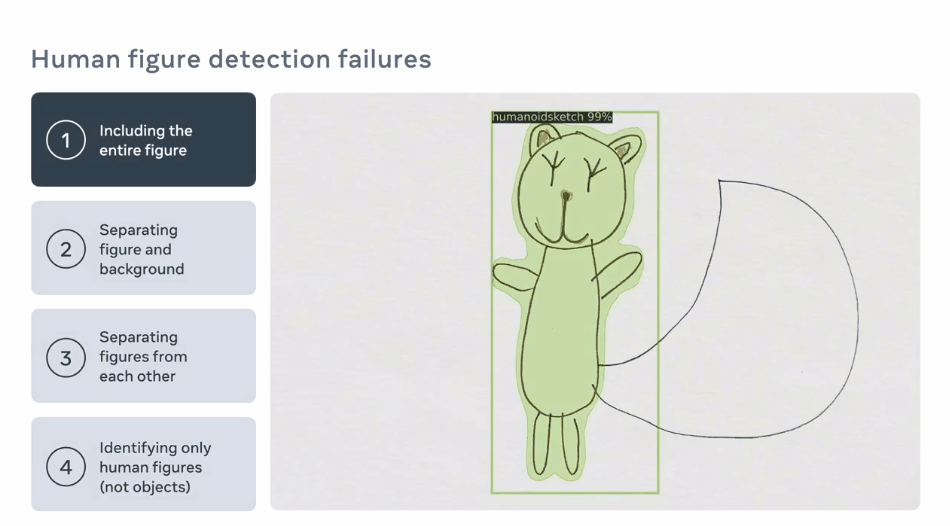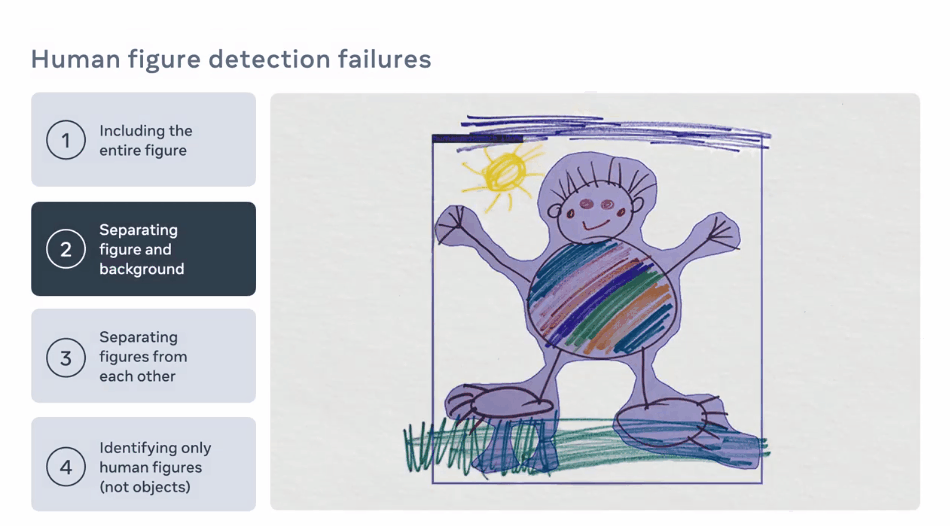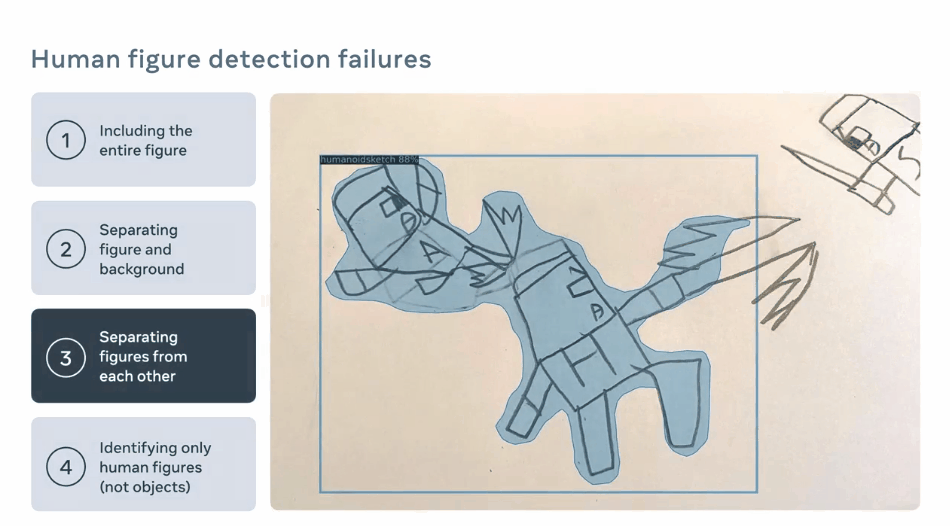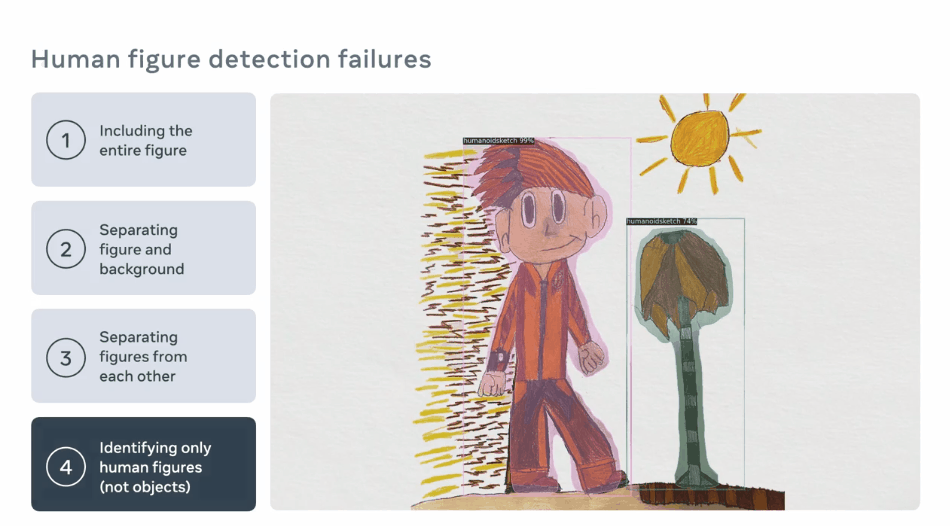
使用角色mask从场景中提升人形

通过「装配」为动画做准备

三维运动捕捉制作2D人物动画
用AI制作更复杂的动画
参考资料:
https://ai.facebook.com/blog/using-ai-to-bring-childrens-drawings-to-life/
猜您喜欢:
附下载 |《TensorFlow 2.0 深度学习算法实战》
评论