来源:Google
编辑:好困 LRS
【新智元导读】通用人工智能(AGI)的目标是训练的模型具有和人类相当的智慧,却惹得无数研究人员竞折腰。最近Jeff Dean发文,称他们正在研究下一代AI框架Pathways,目标直指AGI。这次凭借谷歌的「钞」能力,Jeff Dean能否再掀起一场AI革命?
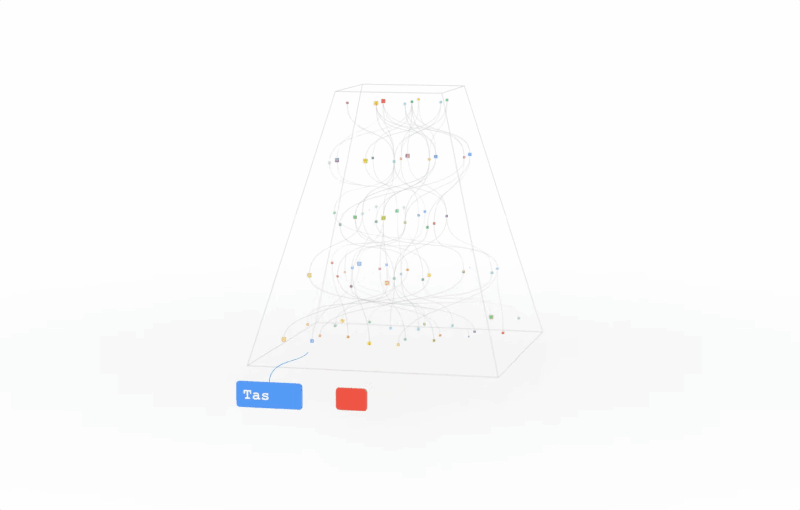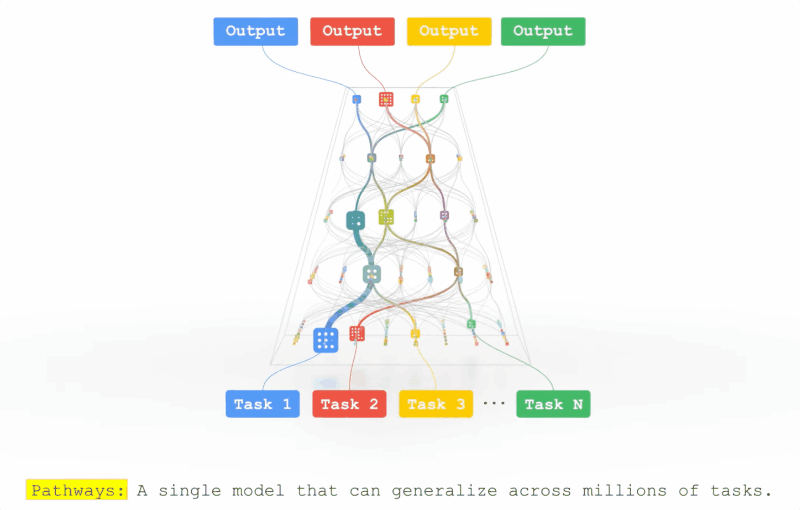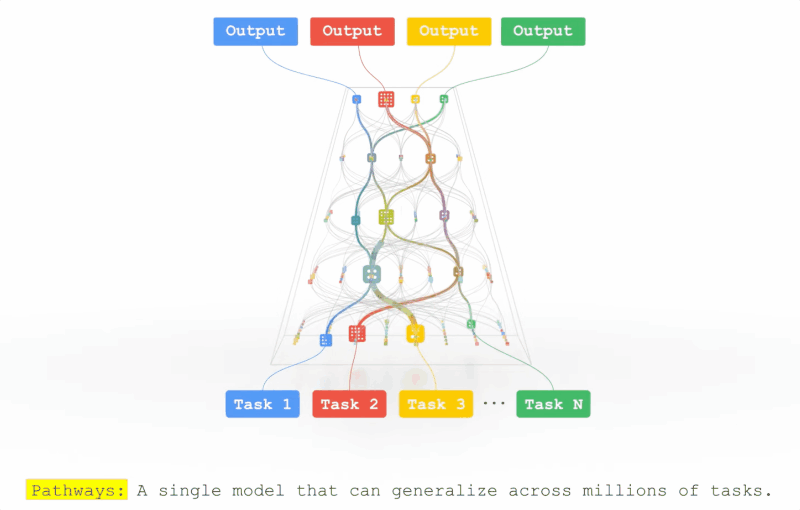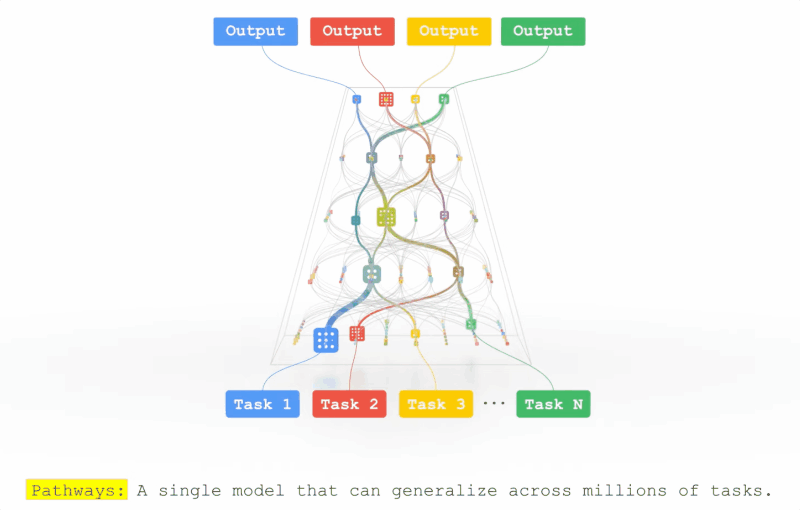
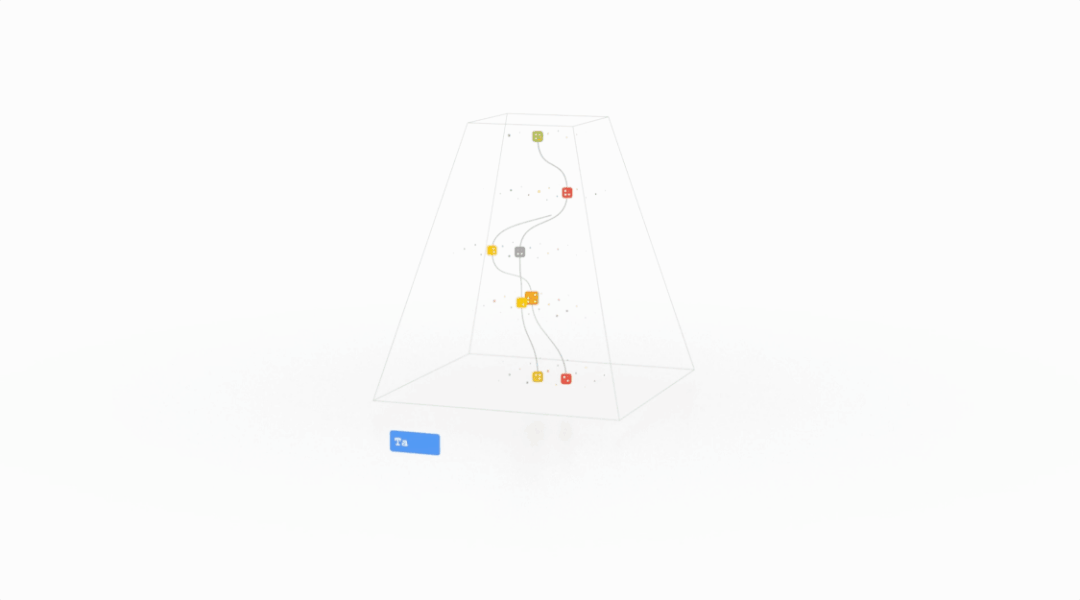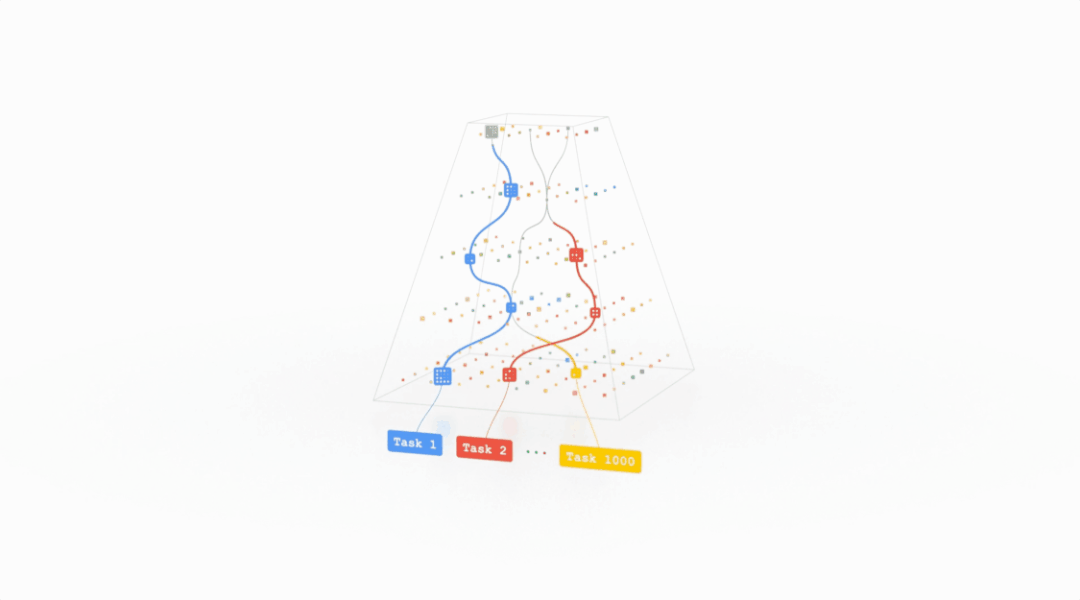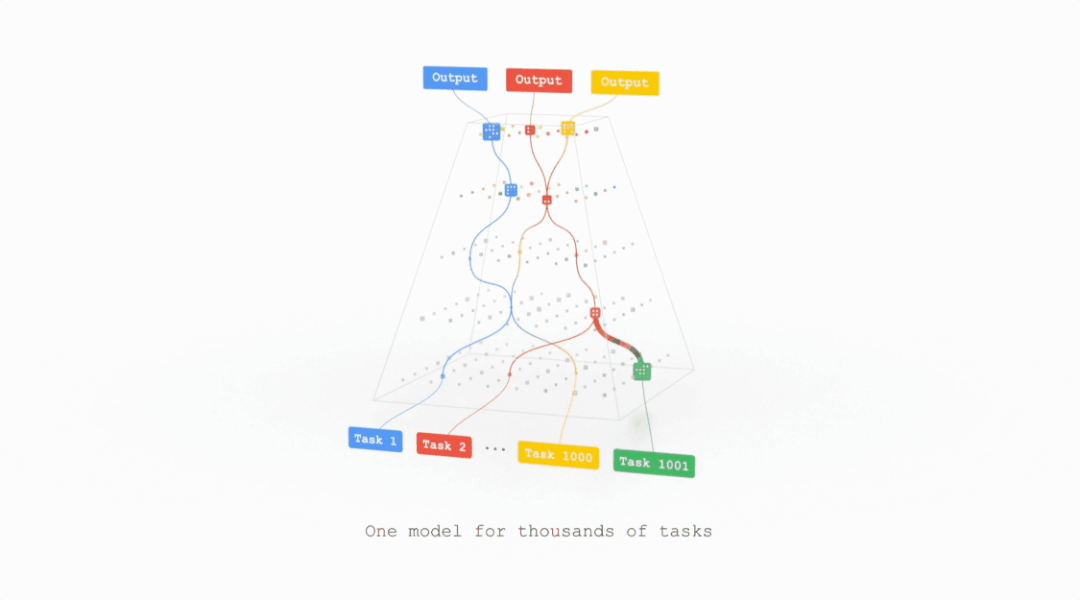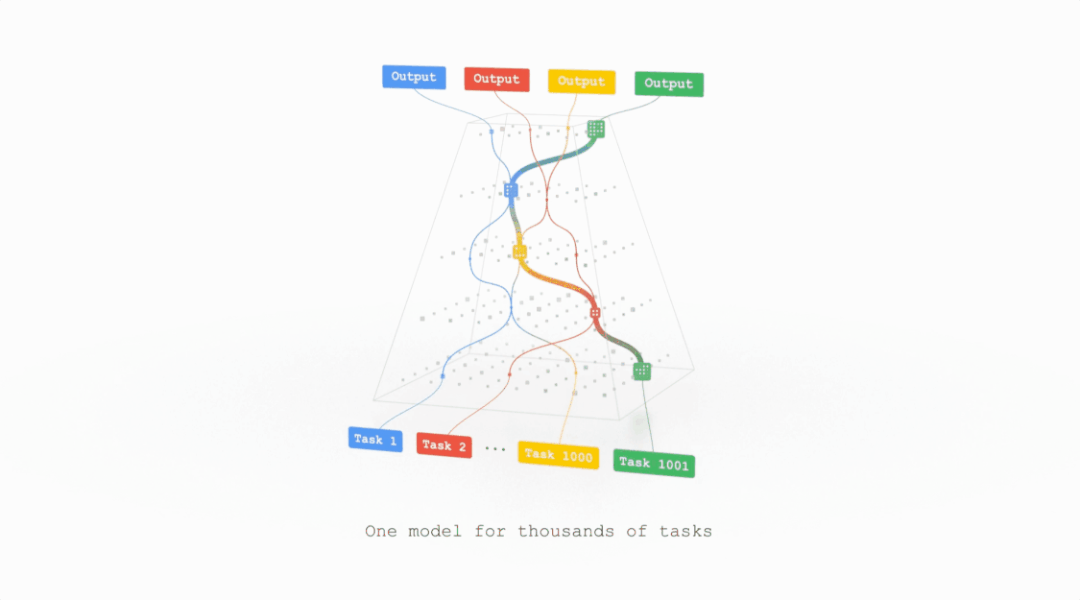
前脚专攻通用人工智能(AGI)的DeepMind想脱离谷歌,后脚谷歌就提出了一种潜在的AGI架构。前段时间Jeff Dean在TED表示他们正在开发一种超级智能的AI模型,目前只剩下道德相关的问题没有解决。近日,Jeff Dean则亲自撰文,介绍了这个全新的机器学习架构——Pathways。