
基于迁移学习的狗狗分类器
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

你以前听说过深度学习这个词吗? 或者你刚刚开始学习它?
在本文中,我将引导您构建自己的狗狗分类器。在这个项目的最后:
您的代码将接受任何用户提供的图像作为输入
如果一只狗在图像中被检测到,它将提供对该狗狗品种的预测
我会让它尽可能的简单~
实现步骤如下:
步骤0:导入数据集
步骤1:图像预处理
步骤2:选择迁移学习的模式
步骤3:更改预训练模型的分类器
步骤4:编写训练算法
步骤5:训练模型
步骤6:测试模型
步骤7:测试你自己的图片
步骤0:导入数据集
你可以从下列网址下载你自己的数据集:https://www.kaggle.com/c/dog-breed-identification
然后解压缩文件!
由于图像处理在本地机器上需要大量的时间和资源,因此我将使用 colab 的 GPU 来训练我的模型。所以,如果你没有自己的 GPU,也可以切换到 colab 来跟进。
导入必要的库始终是一个良好的开始,下面代码展示了我们训练所需要的库。
#Importing Librariesimport numpy as npimport pandas as pdimport matplotlib.pyplot as pltfrom PIL import Imagefrom PIL import ImageFileimport cv2# importing Pytorch model librariesimport torchimport torchvision.models as modelsimport torchvision.transforms as transformsfrom torchvision import datasetsimport torch.nn as nnimport torch.nn.functional as Fimport torch.optim as optim
在下列代码的圆括号的双引号中输入 dog_images 的路径。
dog_files = np.array(glob("/data/dog_images/*/*/*"))# print number of images in each datasetprint('There are %d total dog images.' % len(dog_files))
Output : There are 8351 total dog images.步骤1:图像预处理
首先,您需要将训练、验证和测试集数据的目录加载到一些变量中。
#Loading images data into the memory and storing them into the variablesdata_dir = '/content/dogImages'train_dir = data_dir + '/train'valid_dir = data_dir + '/valid'test_dir = data_dir + '/test'
然后需要对加载的图像进行一些变换,这就是所谓的数据预处理。
为什么有这个必要?
您的图像必须与网络的输入大小匹配。如果您需要调整图像的大小以匹配网络,那么您可以将数据重新缩放或裁剪到所需的大小
数据增强也使您能够训练网络不受图像数据扭曲的影响。为此,我会随机裁剪和调整图像的大小
数据归一化也是一个重要步骤,确保每个输入参数(本例中为像素)具有类似属性的数据,这使得训练网络时的收敛速度更快
#Applying Data Augmentation and Normalization on imagestrain_transforms = transforms.Compose([transforms.RandomRotation(30),transforms.RandomResizedCrop(224),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406],[0.229, 0.224, 0.225])])valid_transforms = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406],[0.229, 0.224, 0.225])])test_transforms = transforms.Compose([transforms.Resize(255),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406],[0.229, 0.224, 0.225])])
将图像存储到数据加载器中
现在我们需要将训练、验证和测试目录加载到数据加载器中。这将使我们能够将数据分成小批量。
我们将数据以key-value的格式进行存储,这将有助于以后调用它们。
# TODO: Load the datasets with ImageFoldertrain_data = datasets.ImageFolder(train_dir, transform=train_transforms)valid_data = datasets.ImageFolder(valid_dir,transform=valid_transforms)test_data = datasets.ImageFolder(test_dir, transform=test_transforms)# TODO: Using the image datasets and the trainforms, define the dataloaderstrainloader = torch.utils.data.DataLoader(train_data, batch_size=20, shuffle=True)testloader = torch.utils.data.DataLoader(test_data, batch_size=20,shuffle=False)validloader = torch.utils.data.DataLoader(valid_data, batch_size=20,shuffle=False)loaders_transfer = {'train':trainloader,'valid':validloader,'test':testloader}data_transfer = {'train':trainloader}
步骤2:选择迁移学习的模式
什么是预训练模型,我们为什么要使用它?
