
谷歌大神Jeff Dean领衔,万字展望5大AI趋势

大数据文摘转载自学术头条
对于关心人工智能技术进展的读者来说,每年年底来自整个谷歌 research 团队撰写的年终总结,可谓是必读读物。
今天,由谷歌大神 Jeff Dean 领衔,这份总结虽迟但到。出于知识传播目的,“学术头条”现将全文翻译如下,以飨读者:
在过去的几十年里,我见证了机器学习(ML, Machine Learning)和计算机科学(CS, Computer Science)领域的变化和发展。
早期的方法往往存在某些缺陷导致了失败,然而,通过在这些方法上的不断研究和改进,最终产生了一系列的现代方法,目前这些方法已经非常成功。按照这种长期的发展模式,在未来几年内,我认为我们将会看到一些令人欣喜的进展,这些进展最终将造福数十亿人的生活,产生比以往任何时候都更大的影响。
这篇文章中,我将重点介绍 ML 中可能产生重大影响的五个领域。对于其中的每一项,我都会讨论相关的研究(主要是从 2021 年开始),以及我们在未来几年可能会看到的方向和进展。
趋势1:更强大的通用 ML 模型 趋势2:ML 的持续效率提高 趋势3:ML 对个人和社会都越来越有益 趋势4:ML 在科学、健康和可持续发展方面日益增长的效益 趋势5:更深入和广泛地理解 ML
例如,仅在过去的几年中,模型已经在语言领域取得突破性进展,从数百亿的数据 tokens 中训练数十亿个参数(如,11B 参数 T5 模型),发展到数千亿或上万亿的数据 tokens 中训练高达数千亿或上万亿的参数(如,密集模型,像 OpenAI 的 175 B 参数 GPT3 模型、DeepMind 的 280B 参数 Gopher 模型;稀疏模型,如谷歌的 600 B 参数 GShard 模型、1.2T 参数 GLaM 模型)。数据集和模型大小的增加导致了各种语言任务的准确性的显著提高,这可以从标准自然语言处理(NLP, Natural Language Processing)基准测试任务的全面改进中观察到,正如对语言模型和机器翻译模型的神经网络缩放法则(neural scaling laws)的研究预测的那样。
这些先进的模型中,有许多专注于单一但重要的书面语言模式上,并且在语言理解基准和开放式会话能力方面显示出了最先进的成果,即是跨越一个领域的多个任务也是如此。除此之外,他们还表现出了令人兴奋的能力,即仅用相对较少的训练数据便可以泛化新的语言任务。因为在某些情况下,对于一个新的任务,几乎不存在训练示例。简单举例,如改进的长式问答(long-form question answering),NLP 中的零标签学习,以及我们的 LaMDA 模型,该模型展示出了一种复杂的能力,可以进行开放式对话,并在多个对话回合中保持重要的上下文。


生成模型的输出也在大幅提高。在过去几年里取得了显著的进步,尤其在图像的生成模型中最为明显。例如,最近的模型已经证明了仅给定一个类别(如“irish setter”或“steetcar”)便可以创建逼真的图像,可以“填充”一个低分辨率的图像,以创建一个看起来十分自然的高分辨率匹配图像,甚至可以构建任意长度的自然场景。另一个例子是,可以将图像转换成一系列离散 tokens,然后使用自回归生成模型以高保真度进行合成。