回顾过去20年计算机科学的研究中,或许没有哪个领域比AI 研究取得的进展更快。在机器学习技术还没有那么惊艳的的2001, 谷歌的20号员工Jeff Dean就已经开始训练模型对谷歌搜索的错误查询进行纠正。在后续的20年中,谷歌始终秉承AI first,为业界贡献了无数经典模型,word2vec,Transformer,BERT都极大促进了AI的发展。Jeff Dean也成为了美国工程院院士,创建了Google Brain、开发谷歌机器学习开源框架TensorFlow,还是谷歌广告系统、谷歌搜索系统等技术的重要创始人之一,可以说是谷歌的技术奠基人。但机器学习模型始终还处在一个固定的开发模式中,对于每个任务开发一个特定的模型,创建benchmark 来互相比拼,最后活下来的模型成为新sota。这种研究方式虽然可以促进模型的研究,提升特定任务的性能,但离通用人工智能似乎已经越来越远了。当一个任务需要变换输入数据时,现有的模型通常需要重新收集、标注数据,重新研究模型的架构,对于复杂环境的应变能力可以说是十分拉胯了。Jeff Dean将这个新的模型架构Pathways,称为「下一代AI 架构」——只训练一个模型,就可以处理数以万计的任务类型。简单来说就是,Pathways能够让AI模型像人类一样思考。Pathways:训练一个模型可以做千上万个任务。通常来说,每当处理一个新的问题时都需要训练一个新的AI模型,而这些数学模型的参数实际上是用随机的权重进行初始化,然后使用标注数据进行训练的。这就好像说,你在学习跳绳时,又要忘记曾经所学过的一切技能,包括如何平衡、如何跳跃、如何协调双手的运动,直接从「爬」开始学习跳绳。这或多或少就是如今训练大多数机器学习模型的方式:从无到有地训练每一个新的模型来做一件事,而且只做一件事(或者把一个通用模型用于一个特定的任务),而不是扩展现有的模型来学习新的任务。直接导致的结果就是,数以千计的任务带来了成千上万的模型。这不仅让学习每个新任务的时间更长,而且还需要更多的数据来学习每个新任务,因为每次学习都需要从零开始学习关于世界的一切以及该任务的具体细节。Google则希望训练一个模型,不仅可以处理许多独立的任务,而且可以借鉴和结合其现有的技能,从而更快、更有效地学习新任务。举个例子,当一个模型学会了如何从航拍图像中预测地形和建筑的高度之后,它在学习一个新的任务,比如预测洪水带来的影响时,之前学到的那个知识在这时就会作为一个常识来辅助新的训练。此外,模型也会有不同的能力,可以根据需要调用,并且还可以将多个模型拼接起来,进而执行新的、更复杂的任务。人类依靠多种感官来感知世界,这与当代AI模型系统处理信息的方式非常不同,现在的大多数模型一次只处理一种模式的信息。模型的输入可以是文本、图像或语音,但通常无法同时处理所有的三种数据。Pathways 也是一个多模态模型,能够包含视觉、听觉和语言理解。无论模型是在处理「豹子」这个词,还是豹子的「声音」,或是看到豹子奔跑的「视频」,内部都会激活相同的反应,从而理解豹子的「概念」。训练产生的结果是一个更有洞察力、更不容易出错和产生偏见的模型。当然,AI模型不需要局限于这些熟悉的感觉;Pathways可以处理更多抽象形式的数据,帮助找到人类科学家在复杂系统(如气候动力学)中难以发现的有用模式。今天的大多数模型都是「密集型」的,这也就意味着,在完成一个不管是简单还是复杂的任务时,整个神经网络都会被激活。而人类就不一样了,即便大脑中有近千亿个神经元,并且拥有许多不同的区域用于处理各种的任务,但我们只会在特定情况下调用其中一小部分来使用。经过Pathways训练的AI也可以模拟人类大脑的行为,通过建立一个「稀疏」激活的单一模型,只有在特定任务需求的时候才会激活特定部分的神经元。模型能够动态地学习网络的哪些部分擅长哪些任务,可以学习到如何找到模型的最相关部分来处理任务。这种架构的另一大好处是,它不仅有更强大的能力来学习各种任务,因为不需要为每项任务激活整个网络,所以运行速度更快,并且更省电。之前Google 也发表过类似的研究,GShard和Switch Transformer是两个参数量巨大的机器学习模型,但由于两个模型都使用了稀疏激活,在实际运行时消耗的能量不到类似规模的密集型模型的1/10,并且准确率还与密集型模型相当。现阶段的机器学习模型,本可以出色地完成很多不同的任务,却只能选取其中一个过专业化;本可以综合各种不同类型的输入,却只能依赖其中的一种形式;本可以像专家一样熟练操作,却只能付诸于暴力计算。这就是Pathways诞生的原因——让一个AI能够跨越数以万计的的任务,理解不同类型的数据,并同时以极高的效率实现。不知道各位看完Jeff Dean的文章之后是怎样的一种感受,反正这位网友表示:「太肤浅了,以至于毫无用处」。「虽然有很多远大的目标,却完全没有提到他们将如何去实现。」「看起来非常令人兴奋。稀疏可扩展的深度学习可以向一个模型中依次添加任务。我也非常期待之后谷歌的开源代码和样本。」但不要忘了,这想搞事的是谷歌,「钞」能力了解一下?
参考资料:
https://blog.google/technology/ai/introducing-pathways-next-generation-ai-architecture/
https://www.ted.com/talks/jeff_dean_ai_isn_t_as_smart_as_you_think_but_it_could_be/footnotes?utm_content=2021-10-28&utm_source=t.co&utm_medium=social&utm_campaign=social#t-13177