预训练模型是别人为解决类似问题而创建的模型。
与其从零开始构建模型来解决类似的问题,不如使用经过其他问题训练的模型作为起点
一个预训练模型在应用程序中可能不是100% 准确,但是它节省了重新发明轮子所需的巨大努力
迁移学习可以利用在一个问题上学到的特性,并在一个新的、类似的问题上利用它们。例如,一个已经学会识别小浣熊的模型的特征可能有助于开始训练一个用于识别猫咪的模型
你可以选择几个事先训练过的模特进行模特训练。例如 Densenet,Resnet,VGG 模型。我将使用 VGG-16进行模型训练。
#Loading vgg11 into the variable model_transfermodel_transfer = models.vgg11(pretrained=True)
步骤3:更改预训练模型的分类器
将采取以下步骤来改变预训练分类器:
从以前训练过的模型中取出网络层
冻结它们,以避免在以后的训练回合中破坏它们所包含的任何信息
在冻结层上添加一些新的、可训练的图层。他们将学习在新的数据集上将旧的特性转化为预测
在你的数据集上训练新的网络层
由于特征已经学会了预训练的模型,所以将冻结他们在训练期间对狗狗的形象。我们只会改变分类器的尺寸,只会训练它。
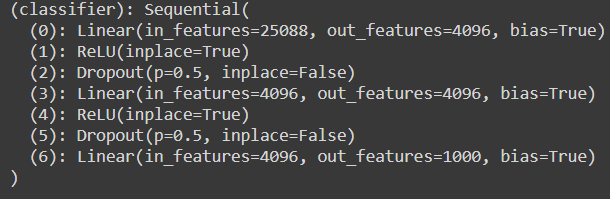
原来的分类器层有25088个维度,但是为了匹配我们的预处理图像大小,我们需要更改为4096。
要在 GPU 上训练模型,我们需要使用以下命令将其移动到 GPU-RAM 上。
#Freezing the parametersfor param in model_transfer.features.parameters():param.requires_grad = False#Changing the classifier layermodel_transfer.classifier[6] = nn.Linear(4096,133,bias=True)#Moving the model to GPU-RAM spaceif use_cuda:model_transfer = model_transfer.cuda()print(model_transfer)
现在我们需要选择一个损失函数和优化器。
利用损失函数计算模型预测值与实际图像的误差。如果你的预测完全错误,你的损失函数将输出更高的数字。如果它们非常好,那么输出的数字就会更低。本文将使用交叉熵损失。
优化器是用来改变神经网络属性的算法或方法,比如权重和学习速度,以减少损失。本文将使用 SGD 优化器。
0.001的学习率对于训练是有好处的,但是你也可以用其他的学习率进行实验。鼓励大家多多尝试不同的参数~
### Loading the Loss-Functioncriterion_transfer = nn.CrossEntropyLoss()### Loading the optimizeroptimizer_transfer = optim.SGD(model_transfer.parameters(), lr=0.001, momentum=0.9)
步骤4:编写训练算法
接下来我们将编写训练函数。
我用它编写了验证代码行。所以在训练模型时,我们会同时得到两种损失。
每次Loss减少时,我也会存储这个模型。这样我就不必在以后每次打开一个新实例时都要训练它。
def train(n_epochs, loaders, model, optimizer, criterion, use_cuda, save_path):"""returns trained model"""# initialize tracker for minimum validation lossvalid_loss_min = np.inf #---> Max Value (As the loss decreases and becomes less than this value it gets saved)for epoch in range(1, n_epochs+1):#Initializing training variablestrain_loss = 0.0valid_loss = 0.0# Start training the modelmodel.train()for batch_idx, (data, target) in enumerate(loaders['train']):# move to GPU's memory space (if available)if use_cuda:data, target = data.cuda(), target.cuda()model.to('cuda')optimizer.zero_grad()output = model(data)loss = criterion(output,target)loss.backward()optimizer.step()train_loss = train_loss + ((1 / (batch_idx + 1)) * (loss.data - train_loss))# validate the model #model.eval()for batch_idx, (data, target) in enumerate(loaders['valid']):accuracy=0# move to GPU's memory space (if available)if use_cuda:data, target = data.cuda(), target.cuda()## Update the validation losslogps = model(data)loss = criterion(logps, target)valid_loss += ((1 / (batch_idx + 1)) * (loss.data - valid_loss))# print both training and validation lossesprint('Epoch: {} \tTraining Loss: {:.6f} \tValidation Loss: {:.6f}'.format(epoch,train_loss,valid_loss))if valid_loss <= valid_loss_min:print('Validation loss decreased ({:.6f} --> {:.6f}). Saving model ...'.format(valid_loss_min,valid_loss))#Saving the modeltorch.save(model.state_dict(), 'model_transfer.pt')valid_loss_min = valid_loss# return the trained modelreturn model
步骤5:训练模型
现在,我将开始通过在函数中提供参数来训练模型。我将训练10个epoch。
