
不做调参侠,重视数据及处理能力?吴恩达发起的Data-Centric赛事总结!
赛题名称:Data-Centric AI Competition
比赛官网:https://https-deeplearning-ai.github.io/data-centric-comp/
比赛链接:https://worksheets.codalab.org/worksheets/0x7a8721f11e61436e93ac8f76da83f0e6
赛题介绍
在大多数机器学习比赛中,你被要求在给定固定数据集的情况下构建一个高性能模型。然而机器学习已经成熟到可以广泛使用高性能模型架构,而工程数据集的方法却滞后。
以Data-Centric(数据为中心)的AI竞赛颠覆了传统格式,而是要求您在给定固定模型的情况下改进数据集。
赛题任务
该数据集包含约 3000 张手写罗马数字 1-10 的图像。您的任务是通过改进数据集以及进行训练和验证拆分来优化模型性能。
优胜选手分享
Divakar Roy

博客采访:https://www.deeplearning.ai/data-centric-ai-competition-divakar-roy/
我已经设置了不同的算法来根据噪音水平分离噪音。以下是一些具有不同类型噪声的示例案例:
去除噪声后,我们只剩下两组图像,一组干净,一组嘈杂。干净的图像只有前景(字母),而嘈杂的图像只有背景(噪音)。
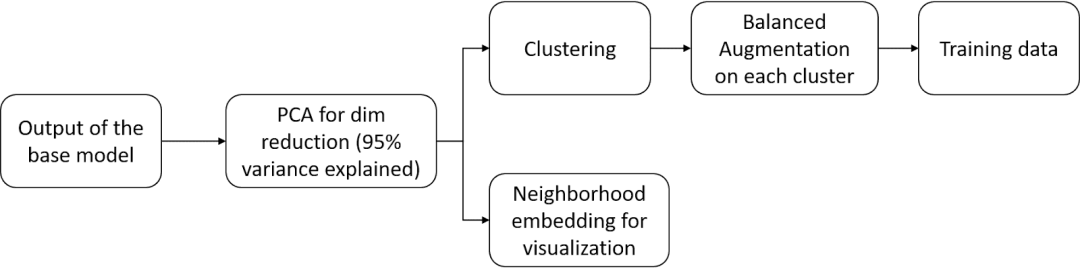
然后我们处理干净的图像以裁剪成字母区域。将裁剪前后清洗后的图像送入 umap 聚类方法研究其模式,如下图:
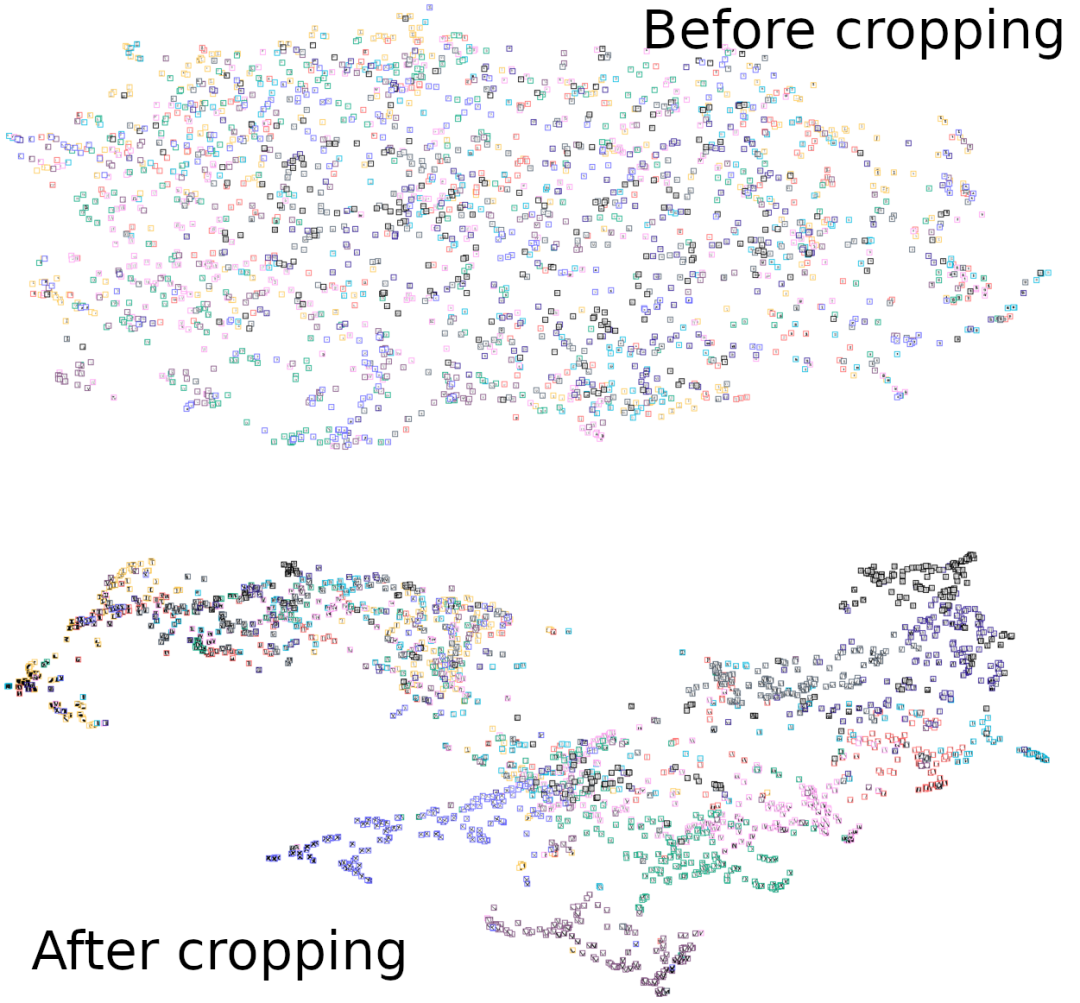
簇根据它们的真实标签着色。可以看出,与没有裁剪相比,聚类更遵循它们的原生标签模式,并且还导致标签之间的决策边界更精确。然后我们处理这些裁剪的图像以准备它们进行增强。