除了先进的单模态模型(single-modality models)外,大规模的多模态模型(multimodal models)也在陆续进入人们的视野。这些模型是迄今为止最前沿的模型,因为它们可以接受多种不同的输入模式(例如,语言、图像、语音、视频),而且在某些情况下,还可以产生不同的输出模式,例如,从描述性的句子或段落生成图像,或用人类语言简要描述图像的视觉内容。这是一个令人惊喜的研究方向,因为类似于现实世界,在多模态数据中更容易学习(例如,阅读一些文章并看时辅以演示比仅仅阅读有用得多)。因此,将图像和文本配对可以帮助完成多种语言的检索任务,并且更好地理解如何对文本和图像输入进行配对,可以对图像字幕任务(image captioning tasks)带来更好的改进效果。同样,在视觉和文本数据上的联合训练,也有助于提高视觉分类任务的准确性和鲁棒性,而在图像、视频和音频任务上的联合训练则可以提高所有模式的泛化性能。还有一些诱人的迹象表明,自然语言可以作为图像处理的输入,告诉机器人如何与这个世界互动,以及控制其他软件系统,这预示着用户界面的开发方式可能会发生变化。这些模型处理的模式将包括语音、声音、图像、视频和语言,甚至可能扩展到结构化数据、知识图和时间序列数据等等。

所有这些趋势都指向训练能够处理多种数据模式并解决数千或数百万任务的高能力通用模型的方向。通过构建稀疏性模型,使得模型中唯一被给定任务激活的部分是那些针对其优化过的部分,由此一来,这些多模态模型可以变得更加高效。在未来的几年里,我们将在名为“Pathways”的下一代架构和综合努力中追求这一愿景。随着我们把迄今为止的许多想法结合在一起,我们期望在这一领域看到实质性的进展。
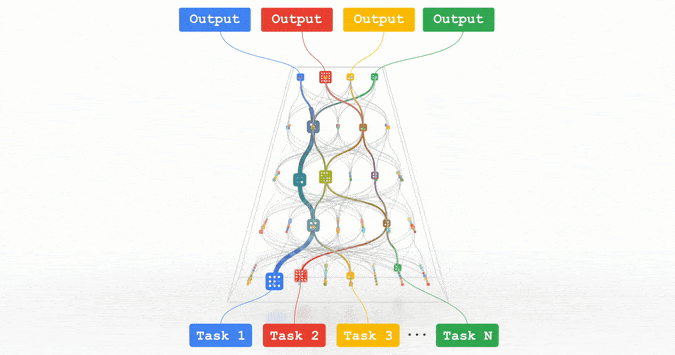
由于计算机硬件设计、ML 算法和元学习(meta-learning)研究的进步,效率的提高正在推动 ML 模型向更强的能力发展。ML 管道的许多方面,从训练和执行模型的硬件到 ML 体系结构的各个组件,都可以在保持或提高整体性能的同时进行效率优化。这些不同的线程中的每一个都可以通过显着的乘法因子来提高效率,并且与几年前相比,可以将计算成本降低几个数量级。这种更高的效率使许多关键的进展得以实现,这些进展将继续显著地提高 ML 的效率,使更大、更高质量的 ML 模型能够以更有效的成本开发,并进一步普及访问。我对这些研究方向感到非常兴奋!
ML加速器性能的持续改进:
每一代ML加速器都在前几代的基础上进行了改进,使每个芯片的性能更快,并且通常会增加整个系统的规模。其中,拥有大量芯片的 pods,这些芯片通过高速网络连接在一起,可以提高大型模型的效率。
当然,移动设备上的 ML 能力也在显著增加。Pixel 6 手机配备了全新的谷歌张量处理器(Google Tensor processor),集成了强大的ML加速器,以更好地支持重要的设备上功能。
