
谷歌卷积+注意力新模型:CoAtNet,准确率高达89.77%,一举超过ResNet最强变体!

极市导读
虽然Transformer在CV任务上有非常强的学习建模能力,但是由于缺少了像CNN那样的归纳偏置,所以相比于CNN,Transformer的泛化能力就比较差。因此,本文的作者提出了CoAtNet(Convlutio+Attention)将卷积层和注意层相结合起来,使得模型具有更强的学习能力和泛化能力。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
【写在前面】
近段时间,Transformer在计算机视觉领域取得了非常好的成绩,在有额外数据(e.g., JFT)用于预训练的情况下,视觉Transformer的结构更是能够超过了CNN的SOTA性能。但是在只使用ImageNet的情况下,ViT结构的性能距离CNN还是有一定的差距的。这可能是由于Transformer没有像CNN那样强的归纳偏置(inductive bias),因此,本文的作者提出了CoAtNet(Co nvlutio+At tention)将卷积层和注意层相结合起来,使得模型具有更强的学习能力和泛化能力。
Noting:其实这篇论文跟VOLO的出发点上还是有一点相似的,他们都是引入了CNN那种对局部信息的感知,通过这种inductive bias,使得模型在CV任务上具有更好的性能。
1. 论文和代码地址
CoAtNet: Marrying Convolution and Attention for All Data Sizes
论文地址:https://arxiv.org/abs/2106.04803
官网代码:未开源
核心代码:后面会找个时间复现一下论文,然后更新在:https://github.com/xmu-xiaoma666/External-Attention-pytorch上
2. Motivation
虽然Transformer在CV任务上有非常强的学习建模能力,但是由于缺少了像CNN那样的归纳偏置,所以相比于CNN,Transformer的泛化能力就比较差。因此,如果只有Transformer进行全局信息的建模,在没有预训练(JFT-300M)的情况下,Transformer在性能上很难超过CNN(VOLO在没有预训练的情况下,一定程度上也是因为VOLO的Outlook Attention对特征信息进行了局部感知,相当于引入了归纳偏置)。既然CNN有更强的泛化能力,Transformer具有更强的学习能力,作者就想到,为什么不能将Transformer和CNN进行一个结合呢?因此,这篇论文探究了,具体怎么将CNN与Transformer做结合,才能使得模型具有更强的学习能力和泛化能力。
3. 方法
3.1. Convolution和Self-Attention的融合
3.1.1. Convolution
在卷积类型的选择上,作者采用的是MBConv(MBConv的结构见下图,关于MBConv的详细介绍可见[1])。简单的来说MBConv就是有两个特点:1)采用了Depthwise Convlution,因此相比于传统卷积,Depthwise Conv的参数能够大大减少;2)采用了“倒瓶颈”的结构,也就是说在卷积过程中,特征经历了升维和降维两个步骤,这样做的目的应该是为了提高模型的学习能力。
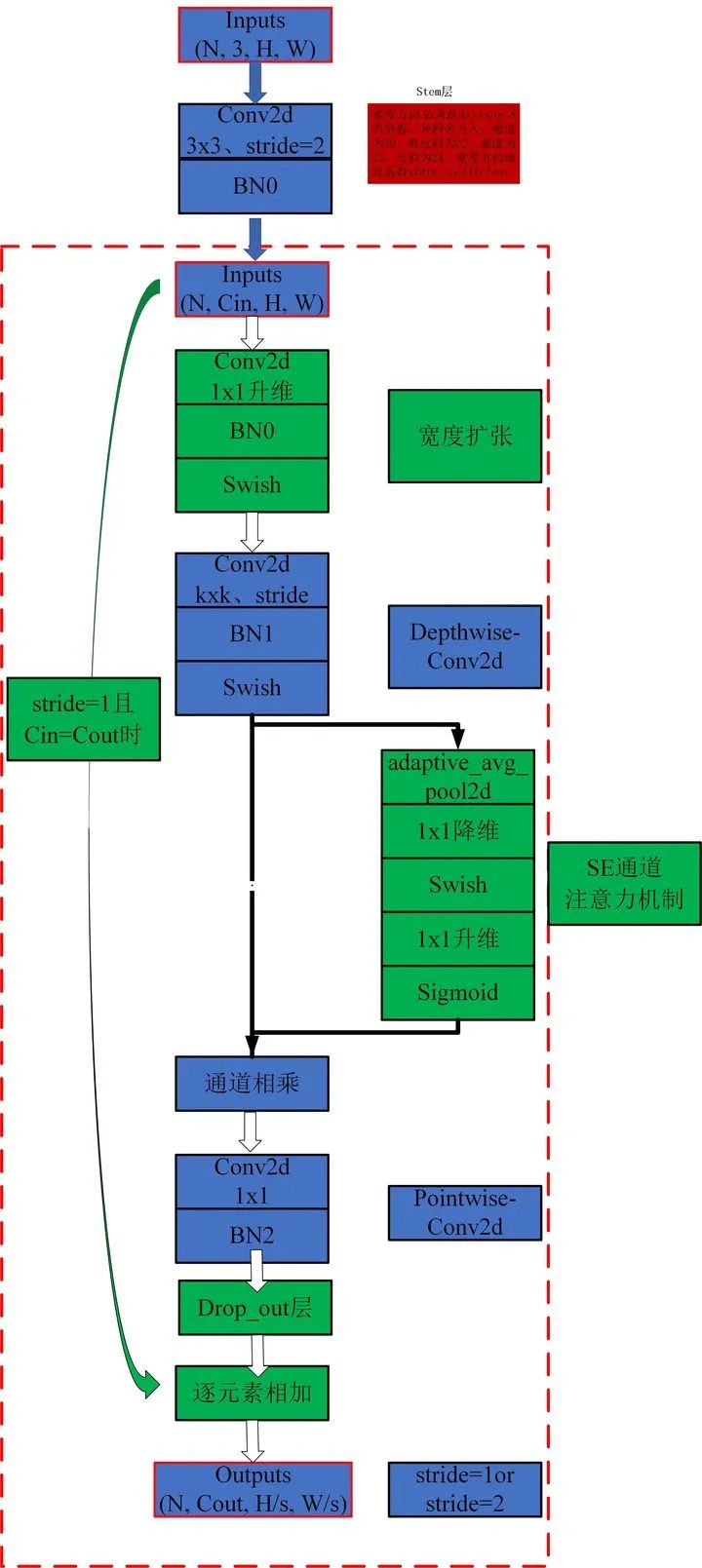
(图来自:https://zhuanlan.zhihu.com/p/258386372)
卷积起到是一个对局部信息建模的功能,可以表示成下面的公式:
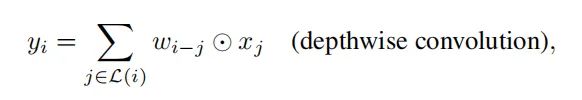
3.1.2. Self-Attention
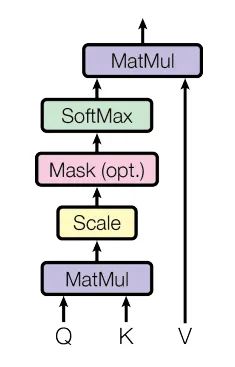
Self-Attention[2]的计算主要分为三步,第一步是将query和每个key进行相似度计算得到权重,常用的相似度函数有点积,拼接,感知机等;第二步是使用一个softmax函数对这些权重进行归一化;最后将权重和相应的键值value进行加权求和得到最后的结果。
Self-Attention是进行全局信息的建模,因为Self-Attention在每一个位置进行特征映射是平等了考虑了所有位置的特征,可以表示成下面的公式:
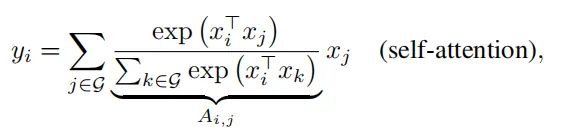
3.1.3. Conv和Self-Attention的性质分析
1)Conv的卷积核是静态的,是与输入的特征无关的;Self-Attention的权重是根据QKV动态计算得到的,所以Self-Attention的动态自适应加权的。
2)对卷积来说,它只关心每个位置周围的特征,因此卷积具有平移不变性(translation equivalence),这也是卷积具有良好泛化能力的原因。但是ViT使用的是绝对位置编码,因此Self-Attention不具备这个性质。
3)Conv的感知范围受卷积核大小的限制,而大范围的感知能力有利于模型获得更多的上下文信息。因此全局感知也是Self-Attention用在CV任务中的一个重要motivation。

3.1.4. 融合
上面分析了Conv和Self-Attention几个性质,为了将Conv和Self-Attention的优点结合,可以将静态的全局全局和和自适应注意力矩阵相加,因此就可以表示呈下面的公式:
先求和,再Softmax:
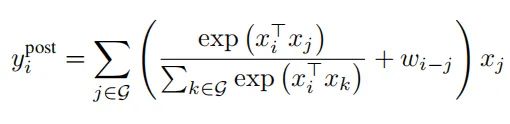
先Softmax,再求和:
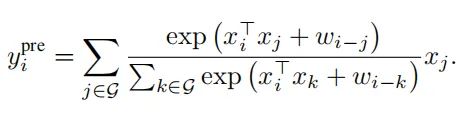
3.2. 垂直结构设计
由于Self-Attention是和输入数据的size呈平方关系,所以如果直接将raw image进行计算,会导致计算非常慢。因此作者提出了三种方案
3.2.1. 被Pass的方案
1)将与输入数据的size呈平方关系的Self-Attention换成线性的Attention
pass原因:Performance不好
2)加强局部注意力,将全局感知限制为局部感知
pass原因:在TPU上计算非常慢;限制了模型的学习能力。
3.2.2. 被接受的方案
进行一些向下采样,并在特征图达到合适的大小后采用全局相对关注。
对于这个方案,也有两种实现方式:
1)像ViT那样,直接用16x16的步长,一次缩小为16倍;
2)采用multi-stage的方式,一次一次Pooling。
3.2.3. Multi-Stage的变种方案
因为前面我们分析了Self-Attention和Convolution各有各的优点,因此在每个Stage中采用什么结构成为了本文研究的重点,对此,作者提出了四种方案:1)
C-C-C-C;2)C-C-C-T;3)C-C-T-T ;4)C-T-T-T。其中C代表Convolution,T代表Transformer。
为了比较这几种方案哪个比较好,作者提出两个衡量点:1)泛化能力(genralization),2)学习能力(model capacity)。
泛化能力:当训练损失相同时,测试集的准确率越高,泛化能力越强。泛化能力用来衡量模型对于没见过数据的判断准确度。
学习能力:当学习数据是庞大、冗余的,学习能力强的模型能够获得更好的性能。学习能力用来衡量拟合大数据集的能力。
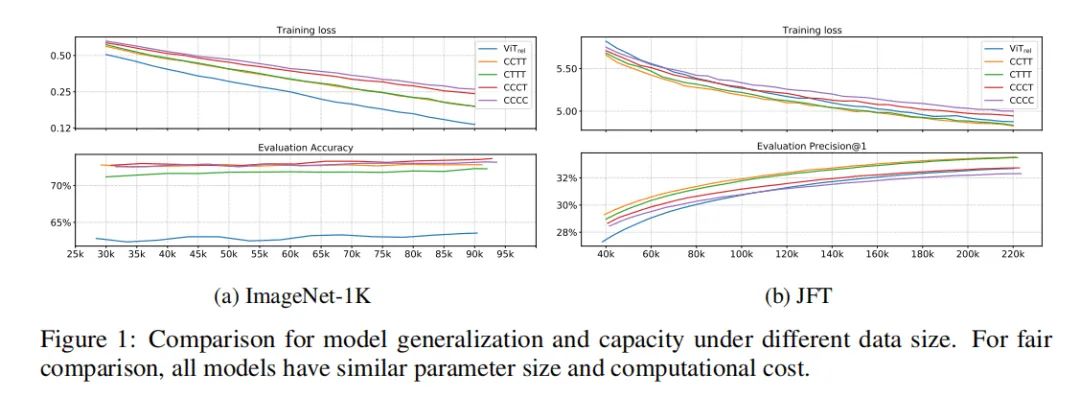
上面这张图展示了在ImageNet-1K(小数据集),JFT(大数据集)上的训练损失和验证准确率。根据对genralization和model capacity的定义,我们可以得出这样的结论:
在genralization capability 上,各个变种genralization capability 的排序如下:
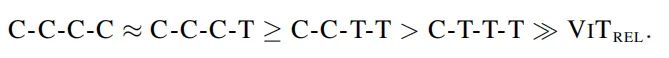
对于model capacity,各个变种model capacity 的排序如下:
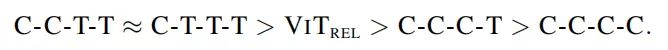
基于以上结果,为了探究C-C-T-T 和 C-T-T-T,哪一个比较好,作者又做了一个transferability test。在JFT上预训练后,在ImageNet-1K上再训练了30个epoch。结果如下:
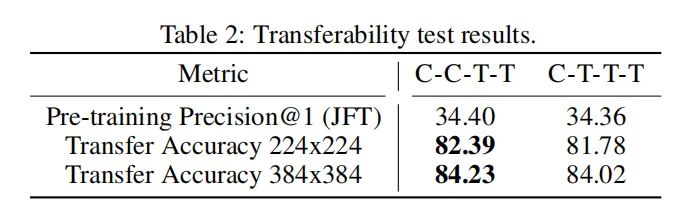
可以看出C-C-T-T的效果比较好,因此作者选用了C-C-T-T作为CoAtNet的结构。
4. 实验
4.1. 不同CoAtNet的变种
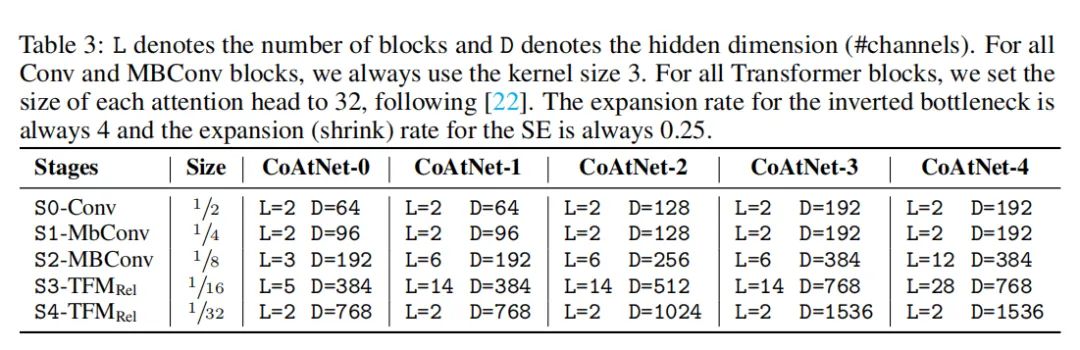
分为几个stage,每个stage的大小都变成了原来的1/2,通道维度都变大了。
4.2. ImageNet-1K的结果
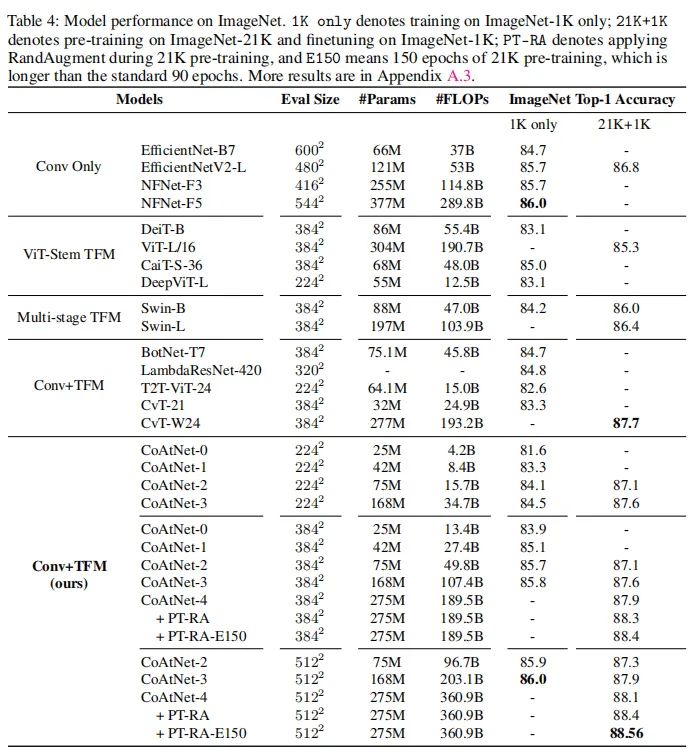
从上面的表格中可以看出CoAt的结果不同比各种ViT的性能更强,并且在不预训练的情况下,CoAtNet-3的性能也跟NFNet-F5一样
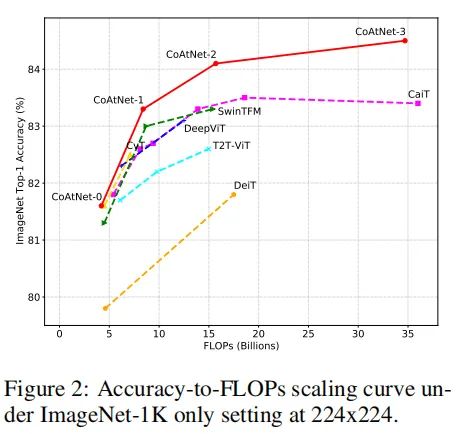
上图可以看出,在不预训练的情况下,CoAtNet能够明显优于其他ViT的变种。
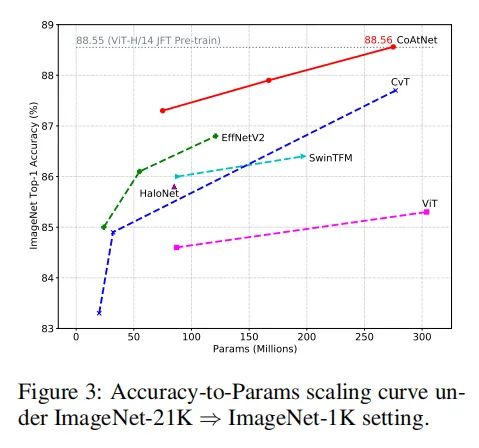
在使用ImageNet-21K的情况下,CoAtNet变体实现了88.56%的top-1精度,相比于其他CNN和ViT结构也有明显的优势。
4.3. JFT的结果
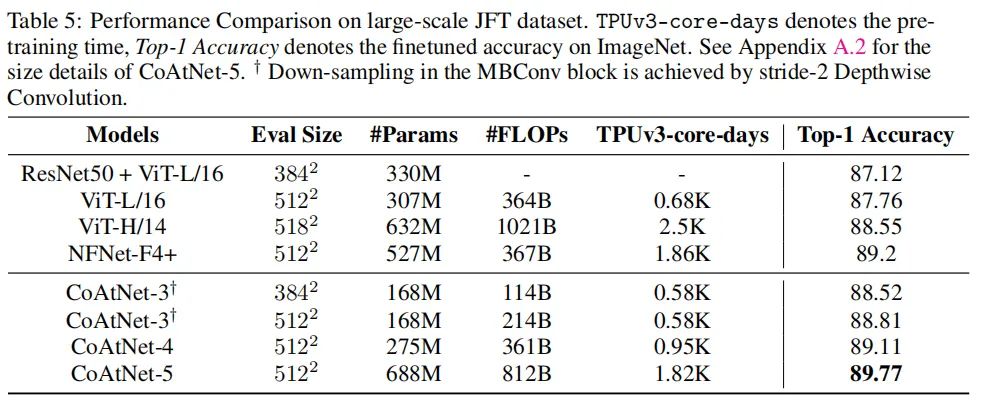
在JFT大数据集上,JFT的性能也是能够明显优于其他模型,展现了CoAtNet强大的泛化能力和模型容量。
5. 总结
目前ViT倾向于引入CNN的假设偏置来提高模型的学习和泛化能力,最近的VOLO这篇文章也是引入了局部感知模块,获得更加细粒度的信息。无论是VOLO还是CoAtNet都将分类任务的性能刷到了一个新的高度。
参考文献
[1]. Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, and Liang-Chieh Chen. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4510–4520, 2018.
[2]. Vaswani, Ashish, et al. "Attention is all you need." arXiv preprint arXiv:1706.03762 (2017).
本文亮点总结
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“84”获取第84期直播PPT~

# 极市原创作者激励计划 #