数据增强方法
第一个增强阶段包括相机失真方法,通过将数字的规则 2D 网格映射到倾斜的网格上,我们可以生成独特的形状。
数据质量评估与清理
我们使用 Imagenet预训练的ResNet-15 模型作为特征提取,然后送入t-SNE 聚类算法,以获得可用于各种工作流程的二维数组。
Innotescus

博客采访:https://www.deeplearning.ai/data-centric-ai-competition-innotescus/
我们的方法可以分为两部分:数据标记和平衡数据分布。
识别噪声图像
我们从训练集中删除了噪声图像。这些图像显然不对应于特定类别,并且不利于模型性能。
识别不正确的类
我们纠正了错误标记的数据点。人工注释者容易出错,而拥有系统的 QA 或审查流程有助于识别和消除这些错误。
识别不明确的数据样本
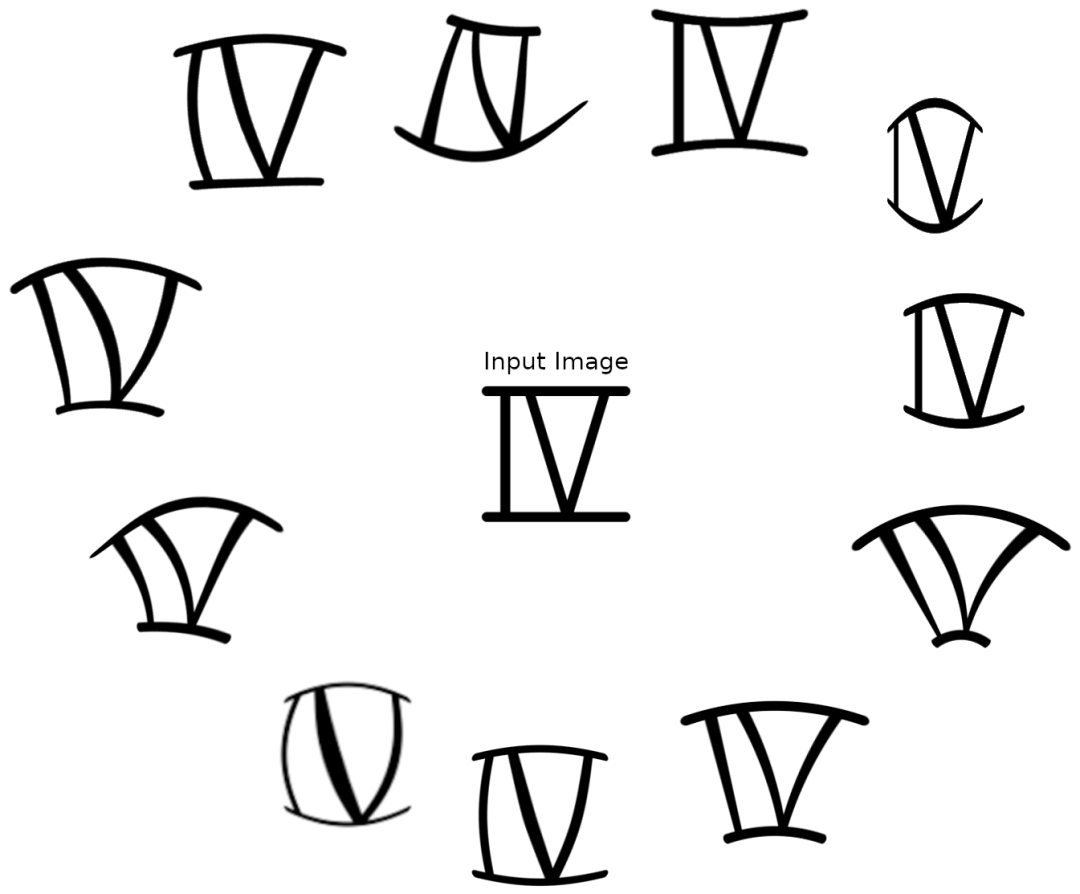
我们为不明确的数据点定义了一致的规则。例如,在下面显示的图像中,如果我们看到两条垂直线(顶行)之间有明显的间隙,即使它们成一定角度,我们也将数据点视为2类。
如果没有可识别的差距,我们将数据点视为第5类(底行)。预先定义的规则帮助我们更客观地减少歧义。
这个三步过程将数据集减少到总共2,228张图像,比提供的数据集减少了22%。仅此一项就在测试集上产生了73.099%的准确率,比基准性能提高了大约9%。
平衡数据分布
当我们在现实世界中收集训练数据时,总是将隐藏的偏差引入我们的训练数据中。有偏见的数据会导致学习不佳。一种解决方案是减少不明确的数据点并确保沿数据集中方差的主要维度保持平衡。
重新平衡训练和测试数据集
真实世界的数据有很多内在的差异。这种差异几乎总是会导致分布不平衡,尤其是在观察特定特征或度量时。当增加时,这些偏见会被放大!