我们使用 ML 来加速各种计算机芯片的设计(下面将详细介绍),这也带来了好处,特别是在生产更好的 ML 加速器方面。

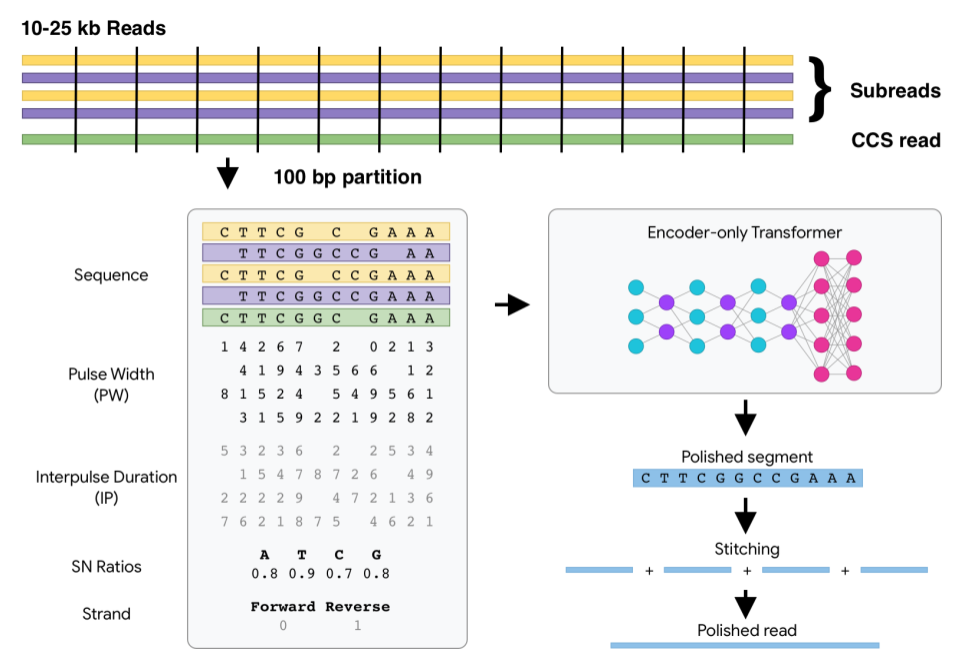
即使在硬件没有变化的情况下,对于 ML 加速器的编译器和系统软件的其他优化也可以显著提高效率。例如,“自动调优多通道机器学习编译器的灵活方法”展示了如何使用 ML 来执行编译设置的自动调优,从而在相同的底层硬件上为一套 ML 程序实现 5-15%(有时高达 2.4 倍的改进)的全面性能改进。GSPMD 描述了一个基于 XLA 编译器的自动并行化系统,该系统能够扩展大多数深度学习网络架构,超出加速器的内存容量,并已应用于许多大型模型,如 GShard-M4、LaMDA、BigSSL、ViT、MetNet-2 和 GLaM 等等,在多个领域上带来了最先进的结果。
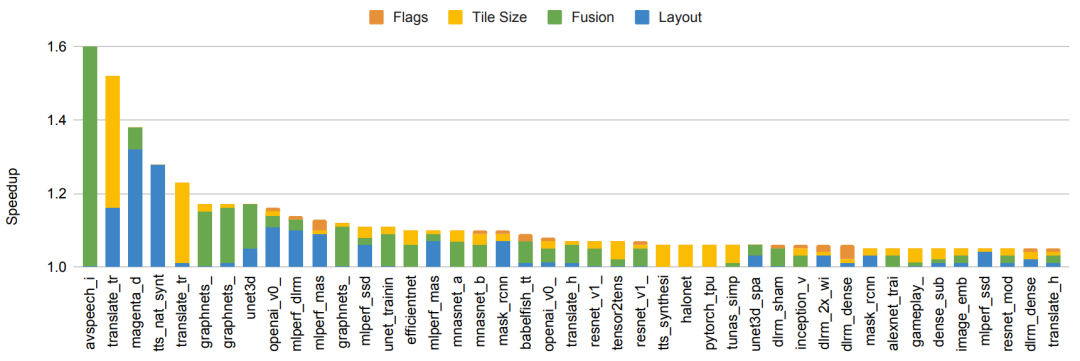
图丨在 150 ML 模型上使用基于 ML 的编译器自动调优,可以加快端到端模型的速度。包括实现 5% 或更多改进比例的模型。条形颜色代表了优化不同模型组件的相对改进程度。
模型体系结构的不断改进,大大减少了许多问题达到给定精度水平所需的计算量。例如,我们在 2017 年开发的 Transformer 结构,能够在几个 NLP 任务和翻译基准上提高技术水平。与此同时,可以使用比各种其他流行方法少 10 倍甚至百倍的计算来实现这些结果,例如作为 LSTMs 和其他循环架构。类似地,视觉 Transformer 能够在许多不同的图像分类任务中显示出改进的最新结果,尽管使用的计算量比卷积神经网络少 4 到 10 倍。
更高效模型架构的机器驱动发现:
神经体系结构搜索(NAS, Neural Architecture Search)可以自动发现对于给定的问题域更有效、新颖的 ML 体系结构。NAS 的主要优势是,它可以大大减少算法开发所需的工作量,因为 NAS 在每个搜索空间和问题域组合中只需要一次性的工作。此外,虽然最初执行 NAS 的工作可能在计算上很昂贵,但由此产生的模型可以大大减少下游研究和生产环境中的计算,从而大大减少整体资源需求。例如,为了发现演化 Transformer(Evolved Transformer)而进行的一次性搜索只产生了 3.2 吨的 CO2e,但是生成了一个供 NLP 社区中的任何人使用的模型,该模型比普通的 Transformer 模型的效率高 15-20%。最近对 NAS 的使用发现了一种更高效的体系结构 Primer(开源),与普通的 Transformer 模型相比,它降低了4倍的训练成本。通过这种方式,NAS 搜索的发现成本通常可以通过使用发现的更高效的模型体系结构得到补偿,即使它们只应用于少数下游任务。


稀疏的使用:
稀疏性是算法的另一个重要的进步,它可以极大地提高效率。稀疏性是指模型具有非常大的容量,但对于给定的任务、示例或 token,仅激活模型的某些部分。2017 年,我们推出了稀疏门控专家混合层(Sparsely-Gated Mixture-of-Experts Layer),在各种翻译基准上展示了更好的性能,同时在计算量上也保持着一定的优势,比先前最先进的密集 LSTM 模型少 10 倍。最近,Switch Transformer 将专家混合风格的架构与 Transformer 模型架构结合在一起,在训练时间和效率方面比密集的 T5-Base Transformer 模型提高了 7 倍。GLaM 模型表明,Transformer 和混合专家风格的层可以组合在一起,可以产生一个新的模型。该模型在 29 个基准线上平均超过 GPT-3 模型的精度,使用的训练能量减少 3 倍,推理计算减少 2 倍。稀疏性的概念也可以用于降低核心 Transformer 架构中注意力机制的成本。
这些提高效率的方法中的每一种都可以结合在一起,这样,与美国平均使用 P100 GPUs 训练的基线 Transformer 模型相比,目前在高效数据中心训练的等效精度语言模型的能源效率提高了 100 倍,产生的 CO2e 排放量减少了 650 倍。这甚至还没有考虑到谷歌的碳中和(carbon neutral),100% 的可再生能源抵消。
人们比以往任何时候都依赖他们的手机摄像头来记录日常生活和创作灵感。机器学习在计算摄影中的巧妙应用提升了手机相机的功能,使它们更易于使用,产生了更高质量的图像。一些先进的技术,如改进的 HDR+,在弱光下的拍摄能力,更好的人像处理功能,及更大的包容性使得手机摄像可以更真实地反映拍摄对象。Google Photos 中基于机器学习的强大工具如 Magic Eraser 等还能进一步优化照片。

考虑到这些功能使用数据的敏感性,把它们默认设置为不共享是很重要的。以上提到的许多功能都在 Android的Private Compute Core 中运行。这是一个开源的、安全的环境,与操作系统的其余部分隔离开。Android 确保未经用户同意,不会将在 Private Compute Core 中的数据共享给任何应用程序。Android 还阻止 Private Compute Core 的任何功能直接访问网络。功能通过一小部分开源 API 与 Private Compute Services 进行通信,这样就能剔除身份敏感信息并使用联邦学习、联邦分析和私人信息检索等功能保护隐私。
这些技术对于发展下一代计算和交互范例至关重要,个人或公共设备需要在不损害隐私的情况下学习并帮助训练(算法)模型。联邦的无人监督学习方法,可以创造出越来越智能的系统。这些系统的交互更加直观,更像是一个社交实体,而不是一台机器。只有对我们的技术进行深刻变革,才有可能广泛而公平地拥有这些智能系统,让它们支持神经计算。
计算机视觉提供新的洞察力:
在过去的十年里,计算机视觉的进步使计算机能够完成不同科学领域的各种任务。在神经科学中,自动重建技术可以从脑组织薄片的高分辨率电子显微镜图像中重现脑组织的神经连接结构。前些年,谷歌为研究果蝇、老鼠的大脑创造了这样的资源,去年,我们与哈佛大学的利希特曼实验室(Lichtman Lab)合作,进行了第一次大规模的人类皮质突触连接研究。该研究跨越了所有皮层的多个细胞类型。这项工作的目标是帮助神经科学家研究令人惊叹的人类大脑。例如,下图显示了成人大脑中约 860 亿个神经元中的 6 个。
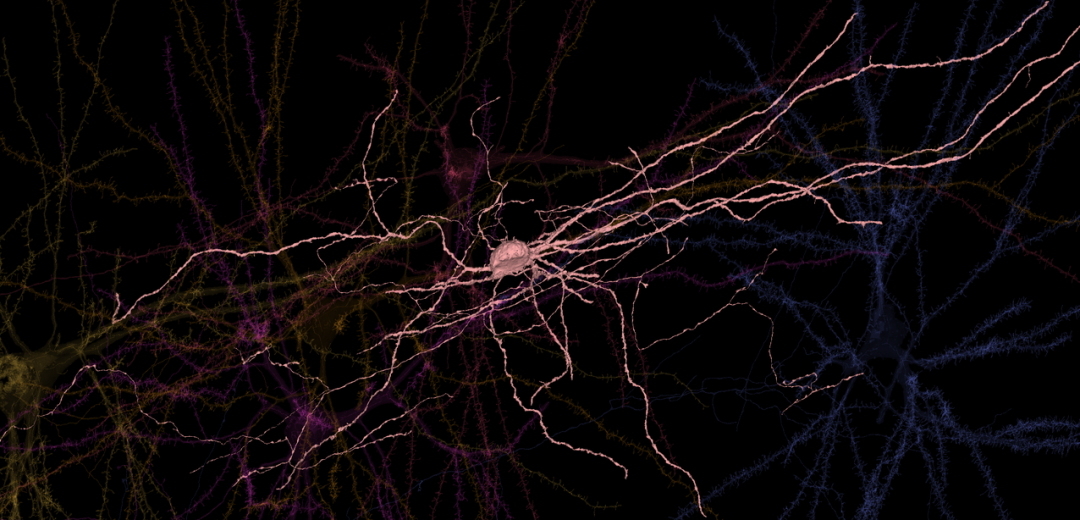


除了推进基础科学,人工智能还可以在更广泛的范围内为医学和人类健康做出贡献。在健康领域利用计算机科学并不是什么新鲜事。但机器学习打开了新的大门,带来了新的机遇和挑战。
以基因组学领域为例。计算机从一开始就对基因组学很重要,但是机器学习增加了新的功能并颠覆了旧的模式。当谷歌的研究人员探索这一领域的工作时,许多专家认为利用深度学习来推断基因变异的想法是牵强的。如今,这种机器方法被认为是最先进的。谷歌发布的开源软件 DeepConsensus 以及与加州大学洛杉矶分校(UCSC)合作的 Pepper-DeepVariant 提供了尖端的信息学支持。我们希望更多的快速测序可以在近期进入实际应用领域,并对患者产生实际影响。
以基因组学领域为例。计算技术一直对基因组学非常重要,但机器学习方法改变了之前的旧模式,并增添了新的功能。最初,谷歌的研究人员使用机器学习在该领域展开研究时,许多专家认为使用深度学习技术从测序仪中推断是否存在基因变异的想法是不可行的。但如今,机器学习是最先进的研究方法。并且未来机器学习将扮演更重要的角色,比如基因组学公司正在开发更精确、更快的新测序仪,它需要匹配更好的推理能力。我们也发布了 DeepConsensus 开源软件,以及与 UCSC 合作的 PEPPER-DeepVariant,为这些新仪器提供最前沿的信息学支持。我们希望这些性能更强的测序仪可以尽快应用在实际患者中并产生有益影响。

谷歌在 2016 年发表了一篇关于深度学习在糖尿病视网膜病变筛查中应用的论文,被《美国医学会杂志》(JAMA)的编辑选为十年来最具影响力的十大论文之一。这意味着它不仅在机器学习和健康方面具有广泛影响力,并且也是十年来最具影响的 JAMA 论文之一。而且我们的研究影响并不仅限于对论文,而是扩展到现实世界中建立系统的能力。通过我们的全球合作伙伴网络,该项目已经帮助印度、泰国、德国和法国的数万名患者进行疾病筛查,否则他们自己可能没有能力接受这种威胁视力疾病的检测。
我们希望看到更多机器学习辅助系统的部署,以应用到改善乳腺癌筛查、检测肺癌、加速癌症放射治疗、标记异常x光和对前列腺癌活检分级上。机器学习为每个领域都提供了新的帮助。比如机器学习辅助的结肠镜检查,就是一个超越了原有基础的例子。结肠镜检查不仅仅只是诊断结肠癌,还可以在手术过程中切除息肉,是阻止疾病发展和预防严重疾病的前沿阵地。在该领域中,我们已经证明机器学习可以帮助确保医生不遗漏息肉,帮助检测难以发现的息肉,还可以增加维度来提高准确度,例如应用同步定位和绘图技术。在与耶路撒冷 Shaare Zedek Medical Center 医疗中心的合作中,实验证明这些系统可以实时工作,平均每次手术可以检测到一个可能会漏检的息肉,而且每次手术的错误警报少于 4 次。

尽管机器学习可能对扩大访问量和提高临床准确性很重要,但我们发现有新的趋势正在出现:使用机器学习帮助人们的日常健康和幸福。我们日常使用的设备都部署有强大的传感器,可以帮助人们普及健康指标和信息,使人们可以对自己的健康做出更明智的决定。目前已经有了可以评估心率和呼吸频率的智能手机摄像头,并且无需额外的硬件设备。Nest Hub 设备可以支持非接触式睡眠感知,让用户更好地了解自己的夜间健康状况。我们可以在自己的 ASR 系统中显著提高无序语音识别的质量,也可以使用机器学习帮助有语音障碍的人重塑声音,使他们能够用自己的声音交流。也许,使用机器学习让智能手机帮助人们更好地研究皮肤病状况,或者帮助视力有限的人慢跑,并不是遥不可及的:这些机遇证明未来是光明的。
机器学习在气候危机中的应用:
气候变化也是一个至关重要的领域,对人类来说具有非常紧迫的威胁。我们需要共同努力来扭转有害排放的趋势,以确保未来的安全和繁荣。而更好地了解不同选择对气候的影响,可以帮助我们用多种方式应对这一挑战。
为此,我们在谷歌地图中推出了环保路线,预计该方法可以每年节省约 100 万吨二氧化碳排放(相当于在道路上减少 20 多万辆汽车)。最近的实验研究表明,在美国盐湖城使用谷歌地图导航可以实现更快、更环保的路线,节省了 1.7% 的二氧化碳排放量和 6.5% 的旅行时间。此外,还可以让地图软件更好地适应电动汽车,帮助缓解里程焦虑,鼓励人们使用无排放的交通工具。我们还与世界各地的城市进行合作,利用汇总的历史交通数据,帮助改善交通灯计时设置。在以色列和巴西进行的一项早期试点研究显示,有检查十字路口的燃油消耗和延误时间减少了 10-20%。

并且,我们还得努力应对越来越常见的火灾和洪水(像数百万加州人一样不得不适应定期的“火灾季节”)。去年,我们发布了一份由卫星数据支持的火灾边界地图,帮助美国人轻松地在自己设备上了解火灾的大致规模和位置。我们还将谷歌上所有的火灾信息进行整合,并在全球范围内进行推出。我们也一直在应用图形优化算法来帮助优化火灾疏散路线,以帮助人们安全逃离快速推进的火灾。2021 年,我们的洪水预报计划的预警系统覆盖范围扩大到 3.6 亿人,是前一年的三倍以上,并向面临洪灾风险人群的移动设备直接发送了 1.15 亿多条通知。我们还首次在现实世界系统中部署了基于 LSTM(长短时记忆网络)的预测模型和 Manifold 模型,并分享了系统中所有组件的详细信息。
基于用户在线产品活动的推荐系统是研究的重点领域。由于这些推荐系统通常由多个不同部分组成,理解它们的公平性往往需要深入了解单个部分以及各个部分组合在一起时的行为。最近的研究工作揭示了提高单个部分和整个推荐系统的公平性的方法,有助于更好地理解这些关系。此外,当从用户的隐藏活动中学习时,推荐系统以一种无偏差的方式进行学习。因为从以前用户所展示的项目中直接学习的方法中会表现出很明显的偏差。并且如果不对这种偏差进行纠正,推荐产品被展示的位置越显眼,它们就越容易被频繁推荐给未来的用户。
与推荐系统一样,上下文环境在机器翻译中也很重要。因为大多数机器翻译系统都是独立地翻译单个句子,并没有额外的上下文环境。在这种情况下,它们往往会加强与性别、年龄或其他领域有关的偏见。为此,我们长期以来一直在研究如何减少翻译系统中的性别偏见。为了帮助翻译界研究,去年我们基于维基百科传记的翻译来研究翻译中的性别偏见,并发布了一个数据集。
部署机器学习模型的另一个常见问题是分布转移:如果训练模型的数据统计分布与输入模型的数据统计分布不一致,那么有时模型的行为是不可预测的。最近的研究中,我们使用 Deep Bootstrap 框架来比较现实世界和“理想世界”(ideal world)的区别,前者的训练数据是有限的,而后者拥有无限的数据。更好地理解模型在这两种情况下(真实与理想)的行为,可以帮助我们开发出更适用于新环境的模型,并减少在固定训练数据集上的偏差。
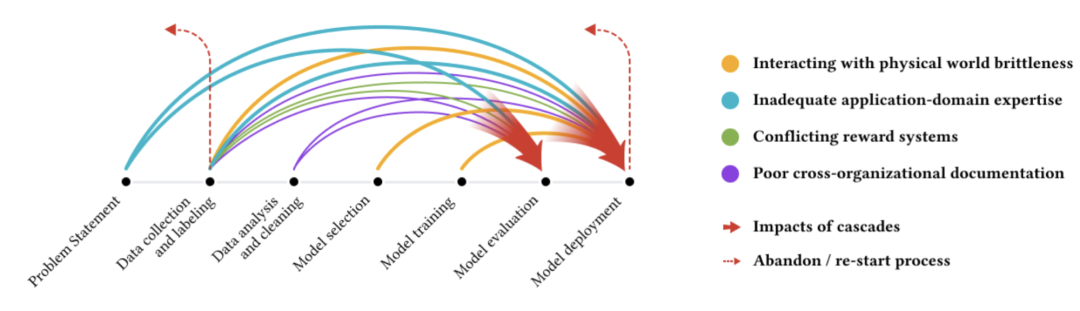
尽管人们对机器学习算法和模型开发的工作有极大的关注,但研究者们对于数据收集和数据集的管理往往关注较少,但这些研究也非常重要,因为机器学习模型所训练的数据可能是下游应用中出现偏见和公平性问题的潜在原因。分析机器学习中的数据级联可以帮助我们识别机器学习项目生命周期中,可能对结果产生重大影响的环节。这项关于数据级联的研究已经在修订后的 PAIR 指南中为数据收集和评估提供了证据支持,该指南主要面向的是机器学习的开发人员和设计人员。
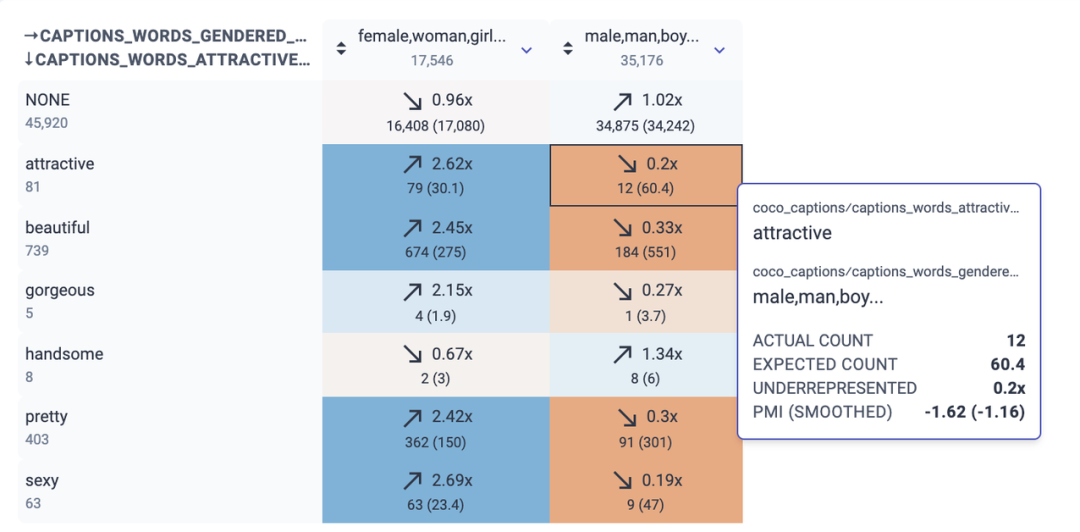
对每个人来说,创建更具包容性和更少偏见的公共数据集是帮助改善机器学习领域的一个重要方法。2016 年,我们发布了开放图像(Open Images)数据集,它包含了约 900 万张图片,这些图片用图像标签标注,涵盖了数千个对象类别和 600 类的边界框标注。
去年,我们在开放图像扩展(Open Images Extended)集合中引入了包容性人物标注(MIAP)数据集。该集合包含更完整人类层次结构的边界框标注,每个标注都带有与公平性相关的属性,包括感知的性别和年龄范围。随着人们越来越致力于减少不公平的偏见,作为负责任的人工智能(Responsible AI)研究的一部分,我们希望这些标注能够鼓励已经使用开放图像数据集的研究人员在他们的研究中纳入公平性分析。
我们的团队并不是唯一一个创建数据集来改善机器学习效果的团队,我们还创建了“数据集搜索”(Dataset Search)方法,使得无论来自哪里的用户都可以在我们的帮助下发现新的和有用的数据集。
社区互动:
另一个潜在的问题是,机器学习算法生成的模型有时会产生缺乏证据支持的结果。为了在问题回答、总结和对话中解决这一问题,谷歌开发了一个新的框架来衡量算法结果是否可以归因于特定的来源。我们发布了注释指南,并证明可以使用这项可靠的技术来对候选模型进行评估。
模型的交互式分析和调试仍然是负责任地使用机器学习语言的关键。谷歌对 Language Interpretability Tool 的技术和功能进行了更新。更新包括对图像和表格数据的支持,从 What-If Tool 中继承下来的各种功能,以及 Testing with Concept Activation Vectors 技术对公平性分析的内置支持。机器学习系统的可解释性也是谷歌提出的“负责任的 AI 愿景”(Responsible AI vision)的关键部分。在与 DeepMind 的合作下,谷歌开始了解自我训练的AlphaZero国际象棋系统是如何获取人类的象棋概念的。
谷歌还在努力拓宽“负责任的人工智能”的视角和格局,使其超越西方的局限。一项最近的研究提出在非西方背景下,基于西方机构和基建的算法公平概念并不适用。研究为印度的算法公平研究提供了新方向和新途径。谷歌正在几大洲积极开展调查,以更好地了解人们对人工智能的看法和偏好。西方视角下的算法公平研究倾向于只关注少数几个问题,因此导致很多非西方背景下的算法偏见问题被忽略。为了解决这一差距,我们与密歇根大学(University Of Michigan)合作,开发了一种弱监督薄的自然语言处理(NLP)模型,以便在更广泛的地理文化语境中检测出语言偏见,反映人类在不同的地理环境中对攻击性和非攻击性语言的判断。
此外,谷歌还探索了机器学习在发展中国家的应用,包括开发一个以农民为中心的机器学习研究方案。通过这项工作,我们希望鼓励人工智能领域更多思考如何将机器学习支持的解决方案带给千万小农户,以改善他们的生活和社区。
让整个社会的利益相关方参与到机器学习研发部署的各阶段是谷歌正在努力的方向,这让谷歌牢记什么才是最需要解决的问题。本着这一原则,我们和非营利组织负责人、政府和非政府组织代表以及其他专家之间举行了健康公平研究峰会(Health Equity Research Summit),讨论如何将更多的公平带入整个机器学习的生态系统,使公平原则从最初的解决问题贯穿到结果评估的最后一步。
从社会出发的研究方法让谷歌在机器学习的系统中就思考数字福利和种族平等问题。谷歌希望更多了解非洲裔美国人对 ASR 系统的体验。谷歌也在更广泛地听取公众的意见,以了解机器学习如何在重大生活事件中提供帮助,例如提供家庭照顾。
随着机器学习能力的提高和在许多领域的影响,机器学习中的隐私保护是一个研究重点。沿着这个思路,我们力求解决大型模型中的隐私问题。谷歌既强调训练数据可以从大型模型中提取,也指出了如何在大型模型(例如 BERT)中实现隐私保护。除了上面提到的联邦学习和分析技术,我们还一直在使用其他原则性和实用性的机器学习技术来保护隐私。例如私有聚类、私有个性化、私有矩阵补全、私有加权采样、私有分位数、半空间的私有稳健学习,以及私有 PAC 学习。此外,我们一直在扩展可针对不同应用和威胁模型定制的隐私概念,包括标签隐私和用户与项目级别隐私。
数据集:
谷歌认识到开放数据集对机器学习和相关研究领域的普遍价值,我们继续扩大我们的开源数据集和资源,并在 Google DataSet Search 中增加了开放数据集的全球索引。今年,我们发布了一系列各个研究领域的数据集和工具:

对机器学习和计算机科学来说,这是一个激动人心的时代。通过处理语言、视觉和声音,计算机理解周围的世界并与之互动的能力在不断提高。同时计算机也在不断为人类开拓新疆界贡献力量。前文所述的五个方面正是这漫长旅程中的许多进步的节点!

评论