
史上最大CLIP模型ViT-G/14开源:ImageNet可达80.1
 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!
LAION这个开源机构相信大家都不陌生,这个非盈利开源机构先后开源了LAION-400M和LAION-5B等大规模图文对数据集,而且也发起了OpenCLIP项目,在22年12月份LAION也发布了基于OpenCLIP的scaling laws报告,其中最大模型ViT-H/14在ImageNet上的zero-shot准确度达到了78.0%。在今年1月底,LAION继续扩增模型,训练了参数量约2.5B的ViT-G/14模型,其在ImageNet上的zero-shot准确度达到了80.1%,这也是目前开源的最大的CLIP模型。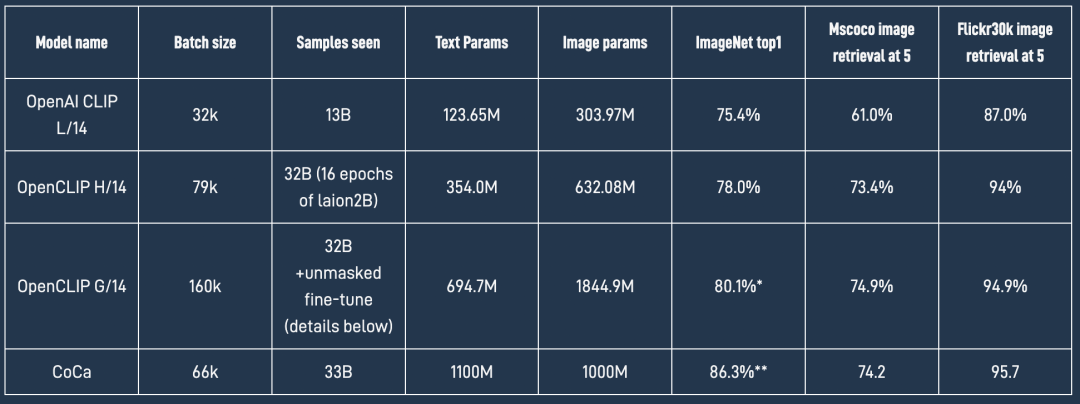 相比之前的OpenCLIP H/14模型,新开源的OpenCLIP G/14模型的text encoder参数从原来的354.0M增加到694.7M,而image encoder参数从632.08M增加至1844.9M,增加接近3倍。OpenCLIP G/14模型的加入也可以进一步验证scaling law:
相比之前的OpenCLIP H/14模型,新开源的OpenCLIP G/14模型的text encoder参数从原来的354.0M增加到694.7M,而image encoder参数从632.08M增加至1844.9M,增加接近3倍。OpenCLIP G/14模型的加入也可以进一步验证scaling law: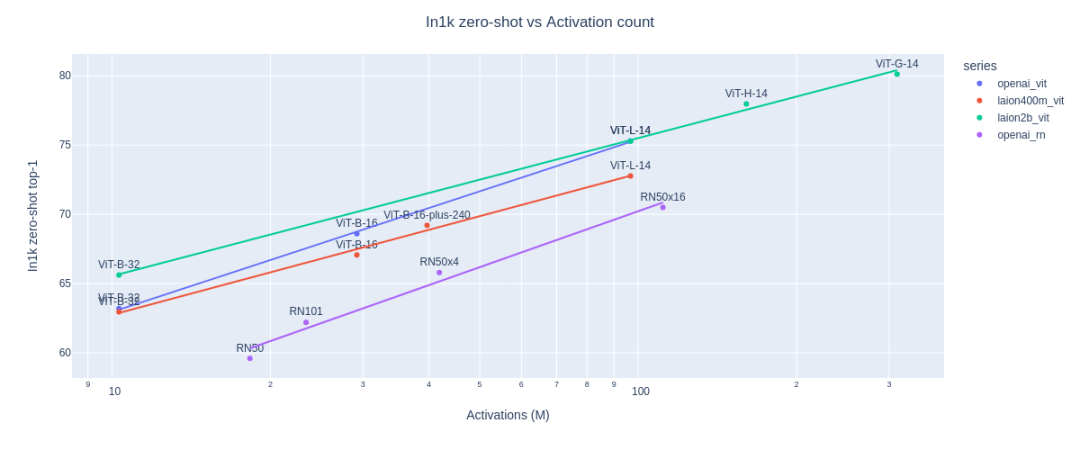 OpenCLIP G/14模型采用了meta所提出的FLIP中的策略来进行训练,FLIP的主要思路是mask一部分patch来训练image encoder,这带来的好处是减少显存从而增大batch size。基于FLIP中的patch dropout/mask策略,OpenCLIP G/14模型的batch size达到了160K(512~760 A100上),batch size对CLIP的训练效果是至关重要的。具体来说,OpenCLIP G/14模型的训练共分为两个阶段(遵循FLIP):
OpenCLIP G/14模型采用了meta所提出的FLIP中的策略来进行训练,FLIP的主要思路是mask一部分patch来训练image encoder,这带来的好处是减少显存从而增大batch size。基于FLIP中的patch dropout/mask策略,OpenCLIP G/14模型的batch size达到了160K(512~760 A100上),batch size对CLIP的训练效果是至关重要的。具体来说,OpenCLIP G/14模型的训练共分为两个阶段(遵循FLIP):
第一阶段:Patch dropout
采用50%的patch dropout在LAION-2B数据集上训练,共采样32B的样本量(训练所过的全部样本数量)。这里采用的batch size是160K,优化器为AdamW,学习速率为2e-3,采用cosine decay schedule。这个阶段后,模型可以在ImageNet上达到79.07。
第二阶段:Unmasked tuning + Model soups
patch mask或dropout策略会导致image encoder在训练和测试时的不一致,所以需要少量的unmasked tuning,此时就和常规的CLIP一样不进行mask,注意这个阶段需要采用gradient checkpointing来保证160K的batch size。这个阶段共采用3种的不同的设置(学习速率,训练样本等设置不同)来训练3个不同的模型,其分别可以在ImageNet上达到79.43、79.45和79.2。最后再基于谷歌论文Model soups中提取的权重平均来得到最后的模型,其在ImageNet上达到80.1。
下图为OpenCLIP G/14模型和OpenCLIP H/14模型在各个图像分类数据集上的zero-shot性能对比,可以看到OpenCLIP G/14模型在绝大多数数据集上均明显优于OpenCLIP H/14模型。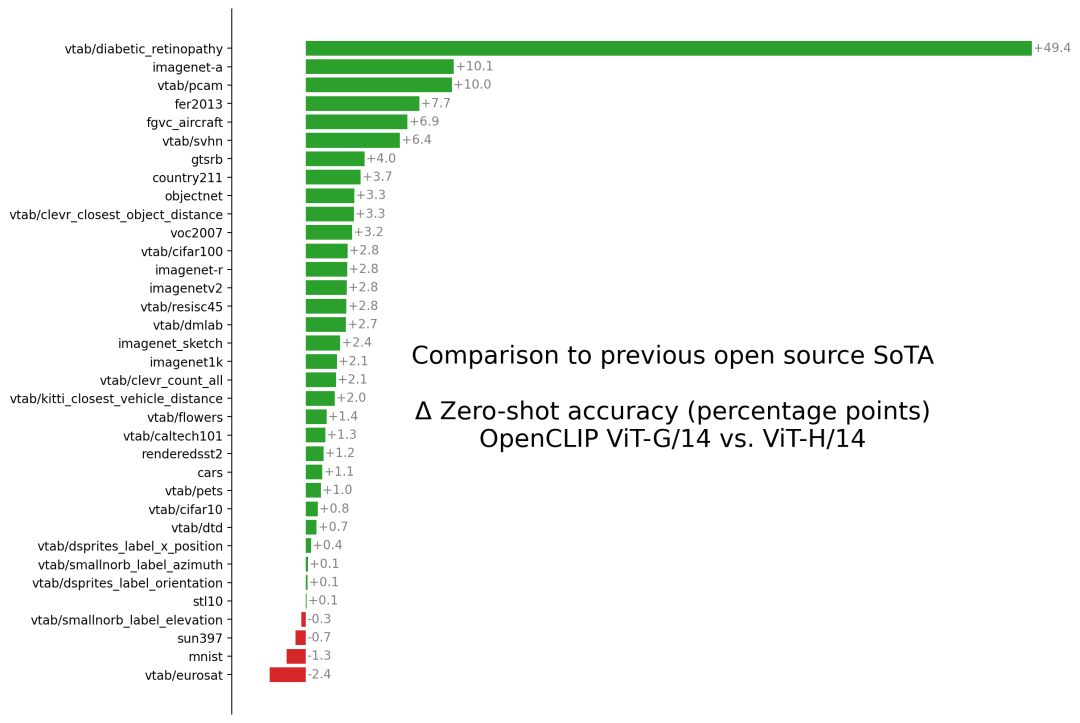
CLIP模型的应用甚广,除了常规图像和文本多模态检索任务,CLIP还可以应用在文生图大模型上,比如DALLE2和Stable Diffusion均采用CLIP模型所提取的特征作为扩散模型的输入条件。近期所发布的Stable Diffusion 2.0相比1.5版本,一个最重要的改进就是将text encoder从原来的ViT-L/14换成了更大的ViT-H/14(参数量增大3倍),SD 2.0相比1.5版本在FID和CLIP score上均有一定提升。毫无疑问,更大的模型ViT-G/14会带来进一步的提升。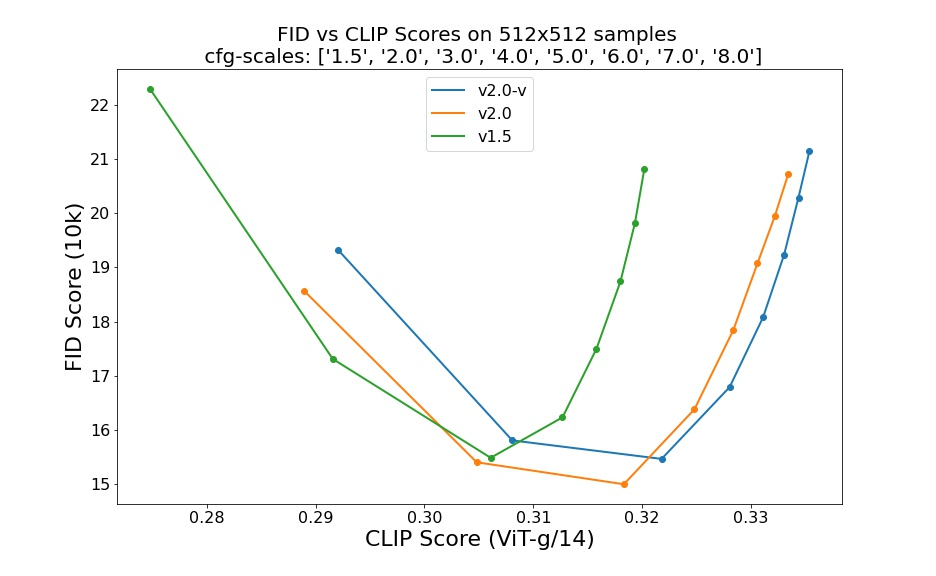
目前OpenCLIP G/14模型已经在hugging face上开源:https://huggingface.co/laion/CLIP-ViT-bigG-14-laion2B-39B-b160k。你可以直接基于openclip库来使用它:
import open_clip
import torch
from PIL import Image
model, preprocess_train, preprocess_val = open_clip.create_model_and_transforms('hf-hub:laion/CLIP-ViT-bigG-14-laion2B-39B-b160k')
tokenizer = open_clip.get_tokenizer('hf-hub:laion/CLIP-ViT-bigG-14-laion2B-39B-b160k')
image = preprocess_val(Image.open("CLIP.png")).unsqueeze(0)
text = tokenizer(["a diagram", "a dog", "a cat"])
with torch.no_grad(), torch.cuda.amp.autocast():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
text_probs = (100.0 * image_features @ text_features.T).softmax(dim=-1)
print("Label probs:", text_probs) # prints: [[1., 0., 0.]]
参考
Reproducible scaling laws for contrastive language-image learning https://github.com/mlfoundations/open_clip
推荐阅读
辅助模块加速收敛,精度大幅提升!移动端实时的NanoDet-Plus来了!
机器学习算法工程师
一个用心的公众号