我们在本次比赛中的两个提交中观察到了这一点。我们的方法从“更多数据”转向“更平衡的数据”。
使用嵌入重新平衡子类
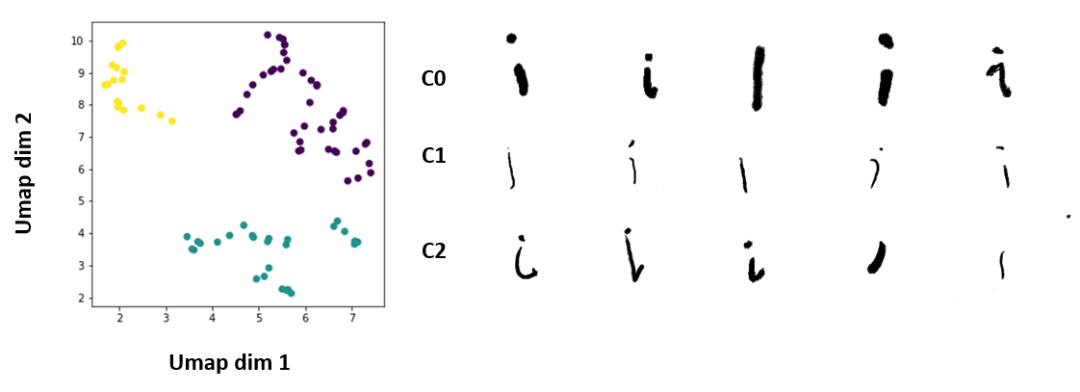
我们观察到的第一个不平衡是每个类中的大小写分布。例如,我们的“清理”数据包含 90 张小写 1 类图像和 194 张大写 1 类图像。
用困难的例子和增强重新平衡边缘情况
在比赛即将结束时,我们观察到验证集中的某些示例一直被错误分类。我们的目标是帮助模型以更高的置信度对这些示例进行分类。
我们认为,这些错误分类是由于我们的训练集中“边缘案例”示例的代表性不足造成的。
Synaptic-AnN

博客采访:https://www.deeplearning.ai/data-centric-ai-competition-synaptic-ann/ 论文分享:https://www.overleaf.com/read/gxdkymkvwkmy
手动数据清洗
与大多数其他竞争对手一样,我们最初的直觉使我们手动筛选数据集并删除任何异常值、嘈杂和模糊的图像。
这将竞争数据集从 2880 张图像减少到 2613 张图像。我们将此数据集称为。
生成更多数据
由于比赛允许我们在训练集和验证集(我们进行了比例95/5 训练-验证划分)中最多提交 10,000 张图像,因此我们招募了朋友和家人来帮助我们编写 4353 个额外的罗马数字。我们称这个数据集为。
我们让多人手写罗马数字的原因是因为我们希望尽可能真实地反映任务的性质。增强以填充其余可能的图像似乎并不是最好的想法,因为我们想确保 ResNet50 泛化良好。
五种数据扩增
对于图像,执行了右上、左上、右下、左下和中心裁剪(图 4)。由于裁剪不当而可能导致错误分类的图像被丢弃。
长宽比标准化:
所有宽高比或高宽比大于 1.75(在某些情况下大于 1.5)的图像都被裁剪成最小尺寸的正方形。这确保了将图像调整为 32 x 32 时的图像质量。
自动增强
我们探索了使用AutoAugment学习增强技术参数的可行性,但由于计算资源有限和数据不足,本文在 SVHN 数据集上的结果用于比赛数据集。
我们观察到Solarize和Invert等增强技术无效,因此将它们从最终的SVHN策略中删除。是因为SVHN 数据集是灰度的,并且与数字表示(外壳板)有关。我们还探索了其他基于 CIFAR10 和 ImageNet 的自动增强策略,但这些策略不如 SVHN 有效。
参与交流
相比较于算法赛,以数据为中心的赛事开始成为新趋势,数据本身以及数据处理的能力在企业中也愈发重要,因此建了相关交流群,对Data-Centric感兴趣的话欢迎加入。延伸阅读: