
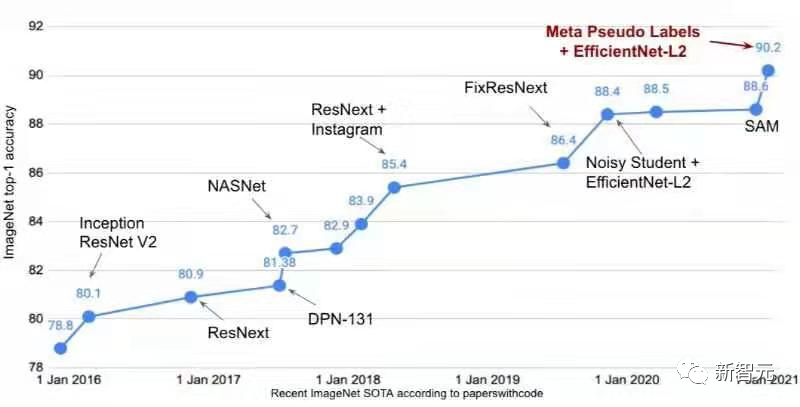
ImageNet零样本准确率首次超过80%,地表最强开源CLIP模型更新

新智元报道
新智元报道
【新智元导读】开源模型OpenCLIP达成ImageNet里程碑成就!
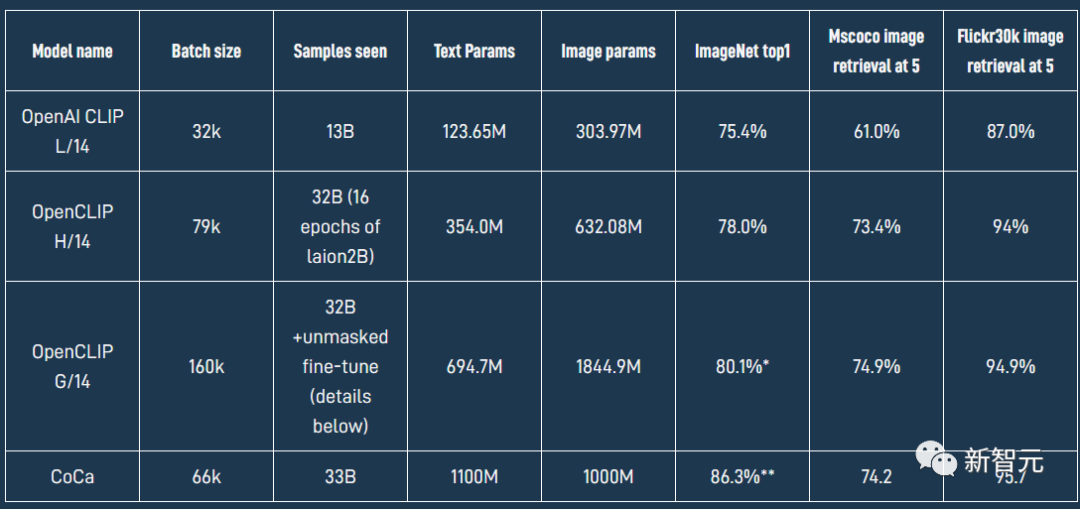
模型地址:https://huggingface.co/laion/CLIP-ViT-bigG-14-laion2B-39B-b160k
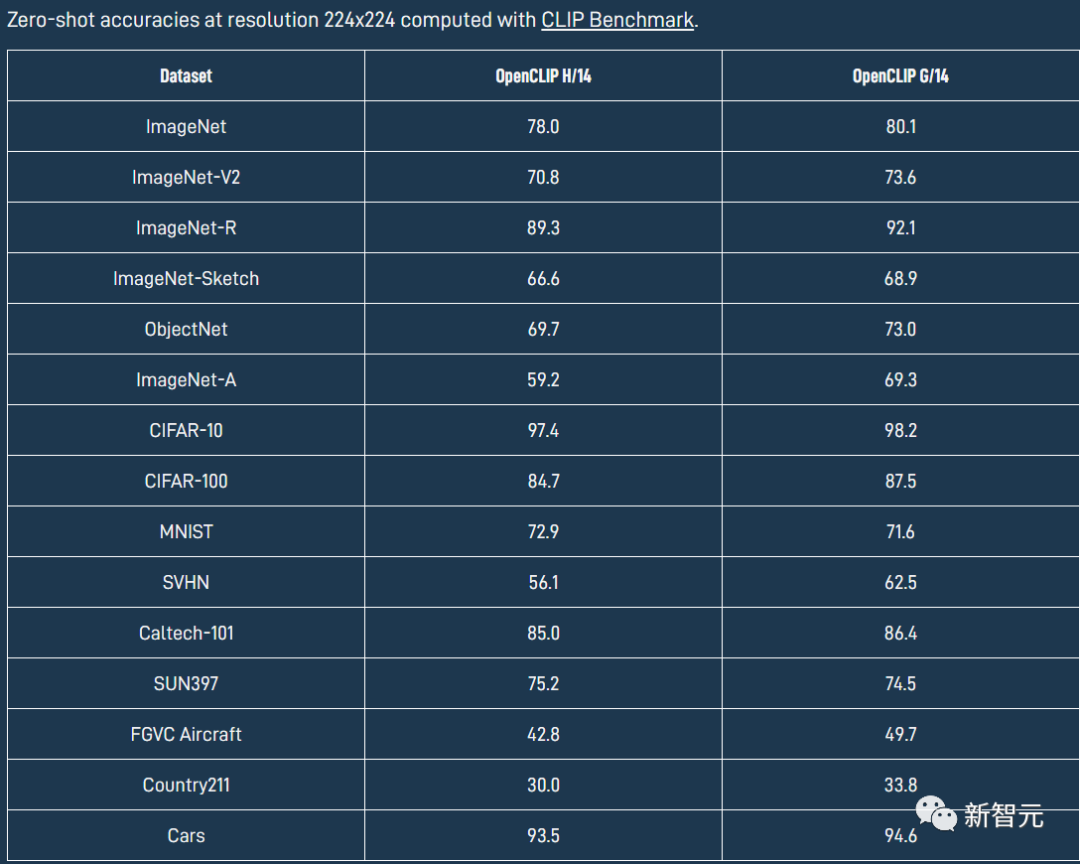
Zero-shot能力
Zero-shot能力
CLIP为何能Zero-Shot
CLIP为何能Zero-Shot
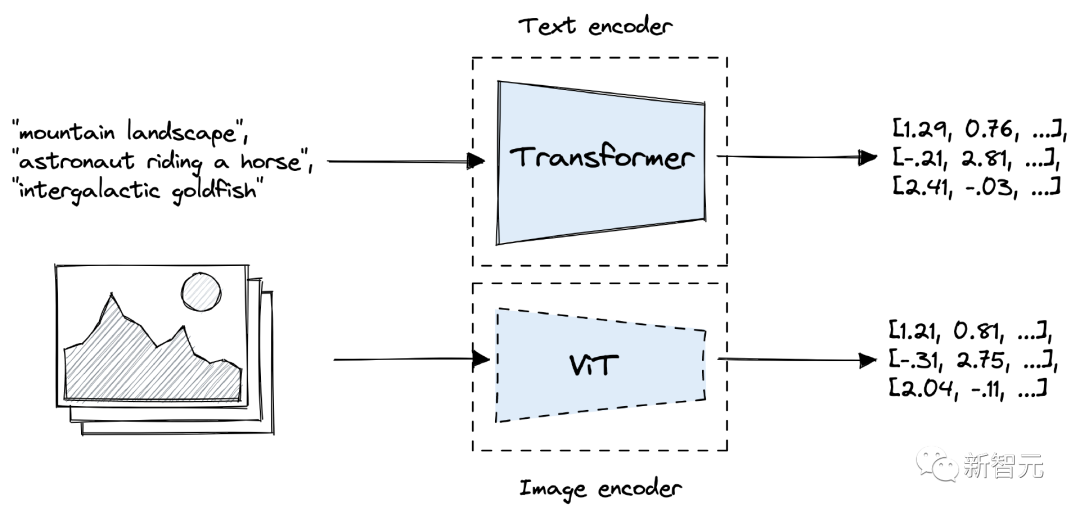
对比语言-图像预训练(CLIP, Contrastive Language-Image Pretraining)是 OpenAI 于2021年发布的一个主要基于Transformer的模型。
CLIP 由两个模型组成,一个Transformer编码器用于将文本转换为embedding,以及一个视觉Transformer(ViT)用于对图像进行编码。
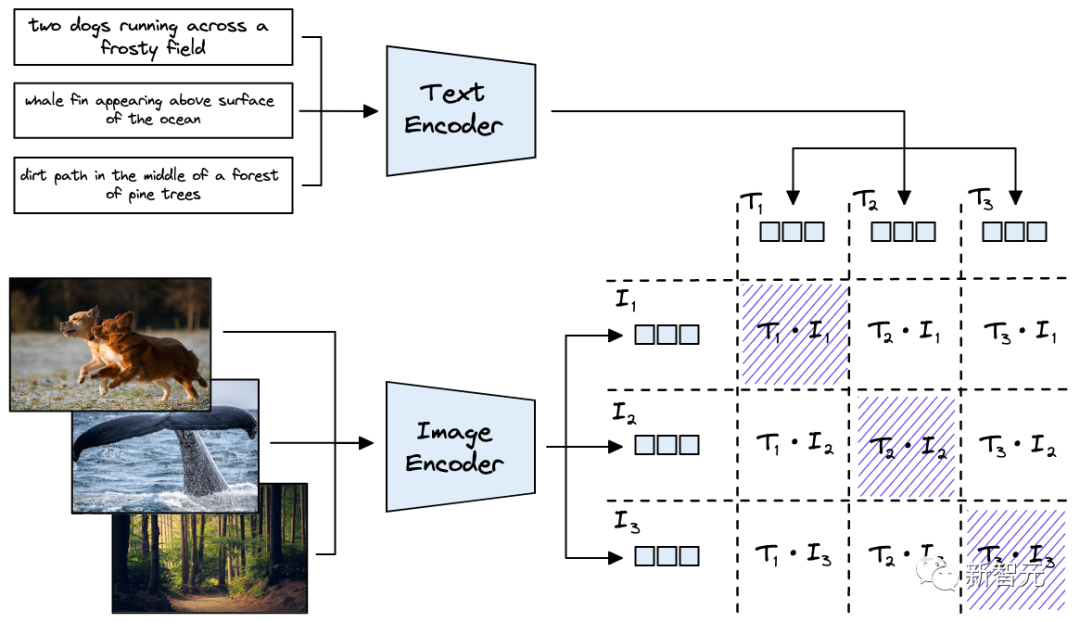
CLIP内的文本和图像模型在预训练期间都进行了优化,以在向量空间中对齐相似的文本和图像。在训练过程中,将数据中的图像-文本对在向量空间中将输出向量推得更近,同时分离不属于一对的图像、文本向量。
CLIP与一般的分类模型之间有几个区别:
首先,OpenAI 使用从互联网上爬取下来的包含4亿文本-图像对的超大规模数据集进行训练,其好处在于:
1. CLIP的训练只需要「图像-文本对」而不需要特定的类标签,而这种类型的数据在当今以社交媒体为中心的网络世界中非常丰富。
2. 大型数据集意味着 CLIP 可以对图像中的通用文本概念进行理解的能力。
3. 文本描述(text descriptor)中往往包含图像中的各种特征,而不只是一个类别特征,也就是说可以建立一个更全面的图像和文本表征。
上述优势也是CLIP其建立Zero-shot能力的关键因素,论文的作者还对比了在ImageNet上专门训练的 ResNet-101模型和 CLIP模型,将其应用于从ImageNet 派生的其他数据集,下图为性能对比。
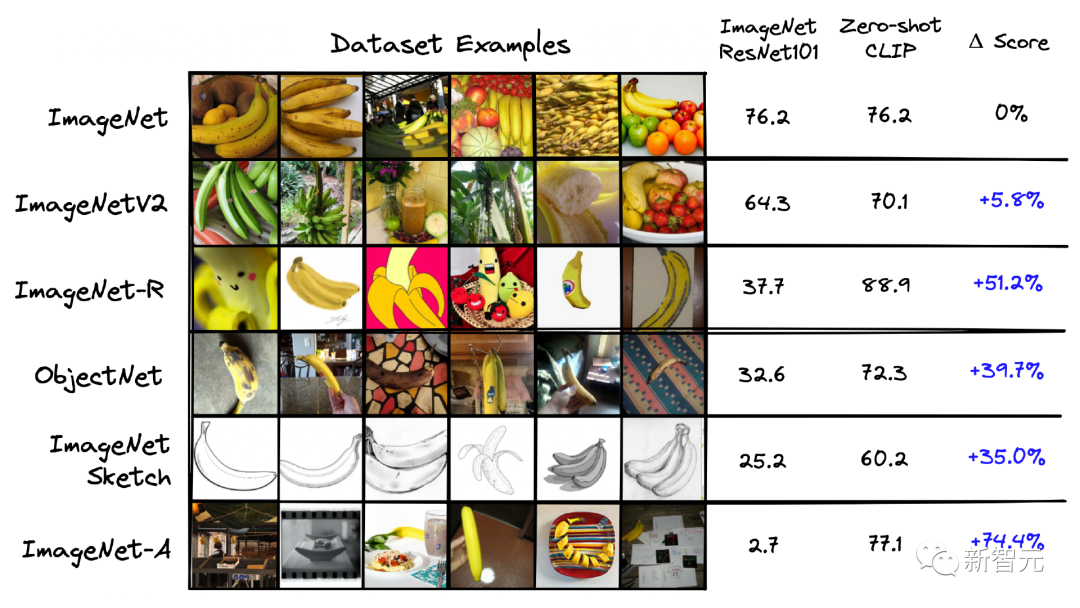