# train the modelmodel_transfer = train(10, loaders_transfer, model_transfer, optimizer_transfer, criterion_transfer, use_cuda, 'model_transfer.pt')# load the model that got the best validation accuracymodel_transfer.load_state_dict(torch.load('model_transfer.pt'))
OUTPUT:Epoch: 1 Training Loss: 2.443815 Validation Loss: 0.801671Validation loss decreased (inf --> 0.801671). Saving model ...Epoch: 2 Training Loss: 1.440627 Validation Loss: 0.591050Validation loss decreased (0.801671 --> 0.591050). Saving model ...Epoch: 3 Training Loss: 1.310158 Validation Loss: 0.560950Validation loss decreased (0.591050 --> 0.560950). Saving model ...Epoch: 4 Training Loss: 1.200572 Validation Loss: 0.566340Epoch: 5 Training Loss: 1.160727 Validation Loss: 0.530196Validation loss decreased (0.560950 --> 0.530196). Saving model ...Epoch: 6 Training Loss: 1.088659 Validation Loss: 0.560774Epoch: 7 Training Loss: 1.060936 Validation Loss: 0.503829Validation loss decreased (0.530196 --> 0.503829). Saving model ...Epoch: 8 Training Loss: 1.010044 Validation Loss: 0.500608Validation loss decreased (0.503829 --> 0.500608). Saving model ...Epoch: 9 Training Loss: 1.054875 Validation Loss: 0.497319Validation loss decreased (0.500608 --> 0.497319). Saving model ...Epoch: 10 Training Loss: 1.000547 Validation Loss: 0.545735<All keys matched successfully>
步骤6:测试模型
现在我将在模型以前从未见过的新图像上测试模型,并计算预测的准确性。
def test(loaders, model, criterion, use_cuda):# Initializing the variablestest_loss = 0.correct = 0.total = 0.model.eval() #So that it doesn't change the model parameters during testingfor batch_idx, (data, target) in enumerate(loaders['test']):# move to GPU's memory spave if availableif use_cuda:data, target = data.cuda(), target.cuda()# Passing the data to the model (Forward Pass)output = model(data)loss = criterion(output, target) #Test Losstest_loss = test_loss + ((1 / (batch_idx + 1)) * (loss.data - test_loss))# Output probabilities to the predicted classpred = output.data.max(1, keepdim=True)[1]# Comparing the predicted class to outputcorrect += np.sum(np.squeeze(pred.eq(target.data.view_as(pred))).cpu().numpy())total += data.size(0)print('Test Loss: {:.6f}\n'.format(test_loss))print('\nTest Accuracy: %2d%% (%2d/%2d)' % (100. * correct / total, correct, total))test(loaders_transfer, model_transfer, criterion_transfer, use_cuda)
我已经训练了它10个 epoch,得到了83% 的准确率。并且,得到以下输出!
Output:Test Loss: 0.542430 Test Accuracy: 83% (700/836)
如何提高这个模型的准确性?
通过训练更多的 epoch(比较训练和验证损失)
通过改变学习率(比如0.01,0.05,0.1)
通过改变预训练模型(像稠密网络,但需要更多的训练时间)
通过对图像的进一步预处理
步骤7:测试你自己的图片
现在你已经训练和测试了你的模型。现在,这是最令人兴奋的部分。你能走到这一步真是太好了。
1.将要测试和保存的新图像加载到内存中
#Loading the new image directorydog_files_short = np.array(glob("/content/my_dogs/*"))#Loading the modelmodel_transfer.load_state_dict(torch.load('model_transfer.pt'))
2. 现在我们必须对图像进行预处理,并通过测试我们训练好的模型来预测类
def predict_breed_transfer(img_path):#Preprocessing the input imagetransform = transforms.Compose([transforms.Resize(255),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406],[0.229, 0.224, 0.225])])img = Image.open(img_path)img = transform(img)[:3,:,:].unsqueeze(0)if use_cuda:img = img.cuda()model_transfer.to('cuda')# Passing throught the modelmodel_transfer.eval()# Checking the name of class by passing the indexclass_names = [item[4:].replace("_", " ") for item in data_transfer['train'].dataset.classes]idx = torch.argmax(model_transfer(img))return class_names[idx]output = model_transfer(img)# Probabilities to classpred = output.data.max(1, keepdim=True)[1]return pred
3. 现在,通过将图像路径作为参数传递给这个函数,我们可以预测狗狗的品种。
我已经传递了下面的图像,并得到了下列输出。

Output:Norwegian buhund
总结
这只是一个开始,你可以用这个模型做更多的事情。你可以通过部署它来创建一个应用程序。我尝试从零开始创建自己的模型,没有使用迁移学习,但测试的准确率不超过13% 。你也可以尝试一下,因为这有助于理解概念。

交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~