可以看到,尽管 ResNet-101是在ImageNet上进行训练的,但它在相似数据集上的性能要比 CLIP 在相同任务上的性能差得多。
在将 ResNet 模型应用于其他领域时,一个常用的方法是「linear probe」(线性探测),即将ResNet模型最后几层所学到的特性输入到一个线性分类器中,然后针对特定的数据集进行微调。
在CLIP论文中,线性探测ResNet-50与zero-shot的CLIP 进行了对比,结论是在相同的场景中,zero-shot CLIP 在多个任务中的性能都优于在ResNet-50中的线性探测。
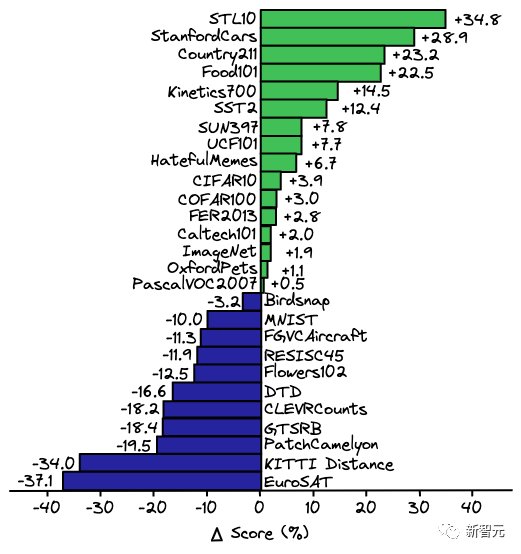
不过值得注意的是,当给定更多的训练样本时,Zero-shot并没有优于线性探测。
用CLIP做Zero-shot分类
用CLIP做Zero-shot分类
从上面的描述中可以知道,图像和文本编码器可以创建一个512维的向量,将输入的图像和文本输入映射到相同的向量空间。
用CLIP做Zero-shot分类也就是把类别信息放入到文本句子中。
举个例子,输入一张图像,想要判断其类别为汽车、鸟还是猫,就可以创建三个文本串来表示类别:
T1代表车:a photo of a car
T2代表鸟:a photo of a bird
T3代表猫:a photo of a cat
将类别描述输入到文本编码器中,就可以得到可以代表类别的向量。
假设输入的是一张猫的照片,用 ViT 模型对其进行编码获取图像向量后,将其与类别向量计算余弦距离作为相似度,如果与T3的相似度最高,就代表图像的类别属于猫。
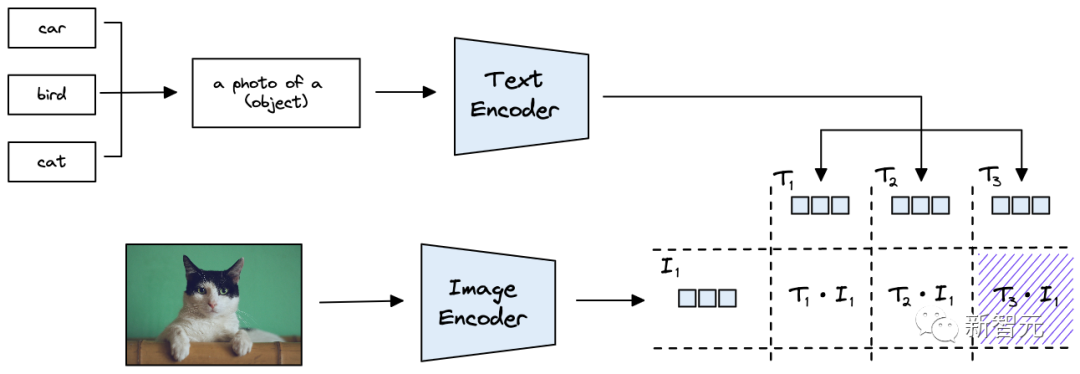
可以看到,类别标签并不是一个简单的词,而是基于模板「a photo of a {label}」的格式重新改写为一个句子,从而可以扩展到不受训练限制的类别预测。
实验中,使用该prompt模板在ImageNet的分类准确性上提高了1.3个百分点,但prompt模板并不总是能提高性能,在实际使用中需要根据不同的数据集进行测试。
Python实现
Python实现
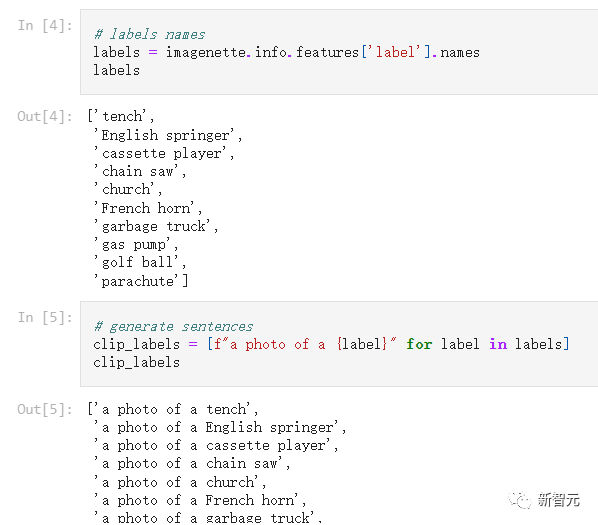
想要快速使用CLIP做zero-shot分类也十分容易,作者选取了Hugging Face中的frgfm/imagenette数据集作为演示,该数据集包含10个标签,且全部保存为整数值。

使用 CLIP进行分类,需要将整数值标签转换为对应的文本内容。
在直接将标签和照片进行相似度计算前,需要初始化 CLIP模型,可以使用通过 Hugging Face transformers找到的 CLIP 实现。

文本transformer无法直接读取文本,而是需要一组称为token ID(或input _ IDs)的整数值,其中每个唯一的整数表示一个word或sub-word(即token)。

将转换后的tensor输入到文本transformer中可以获取标签的文本embedding

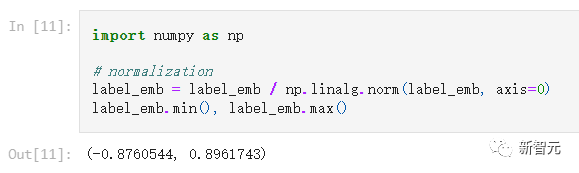
注意,目前CLIP输出的向量还没有经过归一化(normalize),点乘后获取的相似性结果是不准确的。
下面就可以选择一个数据集中的图像作测试,经过相同的处理过程后获取到图像向量。

将图像转换为尺寸为(1, 3, 224, 224)向量后,输入到模型中即可获得embedding

下一步就是计算图像embedding和数据集中的十个标签文本embedding之间的点积相似度,得分最高的即是预测的类别。

模型给出的结果为cassette player(盒式磁带播放器),在整个数据集再重复运行一遍后,可以得到准确率为98.7%

除了Zero-shot分类,多模态搜索、目标检测、 生成式模型如OpenAI 的 Dall-E 和 Stable disusion,CLIP打开了计算机视觉的新大门。

